The code is mostly duplicated. Server::wait_task() has better handling for errors and more retries.
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
The code is mostly duplicated. Server::wait_task() has better handling for errors and more retries.
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
The code is mostly duplicated. Server::wait_task() has better handling for errors and more retries.
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
The code is mostly duplicated. Server::wait_task() has better handling for errors and more retries.
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
The code is mostly duplicated.
Server::wait_task() has better handling for errors and more retries.
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
* Add a call to .failed() for an awaited task
* Use Server::wait_task() instead of Index::wait_task() - it has better
error checking
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
This reduces the build time of the `benchmarks` crate from ~220secs to
45secs (according to `cargo build --timings`) on my dev machine
Additionally I've introduced a parent folder for the Meili related cache
paths - ~/.cache/meili
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
when removing a field from the filterable settings,
this will trigger a reindexing of the negative version of the document,
which removes the document from the searchable as well because the field was considered removed.
It could be used when we want to see the index name in the assertions,
e.g. `movies-[uuid]`
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
Revert the debugging helper that dumped the thread stack traces.
Try with 400 max attempts for the task success/failure (200 secs)
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
This allows to make some more search::filters IT tests using shared
server + unique/shared indices
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
The new Chinese segmenter is splitting words in smaller parts.
The words `小化妆包` was previously seegmented as `小 / 化妆包` and is now segmented as `小 / 化妆 / 包`,
which changes the tests results.
Use shared server + unique indices where possible.
Assert .succeeded() for the waited tasks.
Drop usage of dbg!() in the assertions. It caused noise in the logs
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
* Use shared index where possible.
* Call .succeeded/.failed when waiting for a task.
* Use newer format_args syntax
* Do not use fully qualified name for meili_snap:: functions. The
functions are already imported in scope
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
... because a Shared one could see indices created by other tests
2. List at least 1000 indices to make sure we get the newly created ones
in list_multiple_indexes()
Signed-off-by: Martin Tzvetanov Grigorov <mgrigorov@apache.org>
Won't work in integration tests and consequently all threads would be
used. To remedy this we make explicit `max_threads=Some(1)` in the
IndexerConfig::default
5436: Update mini-dashboard to v0.2.19 version r=Kerollmops a=curquiza
Fixes mini dashboard to prevent the panel from popping up every time
Fixed by `@mdubus` 👍
Co-authored-by: curquiza <clementine@meilisearch.com>
5426: Bump zip from 2.2.2 to 2.3.0 r=Kerollmops a=dependabot[bot]
Bumps [zip](https://github.com/zip-rs/zip2) from 2.2.2 to 2.3.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/zip-rs/zip2/releases">zip's releases</a>.</em></p>
<blockquote>
<h2>v2.3.0</h2>
<h3><!-- raw HTML omitted -->🚀 Features</h3>
<ul>
<li>Add support for NTFS extra field (<a href="https://redirect.github.com/zip-rs/zip2/pull/279">#279</a>)</li>
</ul>
<h3><!-- raw HTML omitted -->🐛 Bug Fixes</h3>
<ul>
<li><em>(test)</em> Conditionalize a zip64 doctest (<a href="https://redirect.github.com/zip-rs/zip2/pull/308">#308</a>)</li>
<li>fix failing tests, remove symlink loop check</li>
<li>Canonicalize output path to avoid false negatives</li>
<li>Symlink handling in stream extraction</li>
<li>Canonicalize output paths and symlink targets, and ensure they descend from the destination</li>
</ul>
<h3><!-- raw HTML omitted -->⚙️ Miscellaneous Tasks</h3>
<ul>
<li>Fix clippy and cargo fmt warnings (<a href="https://redirect.github.com/zip-rs/zip2/pull/310">#310</a>)</li>
</ul>
<h2>v2.2.3</h2>
<h3><!-- raw HTML omitted -->🚜 Refactor</h3>
<ul>
<li>Change the inner structure of <code>DateTime</code> (<a href="https://redirect.github.com/zip-rs/zip2/issues/267">#267</a>)</li>
</ul>
<h3><!-- raw HTML omitted -->⚙️ Miscellaneous Tasks</h3>
<ul>
<li>cargo fix --edition</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/zip-rs/zip2/blob/master/CHANGELOG.md">zip's changelog</a>.</em></p>
<blockquote>
<h2><a href="https://github.com/zip-rs/zip2/compare/v2.2.3...v2.3.0">2.3.0</a> - 2025-03-16</h2>
<h3><!-- raw HTML omitted -->🚀 Features</h3>
<ul>
<li>Add support for NTFS extra field (<a href="https://redirect.github.com/zip-rs/zip2/pull/279">#279</a>)</li>
</ul>
<h3><!-- raw HTML omitted -->🐛 Bug Fixes</h3>
<ul>
<li><em>(test)</em> Conditionalize a zip64 doctest (<a href="https://redirect.github.com/zip-rs/zip2/pull/308">#308</a>)</li>
<li>fix failing tests, remove symlink loop check</li>
<li>Canonicalize output path to avoid false negatives</li>
<li>Symlink handling in stream extraction</li>
<li>Canonicalize output paths and symlink targets, and ensure they descend from the destination</li>
</ul>
<h3><!-- raw HTML omitted -->⚙️ Miscellaneous Tasks</h3>
<ul>
<li>Fix clippy and cargo fmt warnings (<a href="https://redirect.github.com/zip-rs/zip2/pull/310">#310</a>)</li>
</ul>
<h2><a href="https://github.com/zip-rs/zip2/compare/v2.2.2...v2.2.3">2.2.3</a> - 2025-02-26</h2>
<h3><!-- raw HTML omitted -->🚜 Refactor</h3>
<ul>
<li>Change the inner structure of <code>DateTime</code> (<a href="https://redirect.github.com/zip-rs/zip2/issues/267">#267</a>)</li>
</ul>
<h3><!-- raw HTML omitted -->⚙️ Miscellaneous Tasks</h3>
<ul>
<li>cargo fix --edition</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="6eab5f5cc6"><code>6eab5f5</code></a> chore: release v2.3.0 (<a href="https://redirect.github.com/zip-rs/zip2/issues/300">#300</a>)</li>
<li><a href="e4aee2050f"><code>e4aee20</code></a> implement <code>ZipFile::options</code> + refactor options normalization (<a href="https://redirect.github.com/zip-rs/zip2/issues/305">#305</a>)</li>
<li><a href="ea8a7bba24"><code>ea8a7bb</code></a> fix(test): Conditionalize a zip64 doctest (<a href="https://redirect.github.com/zip-rs/zip2/issues/308">#308</a>)</li>
<li><a href="365c81a39f"><code>365c81a</code></a> Use <code>xz2</code> crate instead of a custom implementation (<a href="https://redirect.github.com/zip-rs/zip2/issues/306">#306</a>)</li>
<li><a href="ae94b3452b"><code>ae94b34</code></a> chore: Fix clippy and cargo fmt warnings (<a href="https://redirect.github.com/zip-rs/zip2/issues/310">#310</a>)</li>
<li><a href="a2e062f370"><code>a2e062f</code></a> Merge commit from fork</li>
<li><a href="0199ac2cb8"><code>0199ac2</code></a> Simplify handling for symlink targets</li>
<li><a href="977bb9479d"><code>977bb94</code></a> fix failing tests, remove symlink loop check</li>
<li><a href="3cb29e70d1"><code>3cb29e7</code></a> Partial fix for tests</li>
<li><a href="2182b07686"><code>2182b07</code></a> Refactor</li>
<li>Additional commits viewable in <a href="https://github.com/zip-rs/zip2/compare/v2.2.2...v2.3.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
5422: Add more progress levels to measure merging r=Kerollmops a=Kerollmops
I found out that Meilisearch was not correctly reporting the long indexing times in the progress and that a lot of time was spent on extracting words with all documents already extracted. The reason was that there was no step to report merging the cache and sending the entries to write to the writer thread. This PR adds these entries to the progress.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5421: Accept total batch size in human size r=irevoire a=Kerollmops
This PR fixes the new `experimental-limit-batched-tasks-total-size` to accept human-defined sizes in bytes.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5420: Add support for the progress API of arroy r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5419
## What does this PR do?
- Convert the arroy progress to the meilisearch progress
- Use the new arroy closure to support the progress of arroy
Co-authored-by: Tamo <tamo@meilisearch.com>
5418: Cache embeddings in search r=Kerollmops a=dureuill
# Pull Request
## Related issue
TBD
## What does this PR do?
- Adds a cache for embeddings produced in search
- The cache is disabled by default, and can be enabled following the instructions [here](https://github.com/orgs/meilisearch/discussions/818).
- Had to accommodate the `timeout` test for openai that uses a mock that simulates a timeout on subsequent responses: since the test was reusing the same query, the cache would kick-in and no request would be made to the mock, meaning no timeout any longer and so a failing test 😅
- `Embedder::embed_search` now accepts a reference instead of an owned `String`.
## Manual testing
- I created 4 indexes on a fresh DB with the same settings (one embedder from openai)
- I sent 1/4 of movies.json to each index
- I sent a federated search request against all 4 indexes, with the same query for each index, using the embedder of each index.
Results:
- The first call took 400ms to 1s. Before this change, it took in the 3s range.
- Any repeated call with the same query took in the range of 25ms.
- Looking at the details at trace log level, I can see that the first index that needs the embedding is taking most of the 400ms in `embed_one`. The other indexes report that the query text is found in the cache and they each take a few µs.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
5369: exhaustive facet search r=ManyTheFish a=ManyTheFish
Fixes#5403
This PR adds an `exhaustiveFacetCount` field to the `/facet-search` API allowing the end-user to have a better facet count when having a distinct attribute set in the index settings.
# Usage
`POST /index/:index_uid/facet-search`
**Body:**
```json
{
"facetQuery": "blob",
"facetName": "genres",
"q": "",
"exhaustiveFacetCount": true
}
```
# Prototype Docker images
```sh
$ docker pull getmeili/meilisearch:prototype-exhaustive-facet-search-00
```
Co-authored-by: ManyTheFish <many@meilisearch.com>
5398: Bump ring from 0.17.8 to 0.17.13 r=Kerollmops a=dependabot[bot]
Bumps [ring](https://github.com/briansmith/ring) from 0.17.8 to 0.17.13.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/briansmith/ring/blob/main/RELEASES.md">ring's changelog</a>.</em></p>
<blockquote>
<h1>Version 0.17.13 (2025-03-06)</h1>
<p>Increased MSRV to 1.66.0 to avoid bugs in earlier versions so that we can
safely use <code>core::arch::x86_64::__cpuid</code> and <code>core::arch::x86::__cpuid</code> from
Rust in future releases.</p>
<p>AVX2-based VAES-CLMUL implementation. This will be a notable performance
improvement for most newish x86-64 systems. This will likely raise the minimum
binutils version supported for very old Linux distros.</p>
<h1>Version 0.17.12 (2025-03-05)</h1>
<p>Bug fix: <a href="https://redirect.github.com/briansmith/ring/pull/2447">briansmith/ring#2447</a> for denial of service (DoS).</p>
<ul>
<li>
<p>Fixes a panic in <code>ring::aead::quic::HeaderProtectionKey::new_mask()</code> when
integer overflow checking is enabled. In the QUIC protocol, an attacker can
induce this panic by sending a specially-crafted packet. Even unintentionally
it is likely to occur in 1 out of every 2**32 packets sent and/or received.</p>
</li>
<li>
<p>Fixes a panic on 64-bit targets in <code>ring::aead::{AES_128_GCM, AES_256_GCM}</code>
when overflow checking is enabled, when encrypting/decrypting approximately
68,719,476,700 bytes (about 64 gigabytes) of data in a single chunk. Protocols
like TLS and SSH are not affected by this because those protocols break large
amounts of data into small chunks. Similarly, most applications will not
attempt to encrypt/decrypt 64GB of data in one chunk.</p>
</li>
</ul>
<p>Overflow checking is not enabled in release mode by default, but
<code>RUSTFLAGS="-C overflow-checks"</code> or <code>overflow-checks = true</code> in the Cargo.toml
profile can override this. Overflow checking is usually enabled by default in
debug mode.</p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/briansmith/ring/commits">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
5413: Make sure to delete useless prefixes r=ManyTheFish a=Kerollmops
We discovered a bug where the new indexer was still writing empty roaring bitmaps instead of deleting the prefix entry from the prefix database.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5254: Granular Filterable attribute settings r=ManyTheFish a=ManyTheFish
# Related
**Issue:** https://github.com/meilisearch/meilisearch/issues/5163
**PRD:** https://meilisearch.notion.site/API-usage-Settings-to-opt-out-indexing-features-filterableAttributes-1764b06b651f80aba8bdf359b2df3ca8
# Summary
Change the `filterableAttributes` settings to let the user choose which facet feature he wants to activate or not.
Deactivating a feature will avoid some database computation in the indexing process and save time and disk size.
# Example
`PATCH /indexes/:index_uid/settings`
```json
{
"filterableAttributes": [
{
"patterns": [
"cattos",
"doggos.age"
],
"features": {
"facetSearch": false,
"filter": {
"equality": true,
"comparison": false
}
}
}
]
}
```
# Impact on the codebase
- Settings API:
- `/settings`
- `/settings/filterable-attributes`
- OpenAPI
- may impact the LocalizedAttributesRules due to the AttributePatterns factorization
- Database:
- Filterable attributes format changed
- Faceted field_ids are no more stored in the database
- FieldIdsMap has no more unexisting fields
- Search:
- Search using filters
- Facet search
- `Attributes` ranking rule
- Distinct attribute
- Facet distribution
- Settings reindexing:
- searchable
- facet
- vector
- geo
- Document indexing:
- searchable
- facet
- vector
- geo
- Dump import
# Note for the reviewers
The changes are huge and have been split in different commits with a dedicated explanation, I suggest reviewing the commit 1by1
Co-authored-by: ManyTheFish <many@meilisearch.com>
5401: Make composite embedders an experimental feature r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#5343
## What does this PR do?
- Introduce new `compositeEmbedders` experimental feature
- Guard `source = "composite"` and `searchEmbedder`, `indexingEmbedder` behind enabling the feature.
- Update tests accordingly
## Dumpless upgrade
- Adding an experimental feature is never a breaking change
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Test suite / Tests on ubuntu-22.04 (push) Failing after 12s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test with Ollama (push) Failing after 8s
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Run Clippy (push) Successful in 7m1s
Test suite / Run Rustfmt (push) Successful in 2m44s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m40s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5371: Composite embedders r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#5343
## What does this PR do?
- Implement [public usage](https://www.notion.so/meilisearch/Composite-embedder-usage-14a4b06b651f81859dc3df21e8cd02a0)
- Refactor the way we check if a parameter is mandatory/allowed/disallowed for a given source
- Take the "nesting context" into account for computer if a parameter is mandatory/allowed/disallowed
- Add tests checking all parameters with all sources, and made sure the results didn't change compared with v1.13
## Dumpless Upgrade
- This adds a new value for an existing parameter => compatible without change
- This adds new optional parameters => compatible without change
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
**Changes:**
- Add a new test playing with filterable attributes rules priority
- Optimize the faceted field selector avoiding to match false positives
Publish binaries to GitHub release / Check the version validity (push) Failing after 57s
Publish binaries to GitHub release / Publish binary for Linux (push) Has been skipped
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Has been skipped
Publish binaries to GitHub release / Publish binary for macos-13 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for windows-2022 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Has been cancelled
Test suite / Tests on ubuntu-22.04 (push) Failing after 6s
Test suite / Tests almost all features (push) Failing after 6s
Test suite / Test with Ollama (push) Failing after 7s
Test suite / Test disabled tokenization (push) Failing after 5s
Test suite / Run tests in debug (push) Failing after 6s
Test suite / Run Clippy (push) Failing after 6s
Test suite / Run Rustfmt (push) Failing after 6s
SDKs tests / define-docker-image (push) Failing after 15s
SDKs tests / .NET SDK tests (push) Has been skipped
SDKs tests / Dart SDK tests (push) Has been skipped
SDKs tests / Go SDK tests (push) Has been skipped
SDKs tests / Java SDK tests (push) Has been skipped
SDKs tests / JS SDK tests (push) Has been skipped
SDKs tests / PHP SDK tests (push) Has been skipped
SDKs tests / Python SDK tests (push) Has been skipped
SDKs tests / Ruby SDK tests (push) Has been skipped
SDKs tests / Rust SDK tests (push) Has been skipped
SDKs tests / Swift SDK tests (push) Has been skipped
SDKs tests / meilisearch-js-plugins tests (push) Has been skipped
SDKs tests / meilisearch-rails tests (push) Has been skipped
SDKs tests / meilisearch-symfony tests (push) Has been skipped
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
Publish images to Docker Hub / docker (push) Has been cancelled
5383: Skip a snapshot test on Windows r=dureuill a=Kerollmops
This PR skips the `perform_on_demand_snapshot` test on Windows, which is very flaky on this platform. Note that we keep running it on macOS and Ubuntu.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Run the indexing fuzzer / Setup the action (push) Failing after 5s
Publish binaries to GitHub release / Check the version validity (push) Successful in 9s
Publish binaries to GitHub release / Publish binary for Linux (push) Failing after 9s
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Failing after 10s
Test suite / Tests on ubuntu-22.04 (push) Failing after 17s
Test suite / Tests almost all features (push) Failing after 11s
Test suite / Test with Ollama (push) Failing after 17s
Test suite / Test disabled tokenization (push) Failing after 12s
Test suite / Run tests in debug (push) Failing after 13s
Test suite / Run Rustfmt (push) Successful in 3m43s
Test suite / Run Clippy (push) Successful in 9m23s
Publish binaries to GitHub release / Publish binary for macos-13 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for windows-2022 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Has been cancelled
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5365: Mention openAPI in CONTRIBUTING.md r=Kerollmops a=irevoire
I only referred to other documents to be sure the process is written only once and won’t get out of sync.
Co-authored-by: Tamo <tamo@meilisearch.com>
**Changes:**
Introduce a test_settings_documents_indexing_swapping_and_search function that run the test twice:
1) by indexing the settings before the documents then running the test
2) by indexing the documents before the settings then running the test
This helps to ensure that their is no bug coming from one or the other indexer.
**Reason:**
Because the filterable attributes are patterns now,
the fieldIdMap will only register the fields that exists in at least one document.
if a field doesn't exist in any document, it will not be registered even if it has been specified in the filterable fields.
**Changes:**
The searchable database extraction is now relying on the AttributePatterns and FieldIdMapWithMetadata to match the field to extract.
Remove the SearchableExtractor trait to make the code less complex.
**Impact:**
- Document Addition/modification searchable indexing
- Document deletion searchable indexing
**Changes:**
The Documents changes now take a selector closure instead of a list of field to match the field to extract.
The seek_leaf_values_in_object function now uses a selector closure of a list of field to match the field to extract
The facet database extraction is now relying on the FilterableAttributesRule to match the field to extract.
The facet-search database extraction is now relying on the FieldIdMapWithMetadata to select the field to index.
The facet level database extraction is now relying on the FieldIdMapWithMetadata to select the field to index.
**Important:**
Because the filterable attributes are patterns now,
the fieldIdMap will only register the fields that exists in at least one document.
if a field doesn't exist in any document, it will not be registered even if it has been specified in the filterable fields.
**Impact:**
- Document Addition/modification facet indexing
- Document deletion facet indexing
**Changes:**
The transform structure is now relying on FieldIdMapWithMetadata and AttributePatterns to prepare
the obkv documents during a settings reindexing.
The InnerIndexSettingsDiff and InnerIndexSettings structs are now relying on FieldIdMapWithMetadata, FilterableAttributesRule and AttributePatterns to define the field and the databases that should be reindexed.
The faceted_fields_ids, localized_searchable_fields_ids and localized_faceted_fields_ids have been removed in favor of the FieldIdMapWithMetadata.
We are now relying on the FieldIdMapWithMetadata to retain vectors_fids from the facets and the searchables.
The searchable database computing is now relying on the FieldIdMapWithMetadata to know if a field is searchable and retrieve the locales.
The facet database computing is now relying on the FieldIdMapWithMetadata to compute the facet databases, the facet-search and retrieve the locales.
The facet level database computing is now relying on the FieldIdMapWithMetadata and the facet level database are cleared depending on the settings differences (clear_facet_levels_based_on_settings_diff).
The vector point extraction uses the FieldIdMapWithMetadata instead of FieldsIdsMapWithMetadata.
**Impact:**
- Dump import
- Settings update
**Changes:**
The building of the Attributes ranking rule graph was comparing fieldids with weights
which doesn't make sense and may be bug prone, we are now comparing fieldids with fieldids.
**Impact:**
- search: Attribute ranking rule
**Changes:**
The FieldIdMapWithMetadata structure now stores more information about fields.
The metadata_for_field function computes all the needed information relying on the user provided data instead of the enriched data (searchable/sortable)
which may solve an indexing bug on sortable attributes that was not matching the nested fields.
The FieldIdMapWithMetadata structure was duplicated in the embeddings as FieldsIdsMapWithMetadata,
so the FieldsIdsMapWithMetadata has been removed in favor of FieldIdMapWithMetadata.
The Facet distribution is now relying on the FieldIdMapWithMetadata with metadata to match is a field can be faceted.
**Impact:**
- searchable attributes matching
- searchable attributes weight computation
- sortable attributes matching
- faceted fields matching
- prompt computing
- facet distribution
**Changes:**
The search filters are now using the FilterableAttributesFeatures from the FilterableAttributesRules to know if a field is filterable.
Moreover, the FilterableAttributesFeatures is more precise and an error will be returned if an operator is used on a field that doesn't have the related feature.
The facet-search is now checking if the feature is allowed in the FilterableAttributesFeatures and an error will be returned if the field doesn't have the related feature.
**Impact:**
- facet-search is now relying on AttributePatterns to match the locales
- search using filters is now relying on FilterableAttributesFeatures
- distinct attribute is now relying on FilterableAttributesRules
**Changes:**
The filterableAttributes type has been changed from a `BTreeSet<String>` to a `Vec<FilterableAttributesRule>`,
Which is a list of rules defining patterns to match the documents' fields and a set of feature to apply on the matching fields.
The rule order given by the user is now an important information, the features applied on a filterable field will be chosen based on the rule order as we do for the LocalizedAttributesRules.
This means that the list will not be reordered anymore and will keep the user defined order,
moreover, if there are any duplicates, they will not be de-duplicated anymore.
**Impact:**
- Settings API
- the database format of the filterable attributes changed
- may impact the LocalizedAttributesRules due to the AttributePatterns factorization
- OpenAPI generator
Look for flaky tests / flaky (push) Failing after 1s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Publish binaries to GitHub release / Check the version validity (push) Failing after 5s
Test suite / Tests almost all features (push) Failing after 13s
Test suite / Tests on ubuntu-22.04 (push) Failing after 19s
Test suite / Test with Ollama (push) Failing after 7s
Test suite / Test disabled tokenization (push) Failing after 10s
Test suite / Run tests in debug (push) Failing after 15s
Test suite / Run Rustfmt (push) Failing after 16s
Test suite / Run Clippy (push) Successful in 9m39s
SDKs tests / define-docker-image (push) Failing after 5s
SDKs tests / .NET SDK tests (push) Has been skipped
SDKs tests / Dart SDK tests (push) Has been skipped
SDKs tests / Go SDK tests (push) Has been skipped
SDKs tests / Java SDK tests (push) Has been skipped
SDKs tests / JS SDK tests (push) Has been skipped
SDKs tests / PHP SDK tests (push) Has been skipped
SDKs tests / Python SDK tests (push) Has been skipped
SDKs tests / Ruby SDK tests (push) Has been skipped
SDKs tests / Rust SDK tests (push) Has been skipped
SDKs tests / Swift SDK tests (push) Has been skipped
SDKs tests / meilisearch-js-plugins tests (push) Has been skipped
SDKs tests / meilisearch-rails tests (push) Has been skipped
SDKs tests / meilisearch-symfony tests (push) Has been skipped
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5355: Support fetching the pooling method from the model configuration r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#5354
## What does this PR do?
- Fetches the pooling configuration from the model repository
- Use a pooling method that depends on the pooling configuration of that model.
- Allow overriding the pooling method with a new huggingFace embedder parameter `pooling`
- for backward-compatibility with Meilisearch v1.13
- for compatibility with embedders that exhibit the same behavior as Meilisearch v1.13
- Handle the default value of that new parameter
- for compatibility, when importing a db/a dump, it should be set to `forceMean`
- when (re)set from the settings for an embedder, it should be set to `useModel`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 1s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Test with Ollama (push) Failing after 15s
Test suite / Run tests in debug (push) Failing after 15s
Test suite / Run Rustfmt (push) Successful in 2m20s
Test suite / Run Clippy (push) Failing after 6m46s
Run the indexing fuzzer / Setup the action (push) Failing after 7m0s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5364: Rename `callTrace` into `progressTrace` r=Kerollmops a=Kerollmops
Rename the `callTrace` field into a `progressTrace`.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Look for flaky tests / flaky (push) Failing after 19s
SDKs tests / define-docker-image (push) Failing after 5s
SDKs tests / .NET SDK tests (push) Has been skipped
SDKs tests / Dart SDK tests (push) Has been skipped
SDKs tests / Go SDK tests (push) Has been skipped
SDKs tests / Java SDK tests (push) Has been skipped
SDKs tests / JS SDK tests (push) Has been skipped
SDKs tests / PHP SDK tests (push) Has been skipped
SDKs tests / Python SDK tests (push) Has been skipped
SDKs tests / Ruby SDK tests (push) Has been skipped
SDKs tests / Rust SDK tests (push) Has been skipped
SDKs tests / Swift SDK tests (push) Has been skipped
SDKs tests / meilisearch-js-plugins tests (push) Has been skipped
SDKs tests / meilisearch-rails tests (push) Has been skipped
SDKs tests / meilisearch-symfony tests (push) Has been skipped
Publish binaries to GitHub release / Check the version validity (push) Successful in 9s
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Failing after 2s
Publish binaries to GitHub release / Publish binary for Linux (push) Failing after 12s
Publish binaries to GitHub release / Publish binary for macos-13 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for windows-2022 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Has been cancelled
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Test with Ollama (push) Failing after 7s
Test suite / Test disabled tokenization (push) Failing after 11s
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Run Clippy (push) Failing after 17s
Test suite / Run Rustfmt (push) Successful in 1m51s
Test suite / Tests almost all features (push) Failing after 7m7s
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5351: Bring back v1.13.0 changes into main r=irevoire a=Kerollmops
This PR brings back the changes made in v1.13 into the main branch.
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Clémentine <clementine@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 1s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 14s
Test suite / Run Rustfmt (push) Successful in 1m54s
Test suite / Run Clippy (push) Failing after 6m49s
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5342: Fix workload sha r=dureuill a=ManyTheFish
The dataset shasum was wrong for some workloads making the `/bench workloads/*.json` crash
Co-authored-by: ManyTheFish <many@meilisearch.com>
5339: Add back timeout from v1.11.3 r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#5337
## What does this PR do?
- Fix regression compared with v1.11 by reintroducing the 30s timeout on all REST API calls.
Thanks to `@migueltarga` for reporting the issue
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
5336: Meilitool Hair Dryer r=dureuill a=Kerollmops
This pull request introduces a new subcommand to hair dry a specific part of specific indexes. It is useful when [the memory-mapped pages are not hot in the cache](https://arc.net/l/quote/ixhcdwcq) and must be. Hair drying those interesting pages makes the search requests using the vector store much faster.
The previous technique used the "cat method," which consists of reading the whole LMDB data file and pipping it into the null file descriptor. By doing that, the whole LMDB data file becomes hot in the cache. However, when the database is large, at least 30% of it is free, and unused pages and many other pages don't need to be hot, e.g., raw JSON documents or uninteresting parts of the inverted index.
This new subcommand reads all the Arroy pages of a given index to make them hot, and only those. More coming...
The current algorithm is single-threaded and takes a lot of time. I am in the process of multithreading it. This is the time it takes to hair dry a 305GiB database with a single thread.
```
real 21m51.054s
user 0m3.155s
sys 0m19.393s
```
## To Do
- [ ] (optional) Do the reads in parallel.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Test with Ollama (push) Failing after 5s
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Run tests in debug (push) Failing after 0s
Test suite / Run Rustfmt (push) Failing after 7s
Test suite / Run Clippy (push) Successful in 7m29s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m25s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5324: Mention utoipa in sprint issues r=curquiza a=irevoire
Update the sprint-issue template to mention the openAPI file and utoipa.
Let me know if something is not clear or missing
Co-authored-by: Tamo <tamo@meilisearch.com>
5149: Ensure the settings routes are now configurated when a new field is added to the Settings struct r=curquiza a=MichaScant
# Pull Request
## Related issue
Fixes#5126
## What does this PR do?
Ensures the settings routes are properly configured before a new field is added to the settings structure. Changes were made based on what was proposed in the original issue, any new field for settings struct is added in the [make_settings_route! macro list](6298db5bea/crates/meilisearch/src/routes/indexes/settings.rs (L182-L403))
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: michascant <89426143+MichaScant@users.noreply.github.com>
5332: Fix geo update r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#5331
## What does this PR do?
- use the merged version that contains all fields instead of the updated version that contains only updated fields
- add test that detects the problem
- As it is the second time that `changes.updated` is causing a bug, I'm changing its name to `only_changed_fields`, hopefully better communicating that old fields are not there
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests almost all features (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 15s
Test suite / Run Clippy (push) Failing after 11s
Test suite / Run tests in debug (push) Failing after 34s
Test suite / Run Rustfmt (push) Successful in 1m32s
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5326: Expose a route to get the file content associated with a task r=Kerollmops a=Kerollmops
This PR exposes a new `/tasks/{taskUid}/documents` route, exposing the update file associated with a task.
## To Do
- [x] (optional) Change the route to `/tasks/{taskUid}/documents` `@dureuill.`
- [x] Update Open API example.
- [x] Create [an Experimental Feature Discussion](https://github.com/orgs/meilisearch/discussions/808).
- [x] Make this route experimental and enable it via the experimental route.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 2s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 16s
Test suite / Run Clippy (push) Failing after 12s
Test suite / Run Rustfmt (push) Failing after 32s
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
5316: Fix the dumpless upgrade corruption r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5280
## What does this PR do?
- Add a test that ensure we write the version in the index-scheduler even if we have a bug while writing the VERSION file
- Do what was described in the issue
Co-authored-by: Tamo <tamo@meilisearch.com>
Look for flaky tests / flaky (push) Failing after 13s
SDKs tests / define-docker-image (push) Failing after 7m9s
SDKs tests / .NET SDK tests (push) Has been skipped
SDKs tests / Dart SDK tests (push) Has been skipped
SDKs tests / Go SDK tests (push) Has been skipped
SDKs tests / Java SDK tests (push) Has been skipped
SDKs tests / JS SDK tests (push) Has been skipped
SDKs tests / PHP SDK tests (push) Has been skipped
SDKs tests / Python SDK tests (push) Has been skipped
SDKs tests / Ruby SDK tests (push) Has been skipped
SDKs tests / Rust SDK tests (push) Has been skipped
SDKs tests / Swift SDK tests (push) Has been skipped
SDKs tests / meilisearch-js-plugins tests (push) Has been skipped
SDKs tests / meilisearch-rails tests (push) Has been skipped
SDKs tests / meilisearch-symfony tests (push) Has been skipped
Publish binaries to GitHub release / Check the version validity (push) Successful in 12s
Publish binaries to GitHub release / Publish binary for Linux (push) Failing after 16s
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Failing after 19s
Test suite / Tests almost all features (push) Failing after 1s
Test suite / Test with Ollama (push) Failing after 7s
Test suite / Tests on ubuntu-20.04 (push) Failing after 15s
Test suite / Test disabled tokenization (push) Failing after 9s
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Run Rustfmt (push) Failing after 9s
Test suite / Run Clippy (push) Failing after 18s
Test suite / Tests on macos-13 (push) Has been cancelled
Test suite / Tests on windows-2022 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for macos-13 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for windows-2022 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Has been cancelled
5308: Ollama Integration Tests r=dureuill a=Kerollmops
This PR improves test coverage of #4757 by providing a new CI to test the Ollama setup with Ollama.
## To Do
- [x] Clean up the commits
- [x] Feature gate the Ollama tests and run them only in the CI
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
5322: Make sure arroy is using the rayon thread-pool r=dureuill a=Kerollmops
This PR fixes#5249 by ensuring arroy uses the rayon thread pool.
Co-authored-by: Kerollmops <clement@meilisearch.com>
4970: Create a new export documents meilitool subcommand r=dureuill a=Kerollmops
This subcommand can be useful for extracting documents from an existing database.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5314: Activate used database size r=irevoire a=ManyTheFish
# Pull Request
make the `/stats` route return the `usedDatabaseSize` corresponding to the size used to store the "real" data in the database and not the disk size used by LMDB
Co-authored-by: ManyTheFish <many@meilisearch.com>
5312: Send the OSS analytics once per day instead of once per hour r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5311
## What does this PR do?
- If the instance is OSS => we send the analytics once every day
- If the instance is on the meilisearch cloud => we send the analytics every hour
Co-authored-by: Tamo <tamo@meilisearch.com>
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 13s
Test suite / Run tests in debug (push) Failing after 13s
Test suite / Run Clippy (push) Failing after 19s
Test suite / Tests on windows-2022 (push) Failing after 48s
Test suite / Run Rustfmt (push) Successful in 1m28s
Test suite / Tests on macos-13 (push) Has been cancelled
5288: Improve AI logging r=dureuill a=Kerollmops
This PR fixes#5285 and brings the changes from #5233 to simplify debugging indexation and search performance issues related to AI. The following texts can be found in the logs to debug and understand performance issues:
- `embed_one: search` represents the time we spent waiting for the embedding generation, i.e., OpenAI, local HuggingFace, Ollama.
- `filtered_universe: search::universe` the time spent filtering the documents.
- ~`next_bucket: search::vector_sort` is the time spent finding the nearest neighbors (ANNs) in the vector store (arroy), locally~ was being triggered too many times.
- `indexing::vectors` is the time arroy spends indexing the new vectors for a batch.
- `documents::extract vectors` and `documents::merge vectors` to see the time spent generating and writing the embeddings.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 2s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 2s
Test suite / Tests on windows-2022 (push) Failing after 24s
Test suite / Run Rustfmt (push) Successful in 1m33s
Test suite / Run Clippy (push) Successful in 6m20s
Test suite / Tests on macos-13 (push) Has been cancelled
5306: Fix internal error when passing `documentTemplateMaxBytes` to a source that doesn't support it r=ManyTheFish a=dureuill
# Pull Request
## Related issue
Fixes#5305
## What does this PR do?
- add `DOCUMENT_TEMPLATE_MAX_BYTES` to `allowed_sources_for_field` and `allowed_fields_for_source` to prevent a panic
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 1s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 14s
Test suite / Tests on windows-2022 (push) Failing after 24s
Test suite / Run Clippy (push) Failing after 31s
Test suite / Run Rustfmt (push) Successful in 1m45s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m3s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on macos-13 (push) Has been cancelled
5293: Support merging update and replacement operations r=irevoire a=Kerollmops
This PR fixes#5286 by modifying the auto-batcher and how we merge documents when preparing them for the new indexer.
## To do
- [x] Make sure we can auto-batch different operation types.
- [x] Make sure the indexer correctly understands and mixes the different kinds.
- [x] Create a test to see if it mixes the documents correctly.
- [x] Modify the auto-batcher tests for the new behavior.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
5303: Bring back changes from v1.12.8 into v1.13.0 r=Kerollmops a=Kerollmops
Fixes#5087 and other problems that you can find in the original PR #5294.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5235: Introduce a compaction subcommand in meilitool r=dureuill a=Kerollmops
This PR proposes a change to the meilitool helper, introducing the `compact-index` subcommand to reduce the size of the indexes.
While working on this tool, I discovered that the current heed `Env::copy_to_file` API is not very temp file friendly and [could be improved](https://github.com/meilisearch/heed/issues/306).
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests almost all features (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 21s
Test suite / Tests on windows-2022 (push) Failing after 26s
Test suite / Run Clippy (push) Failing after 19s
Test suite / Run Rustfmt (push) Successful in 4m7s
Test suite / Tests on ubuntu-20.04 (push) Failing after 14m22s
Test suite / Tests on macos-13 (push) Has been cancelled
5140: Fix workload inversion r=dureuill a=ManyTheFish
The used assets were inverted between `workloads/hackernews-modify-facet-numbers.json`
and `workloads/hackernews-modify-facet-strings.json`, now fixed.
Co-authored-by: ManyTheFish <many@meilisearch.com>
5300: Improve unexpected panic message r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5273
## What does this PR do?
- When an unexpected panic happens in the index-scheduler we catch it and rebuild an error message from the join_error
- Same when the upgrade index-scheduler fails
Co-authored-by: Tamo <tamo@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 0s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 2s
Test suite / Tests on windows-2022 (push) Failing after 23s
Test suite / Run Rustfmt (push) Successful in 2m17s
Test suite / Run Clippy (push) Successful in 5m55s
Test suite / Tests on macos-13 (push) Has been cancelled
5177: Debug log the channel congestion r=Kerollmops a=Kerollmops
This PR displays the congestion of the BBQueue channel and the allocated memory for the channel and the extraction. This information can be beneficial for debugging and noticing slow disks. We show three pieces of information in debug:
- The direct attempts: the number of tries to send something in the BBQueue channel,
- The blocked attempts: the number of unsuccessful attempts that must be retried,
- The congestion: The percentage of blocking attempts. The higher, the slower the receiver and, therefore, the disk.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 1s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 0s
Test suite / Tests on windows-2022 (push) Failing after 14s
Test suite / Run Rustfmt (push) Successful in 1m59s
Test suite / Run Clippy (push) Successful in 5m48s
Test suite / Tests on macos-13 (push) Has been cancelled
5272: Fix Batches Deletion and flaky tests r=irevoire a=Kerollmops
- This issue fixes#5263 by removing the batches from the date and time databases.
- It also introduces a new `enqueued_at` field in the batch object to quickly retrieve them in the `batches.enqueued_at` database
- Finally, it probably fixes all the flaky tests of the batches: https://github.com/meilisearch/meilisearch/issues/5256
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
5289: Fix workload files after removing the vectorStore experimental feature r=Kerollmops a=dureuill
Running the bench [currently fails](https://github.com/meilisearch/meilisearch/actions/runs/12990029453) on embedding-related workloads, due to the call to `/experimental-features` that is used to enable the vector store:
In v1.13, `vectorStore` is no longer an experimental feature, so trying to enable it causes a 400
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Test suite / Tests almost all features (push) Has been skipped
Run the indexing fuzzer / Setup the action (push) Failing after 6s
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 14s
Test suite / Run tests in debug (push) Failing after 2s
Test suite / Run Rustfmt (push) Failing after 8s
Test suite / Tests on windows-2022 (push) Failing after 20s
Test suite / Run Clippy (push) Successful in 5m48s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on macos-13 (push) Has been cancelled
5210: Improve test performance of get_index.rs r=irevoire a=DerTimonius
# Pull Request
## Related issue
related to #4840
## What does this PR do?
This PR aims to improve the performance of the tests in `get_index.rs`.
There is a small issue though:
the `list_multiple_indexes` test works great when ran alone, but when running with other tests it fails with a `corrupted task queue` error. I guess this has something to do with using a shared server, but I was not really able to pinpoint the issue.
Also, the `no_index_return_empty_list` does not work a shared server (as there now will always be at least one index on the server) and I was not really sure if rebuilding the whole suite for `get_and_paginate_indexes` should be viable? While waiting for feedback on the issue mentioned above, I'll try to change the `get_and_paginate_indexes` test so that it can use the shared server
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Timon Jurschitsch <timon.jurschitsch@gmail.com>
Co-authored-by: Timon Jurschitsch <103483059+DerTimonius@users.noreply.github.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
5284: Fix [5281] Removed CouldNotUpgrade from error file r=irevoire a=manojks1999
# Pull Request
## Related issue
Fixes#5281
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [ * ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ * ] Have you read the contributing guidelines?
- [ * ] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: manojks1999 <9743manoj@gmail.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 0s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 2s
Test suite / Tests on windows-2022 (push) Failing after 22s
Test suite / Run Rustfmt (push) Successful in 2m14s
Test suite / Run Clippy (push) Successful in 5m21s
Run the indexing fuzzer / Setup the action (push) Successful in 1h4m54s
Test suite / Tests on macos-13 (push) Has been cancelled
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
5279: Bring back changes from v1.12.7 into main r=dureuill a=Kerollmops
This PR brings back v1.12.7 into main.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Run tests in debug (push) Failing after 2s
Test suite / Tests on windows-2022 (push) Failing after 21s
Test suite / Run Rustfmt (push) Failing after 8s
Test suite / Run Clippy (push) Successful in 6m30s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m21s
Test suite / Tests on macos-13 (push) Has been cancelled
5264: Dumpless upgrade r=dureuill a=irevoire
# Pull Request
Usage: https://meilisearch.notion.site/Dumpless-upgrade-fff4b06b651f81f1acafe24d4687b3f7?pvs=74
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5162
## What does this PR do?
- Implement the dumpless upgrade with multiple hooks:
- In meilisearch directly before the task queue has been opened
- In the index-scheduler while processing the task
- In milli while upgrading the indexes
- There is no hook at search/query time to handle the old version of a database. That's left to the next person upgrading a database
- A new special type of task (`upgradeDatabase`) that can be retried has been introduced
- A new experimental cli flag has been introduced
- The version has been upgraded to the v1.13.0 in this PR otherwise it was a lot of useless work to test the dumpless upgrade
- Multiple tests have been introduced
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Update the issue template we use for features, mentioning what we should do in case of a database upgrade
- [ ] The experimental feature discussion should be opened and updated in the PR
- [ ] Update the PRD
- [ ] Add the new error codes
- [ ] Add the task details
- [ ] Add the telemetry
## Notes
The new tests introduced are not _that_ slow

Co-authored-by: Tamo <tamo@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 0s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Run Clippy (push) Failing after 11s
Test suite / Tests on windows-2022 (push) Failing after 43s
Test suite / Run Rustfmt (push) Successful in 2m21s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m6s
Test suite / Tests on macos-13 (push) Has been cancelled
5257: Fix ollama r=Kerollmops a=dureuill
Fix oversight in ollama embedder
WIP Integration tests are on branch `ollama-integration-test` and will be added as a future PR.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
5271: Update version for the next release (v1.13.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: Kerollmops <Kerollmops@users.noreply.github.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Run the indexing fuzzer / Setup the action (push) Failing after 15s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 12m54s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Look for flaky tests / flaky (push) Failing after 7s
Publish binaries to GitHub release / Check the version validity (push) Successful in 11s
Publish binaries to GitHub release / Publish binary for Linux (push) Failing after 1s
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Failing after 15s
Publish binaries to GitHub release / Publish binary for windows-2022 (push) Failing after 24s
Publish binaries to GitHub release / Publish binary for macos-13 (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Has been cancelled
Test suite / Tests almost all features (push) Failing after 1s
Test suite / Test disabled tokenization (push) Failing after 2s
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Run tests in debug (push) Failing after 1s
Test suite / Tests on windows-2022 (push) Failing after 26s
Test suite / Run Clippy (push) Failing after 21s
Test suite / Run Rustfmt (push) Successful in 1m37s
Test suite / Tests on macos-13 (push) Has been cancelled
5234: Parse ollama URL to adapt configuration depending on the endpoint r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#5002
## What does this PR do?
- Parses `url` parameter of `ollama` to recognize supported endpoint and adapt the REST configuration to the recognized endpoint
- Throws a new error if no endpoint is recognized
- Add a test for the various recognized endpoints
Thanks to `@Guikingone` for the original report and PR
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m2s
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Look for flaky tests / flaky (push) Failing after 1s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Publish binaries to GitHub release / Publish binary for Linux (push) Has been skipped
Publish binaries to GitHub release / Publish binary for ${{ matrix.os }} (meilisearch, meilisearch-macos-amd64, macos-13) (push) Has been skipped
Publish binaries to GitHub release / Publish binary for ${{ matrix.os }} (meilisearch.exe, meilisearch-windows-amd64.exe, windows-2022) (push) Has been skipped
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Has been skipped
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Has been skipped
Test suite / Tests almost all features (push) Failing after 2s
Test suite / Test disabled tokenization (push) Failing after 0s
Test suite / Run tests in debug (push) Failing after 1s
Test suite / Tests on ubuntu-20.04 (push) Failing after 21s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 24s
Test suite / Run Rustfmt (push) Failing after 17s
Test suite / Run Clippy (push) Failing after 6m47s
Publish binaries to GitHub release / Check the version validity (push) Failing after 5s
5232: Stabilize vector store feature r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#4733
## What does this PR do?
- `vectorStore` feature can no longer be set or get from `/experimental-features`
- That feature has been removed, and there is no longer any check for its activation
- Always display `embedders` in the settings, even if empty
- Always hide `_vectors` in documents, unless `retrieveVectors: true`
- Make error codes consistent with the usual nomenclature
- Update tests as needed
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 27s
Test suite / Tests on ubuntu-20.04 (push) Failing after 20s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 26s
Test suite / Run Clippy (push) Successful in 7m55s
Test suite / Run Rustfmt (push) Successful in 2m21s
Run the indexing fuzzer / Setup the action (push) Successful in 1h6m18s
5239: Fix corrupted task queue errors on index creation r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5238
## What does this PR do?
- Add a test that reproduces the issue and ensure we never introduce the bug again
- Fix the bug by storing the stats of the index upon creation instead of waiting for the update index task to do it
Co-authored-by: Tamo <tamo@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 13s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 26s
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Run Clippy (push) Successful in 7m58s
Test suite / Run Rustfmt (push) Successful in 2m44s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m43s
5237: Bring back v1.12.3 changes into main r=irevoire a=dureuill
This brings back the (already reviewed) changes of v1.12.3 into main:
1. fix the field distribution issue
2. improve the error message when trying to delete a non-existing key
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
- `vectorStore` feature is always enabled
- `vectorStore` can no longer be set in the `/experimental-features` PATCH route
- `vectorStore` status is no longer returned in the `/experimental-features` GET route
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 13s
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 9s
Test suite / Run Clippy (push) Successful in 6m11s
Test suite / Run Rustfmt (push) Successful in 2m38s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m8s
5182: Remove hard coded task ids to prevent flaky tests r=irevoire a=mhmoudr
# Pull Request
## Related issue
Fixes partial #4840
## What does this PR do?
- Mainly scan the test code for any hard coded task Id and replace it by the returned task Id once the action or task is performed on an index.
- PS: _PR is not split by files as it has one theme applied to all tests which make it easy to review_
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Mahmoud Rawas <mhmoudr@gmail.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 12s
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 9s
Test suite / Run Clippy (push) Successful in 6m16s
Test suite / Run Rustfmt (push) Successful in 1m39s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m11s
5223: Limit batched tasks total size r=curquiza a=Kerollmops
Introduce a new engine parameter (env and config, too) to limit the maximum payload size processed by the engine in batches. You can [review the Discussion and usage on GitHub](https://github.com/orgs/meilisearch/discussions/801).
Co-authored-by: Clément Renault <clement@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 22s
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Tests almost all features (push) Failing after 9s
Test suite / Test disabled tokenization (push) Failing after 9s
Test suite / Run tests in debug (push) Failing after 9s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m27s
Test suite / Run Rustfmt (push) Successful in 1m37s
Test suite / Run Clippy (push) Successful in 5m58s
5216: Add support for GITHUB_TOKEN authentication in installation script r=curquiza a=Sherlouk
# Pull Request
## What does this PR do?
This tweaks the install script to support detection of a "GITHUB_TOKEN" variable. This is well documented [here](https://docs.github.com/en/actions/security-for-github-actions/security-guides/automatic-token-authentication) but is useful for GitHub Actions workflows, reducing the need for users to maintain a separate PAT token. This should be more reliable.
Note: these changes have been tested on the Swift project: https://github.com/meilisearch/meilisearch-swift/pull/464.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: James Sherlock <15193942+Sherlouk@users.noreply.github.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 48s
Test suite / Run Clippy (push) Successful in 7m0s
Test suite / Run Rustfmt (push) Successful in 1m55s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m59s
4867: Autogenerate the openAPI spec r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5073
## What does this PR do?
- Introduce utoipa and the auto-generation of the openAPI file
- Introduce the scalar swagger when the `swagger` feature flag is enabled.
Generating the openAPI file takes between 15 and 20ms at startup time on my computer. That could be an issue if we plan to stabilize the feature.
Co-authored-by: Tamo <tamo@meilisearch.com>
5168: Refactor indexer r=ManyTheFish a=dureuill
# Pull Request
Split the indexer mod into multiple submodules.
This restores the ability of rustfmt to format the file 🎉
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 24s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 33s
Test suite / Run tests in debug (push) Failing after 9s
Test suite / Run Clippy (push) Successful in 6m27s
Test suite / Run Rustfmt (push) Successful in 1m44s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m26s
5199: Refactorize the index-scheduler r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5115
## What does this PR do?
- Extract all the « task/batch queue » part of the `lib.rs` to a `queue` module containing:
- The batches, and its test in another file
- The tasks, and its test in another file
- Extract all the « scheduler » stuff to another module
- One file for the batch creation
- One file for the autobatcher
- One file for the batch process
- The tests are a bit messier and are made by features (i.e.: All the embedder tests in one file)
- The average size of the files is around 500 loc now and R-A is way faster
Co-authored-by: Tamo <tamo@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 46s
Test suite / Tests on ubuntu-20.04 (push) Failing after 10s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 9s
Test suite / Run Clippy (push) Successful in 6m53s
Test suite / Run Rustfmt (push) Successful in 1m40s
Run the indexing fuzzer / Setup the action (push) Successful in 1h6m8s
5211: Update README.md with AI integrations (langchain & MCP) r=ManyTheFish a=tpayet
With AI integrations 🤖
# Pull Request
## Related issue
None
## What does this PR do?
- Update the README with AI integrations
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Thomas Payet <thomas@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 2s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 53s
Test suite / Run Clippy (push) Successful in 6m35s
Test suite / Run Rustfmt (push) Successful in 1m41s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m27s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
5166: fix list indexes r=dureuill a=irevoire
# Pull Request
### Smol benchmark on a meilisearch with 1009 indexes:
**Before** this PR on my computer, it was taking 5.5s to call the `GET /indexes` route on a cold computer where all the indexes were closed.
**After** this PR it takes 0.009s to call the route on the first 20 indexes, and 0.176 for the last 20 indexes (retrieving the first or last indexes on main has no impact on performances).
If my computations are right, that's between 61111.1% and 3125% faster on this test 😂
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4694
## What does this PR do?
- Add the primary key to the cache we already have in the index-mapper
- Provide a new route to retrieve the paginated indexes straight from the cache without opening them
- Fix a bug where the cache was not computed when loading a dump and was forcing us to open the indexes to compute their stats on the fly
## Is it breaking?
Since the field I added is an `Option` I think we should consider it as non-breaking and let it update itself automatically on the next operation of this index.
I also tested to run my patch over a DB generated on release-v1.12.0 and it works. The importing a dump also works.
Co-authored-by: Tamo <tamo@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 13s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 52s
Test suite / Run Clippy (push) Successful in 6m45s
Test suite / Run Rustfmt (push) Successful in 1m43s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m31s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Has been cancelled
5178: Add Prometheus metrics to measure task queue latency r=irevoire a=takaebato
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5046
## What does this PR do?
- Added Prometheus metrics to measure task queue latency
(Confirmed locally that latency is measured during parallel task execution in the benchmark.)
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Takahiro Ebato <takahiro.ebato@gmail.com>
5169: Replace hardcoded string with constants r=irevoire a=Gnosnay
# Pull Request
## Related issue
Fixes#5136
## What does this PR do?
- Replace all of hardcoded "_geo" to one constant string.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Gnosnay <iamgnosnay@gmail.com>
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 24s
Test suite / Tests on ubuntu-20.04 (push) Failing after 16s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 15s
Test suite / Run Clippy (push) Successful in 57m37s
Test suite / Run Rustfmt (push) Successful in 7m19s
Run the indexing fuzzer / Setup the action (push) Failing after 1h41m18s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Has been cancelled
5135: Check all search filter attributes are filterable upfront r=curquiza a=jameshiew
# Pull Request
## Related issue
Fixes#5069
## What does this PR do?
- checks all `fid`s in the `Filter` tree are filterable before evaluating search query
- returns AttributeNotFilterable error if any are not
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: James Hiew <james@hiew.net>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 12s
Test suite / Tests on ubuntu-20.04 (push) Failing after 20s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 16s
Test suite / Run Clippy (push) Successful in 33m58s
Test suite / Run Rustfmt (push) Successful in 11m45s
Run the indexing fuzzer / Setup the action (push) Successful in 1h10m33s
5187: Bring back v1.12.0 of pre-release changes into `main` r=irevoire a=curquiza
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: Many the fish <many@meilisearch.com>
5184: Fix typo in a comment r=curquiza a=eltociear
# Pull Request
## What does this PR do?
- formating -> formatting
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Ikko Eltociear Ashimine <eltociear@gmail.com>
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 22s
Test suite / Run tests in debug (push) Failing after 15s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 29s
Test suite / Run Rustfmt (push) Successful in 1h14m6s
Test suite / Run Clippy (push) Failing after 2h47m59s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m44s
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Has been cancelled
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
5174: Split tests for option crate meilisearch in a separate test file r=irevoire a=K-Kumar-01
# Pull Request
Splits the tests for meilisearch option crate in a separate testfile.
## Related issue
Partially solves #5116
## What does this PR do?
- Splits the test for `/src/option.rs` into a separate file `/src/option_test.rs` in meilisearch crate
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Kushal Kumar <kushalkumargupta4@gmail.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 18s
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 8s
Test suite / Run Clippy (push) Successful in 6m42s
Test suite / Run Rustfmt (push) Successful in 1m42s
Run the indexing fuzzer / Setup the action (push) Failing after 20m27s
5175: fix the flaky batches test r=dureuill a=irevoire
## What does this PR do?
I finally reproduced the flaky test in the CI here: https://github.com/meilisearch/meilisearch/actions/runs/12390709982/job/34586313125
I cannot reproduce it locally even with `cargo flaky --iter 2000` so I'm not 100% my fix will work.
But what I did was definitely part of the flakyness of the tests, we were querying a batch that could in some cases not be started.
That worked well for the tasks since an enqueued task is already written on disk, but since the batch do not exist if they're not processing they were just missing.
---
I also changed what we were doing because there is no point in doing an indexing process for this test
Co-authored-by: Tamo <tamo@meilisearch.com>
5173: Remove obsolete test code r=irevoire a=K-Kumar-01
# Pull Request
Removes the test from the meilisearch/search/mod.rs. The tests were already split in the PR #5171
## What does this PR do?
- Removes the obsolete tests
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Kushal Kumar <kushalkumargupta4@gmail.com>
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 13s
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Run Clippy (push) Successful in 6m34s
Test suite / Run Rustfmt (push) Successful in 1m50s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m21s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Has been cancelled
5171: tests: split tests in separate file r=irevoire a=K-Kumar-01
# Pull Request
Splits the tests for meilisearch search crate in a separate testfile.
## Related issue
Partially solves #5116.
## Related Pull Requests
https://github.com/meilisearch/meilisearch/pull/5134
## What does this PR do?
- Splits the test for `/search/mod.rs` into a separate file `search/mod_test.rs` in meilisearch crate
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Kushal Kumar <kushalkumargupta4@gmail.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 16s
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Run Clippy (push) Successful in 6m16s
Test suite / Run Rustfmt (push) Successful in 1m55s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m33s
5134: Split Meilisearch Crate Tests in separate file r=irevoire a=K-Kumar-01
# Pull Request
Splits the tests for meilisearch crate in a separate file.
## Related issue
Partially solves #5116
## What does this PR do?
- Splits the test for `/indexes/search.rs` into a separate file `indexes/search_test.rs` in meilisearch crate
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Kushal Kumar <kushalkumargupta4@gmail.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 22s
Test suite / Run Rustfmt (push) Successful in 1m18s
Test suite / Run Clippy (push) Successful in 5m30s
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Has been cancelled
5159: Fix the New Indexer Spilling r=irevoire a=Kerollmops
Fix two bugs in the merging of the spilled caches. Thanks to `@ManyTheFish` and `@irevoire` 👏
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 46s
Test suite / Tests on ubuntu-20.04 (push) Failing after 13s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 15s
Test suite / Run Rustfmt (push) Successful in 9m49s
Test suite / Run Clippy (push) Successful in 46m15s
5158: Indexer edition 2024 fix facet fst r=Kerollmops a=ManyTheFish
# Pull Request
Fix a regression in the new indexer; when several filterable attributes containing strings were set, all the field IDs were shifted, and the last one was overwriting the previous FST.
## What does this PR do?
- Add a test reproducing the bug
- fix the bug
Co-authored-by: ManyTheFish <many@meilisearch.com>
5152: Make xtasks be able to use the specified binary r=dureuill a=Kerollmops
Makes it possible to specify the binary to run. It is useful to run PGO optimized binaries.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
5147: Batch progress r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5068
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Tamo <tamo@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 47s
Test suite / Run Rustfmt (push) Successful in 1m17s
Test suite / Run Clippy (push) Successful in 5m30s
5144: Exactly 512 bytes docid fails r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#5050
## What does this PR do?
- Return a user error rather than an internal one for docids of exactly 512 bytes
- Fix up error message to indicate that exactly 512 bytes long docids are not supported.
- Fix up error message to reflect that index uids are actually limited to 400 bytes in length
## Impact
- Impacts docs:
- update [this paragraph](https://www.meilisearch.com/docs/learn/resources/known_limitations#length-of-primary-key-values) to say 511 bytes instead of 512
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
5153: Return docid in case of errors while rendering the document template r=Kerollmops a=dureuill
Improves error message:
Before:
```
ERROR index_scheduler: Batch failed Index `mieli`: user error: missing field in document: liquid: Unknown index
with:
variable=doc
requested index=title
available indexes=by, id, kids, parent, text, time, type
```
After:
```
ERROR index_scheduler: Batch failed Index `mieli`: user error: missing field in document `11345147`: liquid: Unknown index
with:
variable=doc
requested index=title
available indexes=by, id, kids, parent, text, time, type
```
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 19s
Test suite / Run tests in debug (push) Failing after 14s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 23s
Test suite / Run Rustfmt (push) Successful in 4m52s
Test suite / Run Clippy (push) Failing after 8m9s
5146: Offline upgrade v1.12 r=irevoire a=ManyTheFish
# Pull Request
## Related issue
Fixes#4978
## What does this PR do?
- add v1_11_to_v1_12 function to upgrade Meilisearch from v1.11 to v1.12
- Convert the update files from OBKV to ndjson format
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Many the fish <many@meilisearch.com>
5148: Do not duplicate NDJson data when unecessary r=dureuill a=Kerollmops
This PR improves the NDJSON support. Usually, we save all of the user's document content into a temporary file, validate its content, and then convert everything into NDJSON in the file store (update files in the tasks).
It is a waste of time when users are already sending NDJSON. So, this PR removes the last copy and directly stores the user content in the file store, validating it from the file store. If an issue arises, the file will not persist and will be dropped/deleted instead.
Related to #5078.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Run tests in debug (push) Failing after 9s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 22s
Test suite / Run Rustfmt (push) Successful in 1m18s
Test suite / Run Clippy (push) Successful in 5m32s
5145: Use bumparaw-collections in Meilisearch/milli r=dureuill a=Kerollmops
This PR is related to #5078. It uses the now published bumparaw-collections and (soon) makes the `RawMap` hasher nonrandom.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 16s
Test suite / Run tests in debug (push) Failing after 14s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 44s
Test suite / Run Rustfmt (push) Successful in 9m52s
Test suite / Run Clippy (push) Successful in 1h2m24s
5141: Use the right amount of max memory and not impact the settings r=curquiza a=Kerollmops
Fixes#5132. Related to #5125.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5056: Attach index name in error message r=irevoire a=airycanon
# Pull Request
## Related issue
Fixes#4392
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: airycanon <airycanon@airycanon.me>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 37s
Test suite / Tests on ubuntu-20.04 (push) Failing after 15s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 12s
Test suite / Run Rustfmt (push) Successful in 2m14s
Test suite / Run Clippy (push) Successful in 12m4s
5125: Change the default max memory usage to 5% of the total memory r=ManyTheFish a=Kerollmops
After thorough testing, we found that giving 5% of the total available memory to allocate resident memory (caches and channels) is the best approach.
The main reason is that the new indexer is highly memory-map oriented, with LMDB, and reads the database while performing the indexation. So, by allowing the maximum amount of memory available to LMDB and the OS, it will perform the key-value store reads and all other indexation operations faster by keeping more pages hot in the cache. In #5124, we also sorted the entries to merge to improve the read speed of LMDB.
This is common in database management systems: Reading stuff on the disk is much faster when done in lexicographic order (the default sorted order of key values). The entries have a great chance of already being in the OS memory cache, as they were loaded in a previous read, and reading stuff on the disk is very slow compared to reading memory.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5124: Optimize Prefixes and Merges r=ManyTheFish a=Kerollmops
In this PR, we plan to optimize the read of LMDB to use read the entries in lexicographic order and better use the memory-mapping OS cache:
- Optimize the prefix generation for word position docids (`@manythefish)`
- Optimize the parallel merging of the caches to sort entries before merging the caches (`@kerollmops)`
## Benchmarks on 1cpu 2gb gpo3 (5k IOps)
Before on the tag meilisearch-v1.12.0-rc.3.
```
word_position_docids:merge_and_send_docids: 988s
compute_word_fst: 23.3s
word_pair_proximity_docids:merge_and_send_docids: 428s
compute_word_prefix_fid_docids:recompute_modified_prefixes: 76.3s
compute_word_prefix_position_docids:recompute_modified_prefixes:from_prefixes: 429s
```
After sorting the whole `HashMap`s in a `Vec` on this branch.
```
word_position_docids:merge_and_send_docids: 202s
compute_word_fst: 20.4s
word_pair_proximity_docids:merge_and_send_docids: 427s
compute_word_prefix_fid_docids:recompute_modified_prefixes: 65.5s
compute_word_prefix_position_docids:recompute_modified_prefixes:from_prefixes: 62.5s
```
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
5120: Add cross tasks r=Kerollmops a=ManyTheFish
Add 4 xtask bench workloads:
- `hackernews-add-new-documents`: adds new documents on a db already containing documents
- `hackernews-modify-facet-numbers`: modify filterable fields containing numbers of documents on a db already containing documents
- `hackernews-modify-facet-strings`: modify filterable fields containing strings of documents on a db already containing documents
- `hackernews-modify-searchables`: modify searchable fields of documents on a db already containing documents
Co-authored-by: ManyTheFish <many@meilisearch.com>
5122: Yield the BBQueue writing loop r=ManyTheFish a=Kerollmops
We prefer yielding to let the writing thread do its job instead of spin looping.
Co-authored-by: Kerollmops <clement@meilisearch.com>
5110: Increase margin on deletion of task r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5077
## What does this PR do?
- Increase the margin we keep to enqueue task deletion
The issue was that we had not enough space on the reserved memory to write both the batch and the deletion task we just enqueued.
We could fix it only for this test as it’s not an issue in production where we have 10GiB of margin, but I thought it wasn’t a bad idea either to increase our margin a bit since we’re effectively writing more to lmdb.
Co-authored-by: Tamo <tamo@meilisearch.com>
5118: Change the reserve and grant function to accept a closure r=ManyTheFish a=Kerollmops
This simplifies the usage of the grant and commits it at the right time, just after having written in it.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 43s
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 9s
Test suite / Run Clippy (push) Successful in 7m18s
Test suite / Run Rustfmt (push) Successful in 1m32s
5111: Update BBQueue repo to point to the Meilisearch org r=curquiza a=Kerollmops
This PR updates the milli dependencies to make BBQueue point to the Meilisearch org repo.
Co-authored-by: Clément Renault <clement@meilisearch.com>
5094: Implement a bbqueue channel between the extractors and the writer r=dureuill a=Kerollmops
This PR switches from a bounded crossbeam channel only with allocated entries for the communication between the extractors and the writer to a [BBQueue](https://github.com/jamesmunns/bbqueue)-based system with a Single Producer Single Consumer kind of Circular/Ring Buffers channel.
- [x] Implement the BBQueue channel system...
- [x] with a crossbeam channel to wake up the receiver.
- [x] Manage the BBQueue allocated memory dynamically.
- [x] Support content that doesn't fit in the bbqueues.
Co-authored-by: Clément Renault <clement@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 24s
Test suite / Run Rustfmt (push) Successful in 1m22s
Test suite / Run Clippy (push) Successful in 6m29s
5109: Fix autobatch r=dureuill a=dureuill
Fixes most SDK tests and flaky failures
Changes:
- Make sure that the settings are not autobatched with document operations, as the new indexer no longer supports this operating mode
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
5107: While spamming the batches route we could see a processing batch becoming missing and then finished, this commit ensures the batches goes from processing to finished directly r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes the failed tests from this PR: https://github.com/meilisearch/meilisearch-js/pull/1775
See [this message](https://meilisearch.slack.com/archives/CD7Q2UKGB/p1732784680450749) [private link] for more context
## What does this PR do?
- Ensure we never enter a state where a processing batches (only existing in RAM) becomes « Not found » by removing the processing batches AFTER writing them to disk
- This should also theoretically avoid an issue where a task could go from processing to enqueued and then finished
Co-authored-by: Tamo <tamo@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 23s
Test suite / Tests on ubuntu-20.04 (push) Failing after 13s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Run tests in debug (push) Failing after 12s
Test suite / Run Clippy (push) Successful in 9m3s
Test suite / Run Rustfmt (push) Successful in 2m44s
Run the indexing fuzzer / Setup the action (push) Successful in 1h6m48s
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
5104: Bump xt0rted/pull-request-comment-branch from 2 to 3 r=curquiza a=dependabot[bot]
Bumps [xt0rted/pull-request-comment-branch](https://github.com/xt0rted/pull-request-comment-branch) from 2 to 3.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/xt0rted/pull-request-comment-branch/releases">xt0rted/pull-request-comment-branch's releases</a>.</em></p>
<blockquote>
<h2>v3.0.0</h2>
<ul>
<li>Updated node runtime from 16 to 20</li>
<li>Bumped <code>`@actions/core</code>` from 1.10.0 to 1.11.1</li>
<li>Bumped <code>`@actions/github</code>` from 5.1.1 to 6.0.0</li>
<li>Bumped <code>undici</code> from 5.28.3 to 5.28.4</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/xt0rted/pull-request-comment-branch/blob/main/CHANGELOG.md">xt0rted/pull-request-comment-branch's changelog</a>.</em></p>
<blockquote>
<h2><a href="https://github.com/xt0rted/pull-request-comment-branch/compare/v2.0.0...v3.0.0">3.0.0</a> - 2024-11-19</h2>
<ul>
<li>Updated node runtime from 16 to 20</li>
<li>Bumped <code>`@actions/core</code>` from 1.10.0 to 1.11.1</li>
<li>Bumped <code>`@actions/github</code>` from 5.1.1 to 6.0.0</li>
<li>Bumped <code>undici</code> from 5.28.3 to 5.28.4</li>
</ul>
<h2><a href="https://github.com/xt0rted/pull-request-comment-branch/compare/v1.4.0...v2.0.0">2.0.0</a> - 2023-03-29</h2>
<ul>
<li>Updated node runtime from 12 to 16</li>
<li>Removed deprecated <code>ref</code> and <code>sha</code> outputs. If you're using these then you should switch to <code>head_ref</code> and <code>head_sha</code> respectively.</li>
</ul>
<h2><a href="https://github.com/xt0rted/pull-request-comment-branch/compare/v1.3.0...v1.4.0">1.4.0</a> - 2022-10-23</h2>
<ul>
<li>Bumped <code>`@actions/core</code>` from 1.2.7 to 1.10.0</li>
<li>Bumped <code>`@actions/github</code>` from 4.0.0 to 5.1.1</li>
<li>Bumped <code>node-fetch</code> from 2.6.1 to 2.6.7</li>
</ul>
<h2><a href="https://github.com/xt0rted/pull-request-comment-branch/compare/v1.2.0...v1.3.0">1.3.0</a> - 2021-05-09</h2>
<ul>
<li>Bumped <code>`@actions/core</code>` from 1.2.5 to 1.2.7</li>
<li>Updated the <code>repo_token</code> input so it defaults to <code>GITHUB_TOKEN</code>. If you're already using this value you can remove this setting from your workflow.</li>
</ul>
<h2><a href="https://github.com/xt0rted/pull-request-comment-branch/compare/v1.1.0...v1.2.0">1.2.0</a> - 2020-09-09</h2>
<ul>
<li>Deprecated <code>ref</code> and <code>sha</code> outputs in favor of <code>head_ref</code> and <code>head_sha</code>.</li>
<li>Added <code>base_ref</code> and <code>base_sha</code> outputs</li>
<li>Bumped <code>`@actions/core</code>` from 1.2.2 to 1.2.5</li>
<li>Bumped <code>`@actions/github</code>` from 2.1.1 to 4.0.0</li>
</ul>
<h2><a href="https://github.com/xt0rted/pull-request-comment-branch/compare/v1.0.0...v1.1.0">1.1.0</a> - 2020-02-21</h2>
<ul>
<li>Bumped <code>`@actions/github</code>` from 2.1.0 to 2.1.1</li>
</ul>
<h2><a href="https://github.com/xt0rted/pull-request-comment-branch/releases/tag/v1.0.0">1.0.0</a> - 2020-02-09</h2>
<ul>
<li>Initial release</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="e8b8daa837"><code>e8b8daa</code></a> Release v3.0.0</li>
<li><a href="bdedca277b"><code>bdedca2</code></a> v3.0.0</li>
<li><a href="4bff54f5df"><code>4bff54f</code></a> Merge pull request <a href="https://redirect.github.com/xt0rted/pull-request-comment-branch/issues/437">#437</a> from xt0rted/dependabot/npm_and_yarn/undici-5.28.4</li>
<li><a href="e0ea3daa0d"><code>e0ea3da</code></a> Update CHANGELOG.md</li>
<li><a href="3096af14cd"><code>3096af1</code></a> Bump undici from 5.28.3 to 5.28.4</li>
<li><a href="b7ffabdc5d"><code>b7ffabd</code></a> Merge pull request <a href="https://redirect.github.com/xt0rted/pull-request-comment-branch/issues/461">#461</a> from xt0rted/dependabot/npm_and_yarn/actions-e659d6d3f1</li>
<li><a href="6fc3c73d82"><code>6fc3c73</code></a> Update CHANGELOG.md</li>
<li><a href="20807fbbbc"><code>20807fb</code></a> Bump <code>`@actions/core</code>` from 1.10.1 to 1.11.1 in the actions group</li>
<li><a href="8d51fb5346"><code>8d51fb5</code></a> Merge pull request <a href="https://redirect.github.com/xt0rted/pull-request-comment-branch/issues/463">#463</a> from xt0rted/dependabot/npm_and_yarn/typescript-5.6.3</li>
<li><a href="37c7636fab"><code>37c7636</code></a> Merge pull request <a href="https://redirect.github.com/xt0rted/pull-request-comment-branch/issues/462">#462</a> from xt0rted/dependabot/npm_and_yarn/vercel/ncc-0.38.3</li>
<li>Additional commits viewable in <a href="https://github.com/xt0rted/pull-request-comment-branch/compare/v2...v3">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
5101: Fix index settings opt out r=Kerollmops a=ManyTheFish
# Pull Request
## Related issue
Fixes#5099
## What does this PR do?
- Refactor the settings implementation ensuring the routes are configured
- Add a test checking if all the routes are tested
- Refactor the tests to ease the modifications
Co-authored-by: ManyTheFish <many@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 13s
Test suite / Run tests in debug (push) Failing after 12s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 40s
Test suite / Run Rustfmt (push) Successful in 1m46s
Test suite / Run Clippy (push) Successful in 9m55s
5095: Span to measure the part of db writes that is after the merge/extraction r=curquiza a=dureuill
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Run tests in debug (push) Failing after 11s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 23s
Test suite / Run Rustfmt (push) Successful in 1m41s
Test suite / Run Clippy (push) Successful in 5m36s
5092: Precise spans for new indexer r=dureuill a=dureuill
- Separate extract and merge spans
- Add span around commit
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
5089: Improve error handling when writing into LMDB r=dureuill a=Kerollmops
This PR exposes two new internal error variants: `StoreDelete` and `StorePut`. So that the error messages are better when we fail at writing into LMDB.
Related to #5078
Co-authored-by: Clément Renault <clement@meilisearch.com>
5090: Use the published crates versions r=dureuill a=Kerollmops
This PR uses the published versions of the obkv, grenad, and roaring crates in milli and Meilisearch.
Related to #5078.
Co-authored-by: Clément Renault <clement@meilisearch.com>
Test suite / Tests on ubuntu-20.04 (push) Failing after 11s
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 24s
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Run Clippy (push) Successful in 6m35s
Test suite / Run Rustfmt (push) Successful in 1m52s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m8s
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Has been cancelled
Indexing bench (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of indexing (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Has been cancelled
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Has been cancelled
5076: Update version for the next release (v1.12.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m43s
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Publish binaries to GitHub release / Publish binary for ${{ matrix.os }} (meilisearch, meilisearch-macos-amd64, macos-13) (push) Waiting to run
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Waiting to run
Look for flaky tests / flaky (push) Failing after 21s
Test suite / Tests on ubuntu-20.04 (push) Failing after 10s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 22s
Test suite / Tests almost all features (push) Failing after 7s
Test suite / Test disabled tokenization (push) Failing after 7s
Test suite / Run tests in debug (push) Failing after 9s
Test suite / Run Rustfmt (push) Successful in 1m24s
Test suite / Run Clippy (push) Successful in 6m14s
Publish binaries to GitHub release / Check the version validity (push) Successful in 7s
Publish binaries to GitHub release / Publish binary for Linux (push) Failing after 9s
Publish binaries to GitHub release / Publish binary for ${{ matrix.os }} (meilisearch.exe, meilisearch-windows-amd64.exe, windows-2022) (push) Failing after 19s
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Failing after 9s
5080: Fix getting a single batch through the GET route r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes a bug where getting a single batch does not work
Related to #5070
fix by `@Kerollmops`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4900: Indexer edition 2024 r=Kerollmops a=dureuill
This PR is implementing the indexer edition 2024, largely inspired by [the ideas from this blog post](https://blog.kerollmops.com/meilisearch-is-too-slow).
Fixes https://github.com/meilisearch/meilisearch/issues/4985
## Features
- Stream-first approach to reading documents.
- Minimum disk write operations.
- RAM usage-first approach to avoid modifying common bitmaps on disk but in memory.
- Reduced LMDB fragmentation by writing entries only once...
- ...computing the final version of the entries in parallel...
- ...and storing them in write-optimized data structures before sending them to the BTree (LMDB).
- Indexing in multiple transactions to improve large dataset support (dumps).
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Publish binaries to GitHub release / Check the version validity (push) Successful in 11s
Publish binaries to GitHub release / Publish binary for ${{ matrix.os }} (meilisearch, meilisearch-macos-amd64, macos-13) (push) Waiting to run
Publish binaries to GitHub release / Publish binary for macOS silicon (meilisearch-macos-apple-silicon, aarch64-apple-darwin) (push) Waiting to run
Publish binaries to GitHub release / Publish binary for ${{ matrix.os }} (meilisearch.exe, meilisearch-windows-amd64.exe, windows-2022) (push) Failing after 21s
Publish binaries to GitHub release / Publish binary for Linux (push) Failing after 12s
Publish binaries to GitHub release / Publish binary for aarch64 (meilisearch-linux-aarch64, aarch64-unknown-linux-gnu) (push) Failing after 10s
Run the indexing fuzzer / Setup the action (push) Successful in 1h5m1s
Test suite / Tests on ubuntu-20.04 (push) Failing after 12s
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Waiting to run
Test suite / Tests almost all features (push) Failing after 9s
Test suite / Test disabled tokenization (push) Failing after 8s
Test suite / Run tests in debug (push) Failing after 10s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 40s
Test suite / Run Rustfmt (push) Successful in 1m28s
Test suite / Run Clippy (push) Successful in 5m29s
5060: Batch route r=Kerollmops a=irevoire
# Pull Request
See [usage](https://www.notion.so/meilisearch/Enhance-visibility-on-batched-tasks-1194b06b651f810b8fe0fab5d72846a8).
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4977
## What does this PR do?
- For more detailed information, see the PRD.
- Added a `batchUid` to the tasks (that's the cause of all the updates of the dumps):
- For all enqueued tasks, it's set to `None`
- For every other tasks it must be set to something
- ⚠️ For all the tasks imported in a dump, the `batchUid` will be set to `None` as well.
- Add two new routes:
- `GET /batches/:uid` - to query a batch by its id
- `GET /batches` - to retrieve a list of batches. It accepts all the same query parameters that are available on the `GET /tasks` route
- Adds new databases to query the batches directly:
- When doing a query against the batches, the rule of thumb is that we want to return a batch iif **at least one** task in it matches the provided filter.
- We don't need a `canceledBy` batch specific database because we can just retrieve the task and if it's a `taskCancelation` retrieve its `batchUid`
- The task cancelation has been updated and simplified a bit:
- Instead of updating the matching tasks on disk while processing the cancelation task, we instead retrieve the task and let the `tick` function do the work afterward.
- In the `tick` function, we now have to take care of not missing any tasks
- All the tests applied to the tasks were duplicated and updated to works with the new batches routes
- The deletion of batches doesn't contain any tests because it's already tested in the deletion of tasks (and especially highlighted in the snapshots)
Currently, one part of the PRD is not implemented: it's the progress.
Co-authored-by: Tamo <tamo@meilisearch.com>
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Run the indexing fuzzer / Setup the action (push) Successful in 1h4m31s
* Remove unreachable code
* Add `indices` field to `MatchBounds`
For matches inside arrays, this field holds the indices of the array
elements that matched. For example, searching for `cat` inside
`{ "a": ["dog", "cat", "fox"] }` would return `indices: [1]`. For nested
arrays, this contains multiple indices, starting with the one for the
top-most array. For matches in fields without arrays, `indices` is not
serialized (does not exist) to save space.
Test suite / Tests almost all features (push) Has been skipped
Test suite / Test disabled tokenization (push) Has been skipped
Test suite / Tests on ubuntu-20.04 (push) Failing after 14s
Test suite / Run tests in debug (push) Failing after 24s
Test suite / Tests on ${{ matrix.os }} (windows-2022) (push) Failing after 57s
Test suite / Run Rustfmt (push) Successful in 1m36s
Test suite / Run Clippy (push) Successful in 6m8s
Indexing bench (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of indexing (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for geo (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for songs (push) / Run and upload benchmarks (push) Waiting to run
Benchmarks of search for Wikipedia articles (push) / Run and upload benchmarks (push) Waiting to run
Run the indexing fuzzer / Setup the action (push) Successful in 1h4m23s
Test suite / Tests on ${{ matrix.os }} (macos-13) (push) Has been cancelled
5048: Reverse the order of the task queue r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5047
## What does this PR do?
- Provide a new parameter to reverse the order of the task queue
- Add tests
- Remove some unrelated tests that were duplicated in tests/tasks/mod.rs and tests/tasks/error.rs
Co-authored-by: Tamo <tamo@meilisearch.com>
5044: Adds new metrics to prometheus r=irevoire a=PedroTurik
not 100% confident in this solution, especially because i couldn't make the "Search Queue searches waiting" metric give me any value other than 0 with my local testing 😆. But i believe it solves the Issue.
# Pull Request
## Related issue
Fixes#4998
## What does this PR do?
### Adds new metrics to prometheus;
- SearchQueue size,
- SearchQueue searches running,
- and Search Queue searches waiting.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Pedro Turik Firmino <pedroturik@gmail.com>
5025: test: improve performance of get_documents.rs r=irevoire a=PedroTurik
# Pull Request
## Related issue
Fixes one item from #4840
## What does this PR do?
- Applies the changes recommended on the issue for `meilisearch/tests/documents/get_documents.rs`
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Pedro Turik Firmino <pedroturik@gmail.com>
4928: Make matches consider phrases as a single `Match` r=ManyTheFish a=flevi29
# Pull Request
## Related issue
Fixes#4732
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: F. Levi <55688616+flevi29@users.noreply.github.com>
5034: Upgrade from v1 10 to v1 11 r=irevoire a=irevoire
# Pull Request
## Related issue
Parts of https://github.com/meilisearch/meilisearch/issues/4978
## What does this PR do?
- Move the code around the offline upgrade to its own module with a file per version
- Fix the upgrade from v1.9 to v1.10 because I couldn’t make it work anymore. It now uses a specified format instead of relying on cargo to get the right set of feature
- ☝️ must be checked against docker
- Provide an update path from v1.10 to v1.11. Most of the code is boilerplate in meilitool, the real code is located here: 053807bf38/src/lib.rs (L161-L269)
Co-authored-by: Tamo <tamo@meilisearch.com>
5026: test: improve performance of update_documents.rs r=dureuill a=PedroTurik
# Pull Request
## Related issue
Fixes one item from #4840
## What does this PR do?
- Applies the changes recommended on the issue for `meilisearch/tests/documents/update_documents.rs`
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Pedro Turik Firmino <pedroturik@gmail.com>
5016: Hide code complexity into a subfolder r=Kerollmops a=Kerollmops
This PR moves the complexity and main code into a subfolder to make the main repository page more welcoming by reducing the number of visible files and showing the README earlier.
Co-authored-by: Clément Renault <clement@meilisearch.com>
5017: Rollback the Meilisearch Kawaii logo r=curquiza a=Kerollmops
This PR reverts #4778 and brings back the official one. It's no longer the time to JOKE, OK !?
Co-authored-by: Clément Renault <clement@meilisearch.com>
5011: Revamp analytics r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/5009
## What does this PR do?
- Force every analytics to go through a trait that forces you to handle aggregation correcty
- Put the code to retrieve the `user-agent`, `timestamp` and `requests.total_received` in common between all aggregates, so there is no mistake
- Get rids of all the different channel for each kind of event in favor of an any map
- Ensure that we never [send empty event ever again](https://github.com/meilisearch/meilisearch/pull/5001)
- Merge all the sub-settings route into a global « Settings Updated » event.
- Fix: When using one of the three following feature, we were not sending any analytics IF they were set from the global route
- /non-separator-tokens
- /separator-tokens
- /dictionary
Co-authored-by: Tamo <tamo@meilisearch.com>
5008: Display vectors when no custom vectors where ever provided r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes the issue reported on [Discord](https://discord.com/channels/1006923006964154428/1294653031958446080/1295336784896589967).
## What does this PR do?
- Normal behavior of Meilisearch is to hide `_vectors` even when `retrieveVectors: true` when there is an explicit list of displayed attributes that does not contain vectors
- However, this relied on the field id for the `_vectors` field to exist, which wasn't the case when no `_vectors` was manually provided to documents. This would often be the case for people using autoembedders such as the OpenAI integration.
- This PR fixes the behavior by looking for the `_vectors` string in the `displayedAttributes` when there is no `_vectors` fid.
- This PR also adds a test for this specific situation, that would fail before the PR, and pass after the PR
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
5001: Do not send empty edit document by function r=Kerollmops a=irevoire
# Pull Request
We realized that we had a huge usage of the feature from user who didn’t enable the feature at all. That shouldn’t be possible.
After a big investigation with `@gmourier`

We found the issue, it was in the engine
## What does this PR do?
- Do not send the edit by function event to segment if no event was received during this batch
Co-authored-by: Tamo <tamo@meilisearch.com>
4992: fix the bad experimental search queue size r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes#4991
## What does this PR do?
- Set the right default value for the experimental search queue size in the config file
Co-authored-by: Tamo <tamo@meilisearch.com>
4962: test: improve performance of create_index.rs r=irevoire a=DerTimonius
# Pull Request
## Related issue
related to #4840
## What does this PR do?
This PR follows the instructions in #4840 and improves the performance of `meilisearch/tests/index/create_index.rs`. The tests run locally, if they fail in the CI I'll try to fix them
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Timon Jurschitsch <timon.jurschitsch@gmail.com>
4963: test: improve performance of delete_index.rs r=curquiza a=DerTimonius
# Pull Request
## Related issue
related to #4840
## What does this PR do?
This PR follows the instructions in #4840 and improves the performance of `meilisearch/tests/index/delete_index.rs`. The tests run locally, if they fail in the CI I'll try to fix them
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Timon Jurschitsch <timon.jurschitsch@gmail.com>
4971: update arroy r=dureuill a=irevoire
# Pull Request
Fix part of https://github.com/meilisearch/meilisearch/issues/3715
## What does this PR do?
- Update arroy to the latest version, most change are maintenance changes
- The performances of adding vectors to arroy should slightly improve
- Forward the build cancellation function to arroy so it can stop building trees when we have to stop an indexing process
Co-authored-by: Tamo <tamo@meilisearch.com>
We are now computing the prefix FST and a prefix delta in the Merger thread,
after all the databases are written, the main thread will recompute the prefix databases based on the prefix delta without needing any grenad temporary file anymore
4930: Return `UserError::InvalidDocumentId` for primary keys with a length greater than 512 bytes r=curquiza a=flevi29
# Pull Request
## Related issue
Fixes#4843
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: F. Levi <55688616+flevi29@users.noreply.github.com>
4953: Move the multi arroy index logic to the arroy wrapper r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4948
## What does this PR do?
- Make the `ArroyWrapper` we introduced in the last PR handle all the embedded for a specific docid itself.
Co-authored-by: Tamo <tamo@meilisearch.com>
4954: Fix bench by adding embedder r=ManyTheFish a=dureuill
Fix benchmark workloads following breaking change on embedders
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4943: Correct broken links in README r=curquiza a=iornstein
# Pull Request
## Related issue
Fixes#4942
## What does this PR do?
- Corrects some broken links in the README. My suspicion is that some of these documentation articles were moved around without someone updating links in the README.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)? _(well the contributing guidelines led me to create an issue first)_
- [x] Have you read the contributing guidelines? _yes_
- [x] Have you made sure that the title is accurate and descriptive of the changes? _yes_
Thank you so much for contributing to Meilisearch!
Co-authored-by: Ian Ornstein <ian.ornstein@gmail.com>
4941: Implement the binary quantization in meilisearch r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4873
## What does this PR do?
- Add a settings for the binary quantization
- Once enabled, the bq cannot be disabled
TODO:
- [ ] Missing a bunch of tests
Co-authored-by: Tamo <tamo@meilisearch.com>
4945: Add swedish in default pipelines r=dureuill a=ManyTheFish
# Summary
## Fix Swedish support
In Swedish the characters `å`/`ä`/`ö` are completely different than `a` or `o` and should not be normalized as the same character.
because the Swedish specialized pipeline was not activated by default, these characters were normalized even with the settings:
```json
{
"localizedAttributes": [ { "locales": ["swe"], "attributePatterns": ["*"] } ]
}
```
## Update Charabia adding German support
German segmentation will now be activated using the setting:
```json
{
"localizedAttributes": [ { "locales": ["deu"], "attributePatterns": ["*"] } ]
}
```
# TODO
- [x] Activate Swedish Pipeline
- [x] Add a test to avoid future regressions
- [x] Update Charabia
Co-authored-by: ManyTheFish <many@meilisearch.com>
4939: Introduce the `STARTS WITH` filter operator r=irevoire a=Kerollmops
This PR fixes#4872 by introducing the `STARTS WITH` filter operator and gating it under the _contains filter_ experimental feature along with the `CONTAINS` one. I also updated [the experimental feature discussion page](https://github.com/orgs/meilisearch/discussions/763).
Co-authored-by: Clément Renault <clement@meilisearch.com>
4929: Add facets support to federated r=Kerollmops a=dureuill
# Pull Request
## Related issue
- Fixes#4932 (sprint issue)
- Fixes #4913 (user-opened issue)
## What does this PR do?
See [public usage](https://meilisearch.notion.site/v1-11-Federated-search-59b30e03383c40729d7541a3dffb0069)
> [!CAUTION]
> This PR introduces a 🚨**breaking change**🚨: `queries.facets` when `federation` is present and non-`null` is now **an error**
### Implementation standpoint:
- Facet distribution: fix issue where truncated facet distribution would have a wrong order
- facet distribution: implement Display for OrderBy
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4937: Support iso 639 1 r=ManyTheFish a=ManyTheFish
# Pull Request
## Related issue
Fixes#4827
## What does this PR do?
- Add iso-639-1 variants to the Locales enum
- Convert iso-639-1 into iso-639-3
Co-authored-by: ManyTheFish <many@meilisearch.com>
4936: Update version for the next release (v1.11.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4912: Allow Meilitool to dumplessly, offline upgrade v1.9 -> v1.10 in some conditions r=Kerollmops a=dureuill
- bail early if the DB contains at least 1 REST embedder, providing the list of detected REST embedders, and without modifying the DB
- Might depend on the feature set that meilitool was compiled with and the featureset that the Meilisearch that created the DB was compiled with 💀. In case of runtime error, try again with a different feature set (passing or not passing `-p meilitool` when building after a `cargo clean`)
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4888: bring back v1.10.0 into main r=Kerollmops a=ManyTheFish
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
4845: Fix perf regression facet strings r=ManyTheFish a=dureuill
Benchmarks between v1.9 and v1.10 show a performance regression of about x2 (+3dB regression) for most indexing workloads (+44s for hackernews).
[Benchmark interpretation in the engine weekly meeting](https://www.notion.so/meilisearch/Engine-weekly-4d49560d374c4a87b4e3d126a261d4a0?pvs=4#98a709683276450295fcfe1f8ea5cef3).
- Initial investigation pointed to #4819 as the origin of the regression.
- Further investigation points towards the hypernormalization of each facet value in `extract_facet_string_docids`
- Most of the slowdown is in `normalize_facet_strings`, and precisely in `detection.language()`.
This PR improves the situation (-10s compared with `main` for hackernews, so only +34s regression compared with `v1.9`) by skipping normalization when it can be skipped.
I'm not sure how to fix the root cause though. Should we skip facet locale normalization for now? Cc `@ManyTheFish`
---
Tentative resolution options:
1. remove locale normalization from facet. I'm not sure why this is required, I believe we weren't doing this before, so maybe we can stop doing that again.
2. don't do language detection when it can be helped: won't help with the regressions in benchmark, but maybe we can skip language detection when the locales contain only one language?
3. use a faster language detection library: `@Kerollmops` told me about https://github.com/quickwit-oss/whichlang which bolsters x10 to x100 throughput compared with whatlang. Should we consider replacing whatlang with whichlang? Now I understand whichlang supports fewer languages than whatlang, so I also suggest:
4. use whichlang when the list of locales is empty (autodetection), or when it only contains locales that whichlang can detect. If the list of locales contains locales that whichlang *cannot* detect, **then** use whatlang instead.
---
> [!CAUTION]
> this PR contains a commit that adds detailed spans, that were used to detect which part of `extract_facet_string_docids` was taking too much time. As this commit adds spans that are called too often and adds 7s overhead, it should be removed before landing.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
4864: Don't remove facet value when multiple original values map to the same normalized value r=ManyTheFish a=dureuill
# Pull Request
## Related issue
Fixes#4860
> [!WARNING]
> This PR contains a fix to the immediate issue, but it looks like the underlying data model is faulty: there is only one possible "original" value for each normalized value in a facet of a document, while because of array values (or manually written nested fields, if you're evil), it is technically possible to have multiple, distinct original values mapping to the same normalized value.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4861: Make sure the index scheduler never stops running r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4748
## What does this PR do?
- Whatever happens, we always try to process tasks once every minute (if no tasks are enqueued that's practically free)
Co-authored-by: Tamo <tamo@meilisearch.com>
4858: also intersect the universe for searchOnAttributes r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#4857
## What does this PR do?
- intersect with the universe (which does not contain the filtered out ids) when looking up documents for words, even when using `searchOnAttributes`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4846: Add OpenAI tests r=dureuill a=dureuill
# Pull Request
## Related issue
Part of fixing #4757
## What does this PR do?
- OpenAI embedder: don't pass apiKey when it is empty (slightly improves error messages)
- rest embedder and rest-based embedders: specialize the authorization denied error message depending on the configuration source
- fix existing tests
- Adds assets containing prerecorded texts to embed and the embeddings obtained from OpenAI
- Adds an asset containing a tokenized long document and the embedding obtained from OpenAI for this token
- Uses the wiremock crate to mock the OpenAI API: parse the openai request, lookup the response in assets, craft an openai response
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4839: In prometheus metrics return the route pattern instead of the real route when returning the HTTP requests total r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4825
## What does this PR do?
- return the route pattern instead of the real route when returning the HTTP requests total
Co-authored-by: Tamo <tamo@meilisearch.com>
4853: Fix rhai deletion r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#4849
## What does this PR do?
- insert inside of the bitmap instead of pushing into it.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4850: Use a fixed date format regardless of features r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#4844
## What does this PR do?
Given the following script:
```
cargo run -- --db-path meili.ms
sleep 3
curl -s -X POST http://127.0.0.1:7700/indexes -H 'Content-Type: application/json' --data-binary '{"uid": "movies", "primaryKey": "id"}'
sleep 3
cargo run -p meilisearch --db-path meili.ms
sleep 3
curl -s -X POST http://127.0.0.1:7700/indexes/movies/search -H 'Content-Type: application/json' --data-binary '{}'
```
- Before this PR, the final search returns a decoding error.
- After this PR, the search completes successfully
### Technical standpoint
This PR fixes two locations where the formatting of dates were dependent on the feature set of the `time` crate.
1. The `IndexStats` had two fields without the serialization format specified
2. More subtly, the index dates (`createdAt,` `updatedAt`) were using value remapping in the main DB to `SerdeJson<OffsetDateTime>`, which was using whatever default format was available. This was fixed by creating a local `OffsetDateTime` wrapper that would specify the serialization format
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4836: Attach declared localized-attributes subroutes r=dureuill a=dureuill
RC.0 unexpectedly doesn't contain the `GET /indexes/{indexUid}/localized-attributes` and `PUT /indexes/{indexUid}/localized-attributes` subroute.
This PR makes them available.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
4808: Make the tests run faster r=irevoire a=irevoire
## Index-Scheduler
### Only check the consistency of the index-scheduler on snapshots when running in release mode
This saves 12s on the tests, and since the tests run in release mode in the CI, we don't lose any information.
From 28s to 16s
### We were snapshotting the index for no reason in `advance_till`, I removed this call
This saved an additional 8s on the tests, going from 16s to 8s.
----
After these two optimizations, the test suite as a whole executes 14% quicker
## Meilisearch integration tests
While profiling this test suite, nothing stands out. The only noticeable thing is that we're losing most of our time creating and dropping threads.
I made the theory that by sharing a single common instance between all integrations tests I would gain some time again.
In 355a7acd1c I saved another 15s by only testing this theory on the module that tests the error messages.
But we can do it on many more tests. **We must take care of not making any test flaky, though**.
## Use two indexing threads
By moving from one to two indexing threads, we gain an additional 30% in performance.
# Conclusion
## Before
The execution of the test suite was taking around:
- 4m40s on my computer
- 15 minutes on the debug CI with cache
- 29 minutes on the Windows CI with cache
## After
The execution of the test suite is taking around:
- 2m20 on my computer
- 8 minutes on the debug CI with cache
- 29 minutes on the Windows CI with cache
## This means the test suite should now run ~50% faster on your computer; the CI may report errors twice faster, but we'll still wait for ~the same amount of time to merge a PR
Co-authored-by: Tamo <tamo@meilisearch.com>
4830: Use the dtolnay's Rust Toolchain r=dureuill a=Kerollmops
Fixes the CI by using another rust-toolchain GitHub repo.
Note: the [helix-editor/rust-toolchain repository](https://github.com/helix-editor/rust-toolchain) has been deleted so we moved to the [dtolnay/rust-toolchain](https://github.com/dtolnay/rust-toolchain) one. However, the dtolnay's one doesn't support `rust-toolchain.toml` and the version is directly in the rust-toolchain@version. We keep the `rust-toolchain.toml` for local builds only.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4815: Rest embedder api mk2 r=ManyTheFish a=dureuill
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4756
- [x] [REST API parameter names and behavior are unclear](https://github.com/meilisearch/documentation/pull/2824#issuecomment-2124073720)
- unclear names are removed. There remain only two parameters: `request`, a template of what Meilisearch's request to the embedding server should be, and `response`, a template of what the embedding server's response to Meilisearch should look like
- [x] [Bad error message or bad default value when we don't specify the `query` parameter](85d8455c11/meilisearch/tests/vector/rest.rs (L105-L140))
- The replacement for `query`, which is `request`, is now a mandatory parameter. Omitting it will result in the following error message : "`.embedders.rest`: Missing field `request` (note: this field is mandatory for source rest)", which is clear
- [x] [Bad error message when both `pathToEmbeddings` and `embeddingObject` are missing](2141cb3b69/meilisearch/tests/vector/rest.rs (L142-L178))
- These parameters no longer exist. Now, the point of extraction is given directly by the location of an `{{embedding}}` placeholder in the `response` parameter.
- [x] [Unexpected error when we don't specify both `pathToEmbeddings` and `embeddingObject` (only once should be required)](2141cb3b69/meilisearch/tests/vector/rest.rs (L180-L260))
- These parameters no longer exist. Now, the point of extraction is given directly by the location of an `{{embedding}}` placeholder in the `response` parameter.
- [x] [Should not panic when the dimensions specified do not work with the model](2141cb3b69/meilisearch/tests/vector/rest.rs (L262-L299))
- This no longer panics, instead returns "While embedding documents for embedder `rest`: runtime error: was expecting embeddings of dimension `2`, got embeddings of dimensions `3`"
- [x] [Be more flexible on the type of data that is accepted](https://github.com/meilisearch/meilisearch/issues/4757#issuecomment-2201948531)
- [x] Always accept arrays of embeddings even if `inputType` is set to `text`
- This is controlled by the repeat placeholder `"{..}"`, an array of embeddings can be configured even if the input is not in an array.
- [x] Accept arrays of result at the root level and texts/array of text at the root level.
- doable with `request: "{{text}}"` and `response: "{{embedding}}"` or `response: ["{{embedding}}"]` (see test `vector::rest::server_raw`)
## What does this PR do?
- [See public usage](https://meilisearch.notion.site/v1-10-AI-search-changes-737c9d7d010d4dd685582bf5dab579e2#8de842673ffa4a139210094a89c1ec3e)
- Add new `milli::vector::json_template` module to parse JSON templates with an injection placeholder and a repeat placeholder
- Change rest embedder to use two JSON templates
- Change ollama and openai embedders to use the new rest embedder
- Update settings
- Update and add tests
## Breaking change
> [!CAUTION]
> This PR is a breaking change to the REST embedder.
> Importing a dump containing a REST embedder configuration will fail in v1.10 with an error: "Error: unknown field `query`, expected one of `source`, `model`, `revision`, `apiKey`, `dimensions`, `documentTemplate`, `url`, `request`, `response`, `distribution` at line 1 column 752".
Upgrade procedure:
1. Remove any embedder with source "rest"
2. Create a dump
3. Import that dump in a v1.10
4. Re-add any removed embedder, using the new settings.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Louis Dureuil <louis.dureuil@xinra.net>
Co-authored-by: Tamo <tamo@meilisearch.com>
4822: HuggingFace: Clearer error message when a model is not supported r=Kerollmops a=dureuill
# Pull Request
## Related issue
Context: <https://github.com/meilisearch/meilisearch/discussions/4820>
## What does this PR do?
- Improve error message when a model configuration cannot be loaded and its "architectures" field does not contain "BertModel"
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4817: Update version for the next release (v1.10.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4812: Allow `MEILI_NO_VERGEN` env var to skip vergen r=irevoire a=dureuill
- vergen checks the state of the `.git` directory to embed commit information into the `meilisearch` binary and the `cargo xtask bench` invocations.
- This check unfortunately results in too many recompilation of the `meilisearch` binary.
- This PR allows skipping vergen when the `MEILI_NO_VERGEN` variable is present in the environment
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4805: Log the time to index a batch of task r=Kerollmops a=irevoire
This was proposed by `@qdequele` in a private conversation and I think it’s a nice addition.
Co-authored-by: Tamo <tamo@meilisearch.com>
4769: Federated search r=ManyTheFish a=dureuill
# Pull Request
## Related issue
Fixes#4747
[Usage](https://meilisearch.notion.site/v1-10-federated-search-698dfe36ab6b4668b044f735fb40f0b2)
## What does this PR do?
- multi-search now allows a top-level federation object. When not `null`, the results of multi-search are modified to be a single list of results rather than a list of a list of results
- changed lifetimes around tokenizer et al. to be able to make hits one by one rather than using a vector
- adds `roaring` to Meilisearch itself. As the federated search happens at the Meilisearch level (reuses the search functions declared at the Meilisearch level + merge happens after the hits were created), `RoaringBitmap`s are needed to track the candidates: hits that were seen, all candidates.
- Refactor `make_hits` to allow for an individual, optimized `make_hit`
- Score details comparison no longer fail when sorting on different field names or target point (for geo)
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4787: Add index exists function in index_scheduler which stops opening indexes to only check if they exist. r=Kerollmops a=Karribalu
# Pull Request
## Related issue
Fixes#4784
## What does this PR do?
- Added index_exists function in the index_scheduler.
- Resolved opening indexes to only check if they exist.
- Made changes to existing tests to test this function.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: karribalu <karri.balu123456@gmail.com>
4626: Edit Documents with Rhai r=ManyTheFish a=Kerollmops
This PR introduces a first version of [the _Update Documents with Function_ (internal)](https://www.notion.so/meilisearch/Update-Documents-by-Function-45f87b13e61c4435b73943768a490808). It uses [the Rhai programming language](https://rhai.rs/) to let users express the modifications they want apply.
You can read more about the way to use this functions on [the Usage PRD Page](https://meilisearch.notion.site/Edit-Documents-with-Rhai-0cff8fea7655436592e7c8a6de932062?pvs=25). The [prototype is available](https://github.com/meilisearch/meilisearch/actions/runs/9038384483) through Docker by using the following command:
```
docker run -p 7700:7700 -v $(pwd)/meili_data:/meili_data getmeili/meilisearch:prototype-edit-documents-with-rhai-3
```
## TODO
- [x] Support the `DocumentEdition` task in dumps.
- [x] Remove the unwraps and panics.
- [x] Improve error codes for the `function` parameter.
- [x] [Update Rhai to v1.19.0](https://github.com/rhaiscript/rhai/releases/tag/v1.19.0) 🚀
- [x] Make it an experimental feature (only restrict the HTTP calls).
- [x] It must be possible not to send a context.
- [x] Rebase on main.
- [x] Check that the script cannot do any io.
- [x] ~Introduce a `Documents.edit` action or~ require the `Documents.all` action.
- [x] Change the `editionCode` to the clearer `function` field name in the tasks.
- [x] Support a user provided context and maybe more (but keep function execution isolated for reproducibility).
- [x] Support deleting documents when the `doc` is `()` (nil, null).
- [x] Support canceling document edition.
- [x] Multithread document edition by using rayon (and [rayon-par-bridge](https://docs.rs/rayon-par-bridge/latest/rayon_par_bridge/)).
- [x] Limit the number of instruction by function execution.
- [ ] ~Expose the limit of instructions in the settings.~ Not sure, in fact.
- [x] Ignore unmodified documents in the tasks count.
- [x] Make the `filter` field optional (not forced to be `null`).
Co-authored-by: Clément Renault <clement@meilisearch.com>
4717: Implement intersection at end on the search pipeline r=Kerollmops a=Kerollmops
This PR is akin to #4713 and #4682 because it uses the new RoaringBitmap method to do the intersections directly on the serialized bytes for the bytes LMDB/heed returns. More work related to this issue can be done, and I listed that in #4780.
Running the following command shows where we use bitand/intersection operations and where we can potentially apply this optimization.
```sh
rg --type rust --vimgrep '\s&[=\s]' milli/src/search
```
Co-authored-by: Clément Renault <clement@meilisearch.com>
4786: Update dependencies r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes#4753
## What does this PR do?
- Update all dependencies except rustls
- [x] Release charabia
- [x] Update charabia
- [x] Double check that the docker build works after updating charabia
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
4781: Correct apk usages in Dockerfile r=curquiza a=PeterDaveHello
# Pull Request
## Related issue
No issue was created because this is very trivial.
## What does this PR do?
Correct apk usages in Dockerfile
There is no need to use apk with `update` or `--update-cache` when `--no-cache` is used, which will make sure the index is the latest, and leave no temporary files behind.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Peter Dave Hello <hsu@peterdavehello.org>
There is no need to use apk with `update` or `--update-cache` when `--no-cache` is used, which will make sure the index is the latest, and leave no temporary files behind.
4774: Rename the sortable into the filterable movies workload r=dureuill a=Kerollmops
Fixes the workload name of one movie searchable.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4773: New workload to ignore the initial compression phase r=dureuill a=Kerollmops
This PR introduces a new workload to ignore the time spent initially compressing the documents.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4762: Add search benchmarks r=Kerollmops a=dureuill
# Pull Request
## What does this PR do?
- [x] Modifies `xtask bench` so that workloads support an optional `target` argument. `target` defaults to `indexing::=trace`
- [x] Refactor the spans in the search to offer finer profiling granularity
- [x] Add search workloads
- [x] Updates documentation in `BENCHMARKS.md`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4754: bring back v1.9.0 changes to main r=irevoire a=ManyTheFish
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
4746: Fix hybrid search limit offset r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#4745
## What does this PR do?
- Apply offset and limit to the keyword search results when they are returned early.
- Add a test that is initially failing, and then passes
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4740: Make `embeddings` optional and improve error message for `regenerate` r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4741
## What does this PR do?
- Make the `embeddings` parameter optional when manually specifying embeddings for an embedder
- Adds a lot of tests around malformed `_vectors.embedder` objects
- Use `deserr` to deserialize the `_vectors.embedder` field, improving error messages
Co-authored-by: Tamo <tamo@meilisearch.com>
4731: Fix the missing geo distance when one or both of the lat / lng are string r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4193
## What does this PR do?
- Properly extract the lat / lng when one or both of them are string
- Add a test
Co-authored-by: Tamo <tamo@meilisearch.com>
4724: Improve tenant token error messages r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes #4727
## What does this PR do?
- Introduce a bunch of new error messages around tenant tokens
- Ignore the error messages in most tests that were doing for loop over multiple kinds of errors
- Introduce new tests that specifically test these error messages
Co-authored-by: Tamo <tamo@meilisearch.com>
4703: Update yaup r=ManyTheFish a=irevoire
There was a bug in `yaup` where serializing a structure with an array would give you a wrong query parameter.
Now, yaup is also in charge of sending the initial `?` before the query parameters.
Co-authored-by: Tamo <tamo@meilisearch.com>
4706: specify the rust toolchain r=irevoire a=irevoire
The action we were using was not working with the `rust-toolchain.toml` file.
But the repository is not maintained anymore.
While looking for a solution, I found out that [helix](https://github.com/helix-editor/rust-toolchain) solved the issue on their side by forking the repo and adding a few fixes. That's what I use currently, but I don't know if it's a sustainable solution in the long term
Co-authored-by: Tamo <tamo@meilisearch.com>
4716: Fix bad http status and error message on wrong payload r=irevoire a=Karribalu
# Pull Request
## Related issue
Fixes#4698
## What does this PR do?
- Fixes bad http status when bad payload with gzip Content-Encoding
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: karribalu <karri.balu123456@gmail.com>
4730: fix a possibly flaky test r=irevoire a=irevoire
On slow CI, it was possible for a document addition to _not_ to be processed and then get autobatched with an index deletion, which changed their task summary details in the end.
Now, I wait for the task to finish, and the result will always be the same
Co-authored-by: Tamo <tamo@meilisearch.com>
4725: Store primary key as String when Number exceeds i64 range r=irevoire a=JWSong
# Pull Request
## Related issue
Fixes#4696
## What does this PR do?
- When a Number value exceeding the range of i64 is received as a primary key, it will be stored as a String.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: JWSong <thdwjddn123@gmail.com>
4665: Add missing Korean support r=ManyTheFish a=junhochoi
Some configuration is missing `korean` features and add a test case in `milli/src/search/mod.rs`.
# Pull Request
## Related issue
#3443#3882
## What does this PR do?
- Improvement on enabling Korean support
Inspired by the work (#3882) I tried to enable Korean features but have found some missing configurations.
This PR is add those missing configs (mostly Cargo.toml) and added one test case.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Junho Choi <jh.choi@catenoid.net>
4722: Grow by 1TB instead of 1MB r=dureuill a=dureuill
When an index reaches 1TB, increases its size by 1TB rather than 1MB
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4723: Fixes for Rust v1.79 r=ManyTheFish a=dureuill
cherry-picked from the `release-v1.9.0` branch
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4715: Build all arroy indexes that need to be built r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4588
## What does this PR do?
- Update arroy
- Ensure we always rebuild the arroy indexes that need to be built
Co-authored-by: Tamo <tamo@meilisearch.com>
4713: Speed up facet distribution r=ManyTheFish a=Kerollmops
This PR is akin to #4682, but this time, the same logic is applied to the facets. Bitmaps are not decoded, and we do an intersection on the bytes with the search candidates instead of materializing the RoaringBitmap to destroy it just after the operation.
A prospect raised some slow requests when performing facet searches, and I found out that the disk optimization intersection wasn't performed on the facets.
Co-authored-by: Clément Renault <clement@meilisearch.com>
This Pull Request adds two new interesting demos to a brand new list, which replaces the short _Try it_ text just below the Where2Watch showcase image hoping people will notice them.
4693: Introduce distinct attributes at search time r=irevoire a=Kerollmops
This PR fixes#4611.
### To Do
- [x] Remove the `distinguishableAttributes` settings (not even a commit about that).
- [x] Use the `filterableAttributes` to be able to use the `distinct` parameter at search.
- [x] Work on the errors and make tests.
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
4649: Don't store the vectors in the documents database r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4607
## What does this PR do?
- Ensure that anything falling under `_vectors` is NOT searchable, filterable or sortable
- [x] per embedder, add a roaring bitmap of documents that provide "userProvided" embeddings
- [x] in the indexing process in extract_vector_points, set the bit corresponding to the document depending on the "userProvided" subfield in the _vectors field.
- [x] in the document DB in typed chunks, when writing the _vectors field, remove all keys corresponding to an embedder
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
- when the feature is disabled, documents are never modified
- when the feature is enabled and `retrieveVectors` is disabled, `_vectors` is removed from documents
- when the feature is enabled and `retrieveVectors` is enabled, vectors from the vectors DB are merged with `_vectors` in documents
Additionally `_vectors` is never displayed when the `displayedAttributes` list does not contain either `*` or `_vectors`
- fixed an issue where `_vectors` was not injected when all vectors in the dataset where always generated
4682: Speed Up Filter ANDs operations r=Kerollmops a=Kerollmops
This PR fixes#4659 and improves the way we do AND operations by using the latest [RoaringBitmap feature to do intersections with serialized bitmaps](https://github.com/RoaringBitmap/roaring-rs/pull/281). Doing so drastically reduces the time spent reading, copying bytes in memory to use and keep a subset of the containers in the bitmap.
### Some Example Results
With a 45M documents dataset running on a good NVMe. This example filter was taking 77ms and with this PR only 13ms (6x speedup):
```sql
artist = 'The Beatles' AND (duration 150 TO 500 OR duration NOT EXISTS) AND genres IN [Rock, 'Rock and Roll'] AND rating > 4 AND released_year 1960 TO 1990
```
By reordering the filter AND clauses we can reach a constant 8ms execution time. However, note that it is a manual operation. On the other side the previous filter pipeline is still at a constant 45ms execution time with this filter. (6x speedup)
```sql
artist = 'The Beatles' AND genres IN [Rock, 'Rock and Roll'] AND released_year 1960 TO 1990 AND (duration 150 TO 500 OR duration NOT EXISTS)
```
### To Do
- [x] Rebase on `release-v1.9.0`.
- [ ] ~Skip branches of the facet/filter tree when nothing is in common with the universe~ slower this way.
- [x] When the universe is required use the universe given in parameter if possible.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4691: Add june 11th webinar banner r=curquiza a=Strift
# Pull Request
This PR adds a banner in the README to promote tomorrow's webinar event.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Strift <laurent@meilisearch.com>
4689: Bring back changes from v1.8.2 into v1.9.0 r=curquiza a=dureuill
Co-authored-by: dureuill <dureuill@users.noreply.github.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
4681: Fix concurrency issue r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#4654
## What does this PR do?
- Asynchronously drop permits
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4688: Update version for the next release (v1.8.2) in Cargo.toml r=dureuill a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: dureuill <dureuill@users.noreply.github.com>
4684: Update Charabia v0.8.11 r=irevoire a=ManyTheFish
# Update Charabia v0.8.11
### Adds a new normalizer to normalize œ to oe and æ to ae
Now search words containing `œ` or `æ` will be retrieved using `oe` or `ae`, like `Daemon` <=> `Dæmon`
### Fix: make `chinese-normalization-pinyin` feature flag compile
Fixes#4629
Co-authored-by: ManyTheFish <many@meilisearch.com>
4680: Speedup additional searchables r=Kerollmops a=ManyTheFish
Fixes#4492.
## To Do
- [x] Do not call the `InnerSettingsDiff::only_additional_fields` function too many times
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
4656: Adding a new `searchableAttribute` no longer re-index all the attributes r=ManyTheFish a=Kerollmops
Fixes#4492.
## To Do
- [x] Do not call the `InnerSettingsDiff::only_additional_fields` function too many times
- [ ] Add tests
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
4664: Update README.md r=curquiza a=tpayet
Add hybrid & semantic as a feature
# Pull Request
## Related issue
Fixes #<issue_number>
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Thomas Payet <thomas@meilisearch.com>
4657: Update version for the next release (v1.9.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4655: Remove `exportPuffinReport` experimental feature r=Kerollmops a=Kerollmops
This PR fixes#4605 by removing every trace of Puffin. Puffin is a great tool, but we use a better approach to measuring performance.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4646: Reduce `Transform`'s disk usage r=Kerollmops a=Kerollmops
This PR implements what is described in #4485. It reduces the number of disk writes and disk usage.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4633: Allow to mark vectors as "userProvided" r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#4606
## What does this PR do?
[See usage in PRD](https://meilisearch.notion.site/v1-9-AI-search-changes-e90d6803eca8417aa70a1ac5d0225697#deb96fb0595947bda7d4a371100326eb)
- Extends the shape of the special `_vectors` field in documents.
- previously, the `_vectors` field had to be an object, with each field the name of a configured embedder, and each value either `null`, an embedding (array of numbers), or an array of embeddings.
- In this PR, the value of an embedder in the `_vectors` field can additionally be an object. The object has two fields:
1. `embeddings`: `null`, an embedding (array of numbers), or an array of embeddings.
2. `userProvided`: a boolean indicating if the vector was provided by the user.
- The previous form `embedder_or_array_of_embedders` is semantically equivalent to:
```json
{
"embeddings": embedder_or_array_of_embedders,
"userProvided": true
}
```
- During the indexing step, the subfields and values of the `_vectors` field that have `userProvided` set to **false** are added in the vector DB, but not in the documents DB: that means that future modifications of the documents will trigger a regeneration of that particular vector using the document template.
- This allows **importing** embeddings as a one-shot process, while still retaining the ability to regenerate embeddings on document change.
- The dump process now uses this ability: it enriches the `_vectors` fields of documents with the embeddings that were autogenerated, marking them as not `userProvided`. This allows importing the vectors from a dump without regenerating them.
### Tests
This PR adds the following tests
- Long-needed hybrid search tests of a simple hf embedder
- Dump test that imports vectors. Due to the difficulty of actually importing a dump in tests, we just read the dump and check it contains the expected content.
- Tests in the index-scheduler: this tests that documents containing the same kind of instructions as in the dump indexes as expected
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4648: Update version for the next release (v1.8.1) in Cargo.toml r=ManyTheFish a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: ManyTheFish <ManyTheFish@users.noreply.github.com>
4642: Index the _geo fields when changing the setting while there is already documents in the DB r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4640
Fixes https://github.com/meilisearch/meilisearch/issues/4628
## What does this PR do?
- Add an integration test that first indexes the document and then changes the settings
- Fix `extract_geo_point` by detecting if the `_geo` field has been faceted in this setting change and index all documents
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
4644: Revert "Stream documents" and keep heed+arroy to the latest verion r=Kerollmops a=irevoire
Reverts meilisearch/meilisearch#4544
Fixes https://github.com/meilisearch/meilisearch/issues/4641
I didn’t realize that some http clients were not handling chunked http requests like you would expect (if you ask the body, it gives you the body), which made the previous PR breaking.
There is no way to provide a good fix to the issue we initially wanted to fix without breaking meilisearch and that’s not planned for now.
Co-authored-by: Tamo <irevoire@protonmail.ch>
Co-authored-by: Tamo <tamo@meilisearch.com>
4544: Stream documents r=curquiza a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4383
### Perf
2M hackernews:
main:
Time to retrieve: 7s
RAM consumption: 2+GiB
stream:
Time to retrieve: 4.7s
RAM consumption: Too small
Co-authored-by: Tamo <tamo@meilisearch.com>
4631: Split the field id map from the weight of each fields r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4484
## What does this PR do?
- Make the (internal) searchable fields database always contain the searchable fields (instead of None when the user-defined searchable fields were not defined)
- Introduce a new « fieldids_weights_map » that does the mapping between a fieldId and its Weight
- Ensure that when two searchable fields are swapped, the field ID map doesn't change anymore (and thus, doesn't re-index)
- Uses the weight instead of the order of the searchable fields in the attribute ranking rule at search time
- When no searchable attributes are defined, make all their weights equal to zero
- When a field is declared as searchable and contains nested fields, all its subfields share the same weight
## Impact on relevancy
### When no searchable attributes are declared
When no searchable attributes are declared, all the fields have the same importance instead of randomly giving more importance to the field we've encountered « the most early » in the life of the index.
This means that before this PR, send the following json:
```json
[
{ "id": 0, "name": "kefir", "color": "white" },
{ "id": 1, "name": "white", "last name": "spirit" }
]
```
Would make the field `name` more important than the field `color` or `last name`.
This means that searching for `white` would make the document `1` automatically higher ranked than the document `0`.
After this PR, all the fields have the same weight, and none are considered more important than others.
### When a nested field is made searchable
The second behavior change that happened with this PR is in the case you're sending this document, for example:
```json
{
"id": 0,
"name": "tamo",
"doggo": {
"name": "kefir",
"surname": "le kef"
},
"catto": "gromez"
}
```
Previously, defining the searchable attributes as: `["tamo", "doggo", "catto"]` was actually defining the « real » searchable attributes in the engine as: `["tamo", "doggo", "catto", "doggo.name", "doggo.surname"]`, which means that `doggo.name` and `doggo.surname` were _NOT_ where the user expected them and had completely different weights than `doggo`.
In this PR all the weights have been unified, and the « real » searchable fields look like this:
```json
[ "tamo", "doggo", "doggo.name", "doggo.surname", "catto"]
^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^
Weight 0 Weight 1 Weight 2
Co-authored-by: Tamo <tamo@meilisearch.com>
4624: Add "precommands" to benchmark r=dureuill a=dureuill
# Pull Request
## Related issue
Helps for https://github.com/meilisearch/meilisearch/issues/4493
## What does this PR do?
- Add support for precommands for cargo xtask bench
- update benchmark docs
- update workload files
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4621: Bring back changes from v1.8.0 into main r=curquiza a=curquiza
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
4619: Use http path pattern instead of full path in metrics r=irevoire a=gh2k
# Pull Request
## Related issue
Fixes#3983
## What does this PR do?
- This records only the HTTP pattern in metrics instead of the full path
An alternative solution was proposed in #4145, but this doesn't really fix the root cause of the issue. The problem I'm experiencing at my end is that by using the full path, the number of labels is far too high to be useful. It is normal practice to use the path with variable placeholders, instead of the fully-expanded path.
The example given in the ticket was endpoints under `/tasks`, but this can also be a very significant problem under `/indexes/{index-uid}/documents`. e.g.:
<img width="1510" alt="Screenshot 2024-05-03 at 12 14 36" src="https://github.com/meilisearch/meilisearch/assets/6530014/1df2ec19-5f69-4164-90d2-f65c59f9b544">
This patch replaces the fully-expanded path with the matched pattern.
The linked PR also mentions paths under other routes, e.g. `/static`, but this feels like a separate concern and these can be stripped out at the Prometheus end by filters if they are unwanted. The most important thing is to make the paths usable so that we can still get stats on e.g. the number of document deletes we see.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Simon Detheridge <s@sd.ai>
Co-authored-by: Tamo <tamo@meilisearch.com>
4617: Destructure `EmbedderOptions` so we don't miss some options r=dureuill a=dureuill
# Pull Request
## Related issue
#4595 was caused by the code not destructuring the embedder options.
## What does this PR do?
This PR adds the missing `url` parameter for ollama, and makes sure similar issue cannot happen in the future
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4597: Fix embeddings settings update r=ManyTheFish a=ManyTheFish
# Pull Request
- add some conditions reducing the work done when changing the settings
- add some benchmarks on embedders
## Related issue
Fixes#4585
Co-authored-by: ManyTheFish <many@meilisearch.com>
4593: Stop crashing when panic occurs in thread pool r=ManyTheFish a=Kerollmops
This PR fixes#4362 by introducing a new boolean to catch panics in the rayon thread pool. The boolean is read after performing the operations in rayon, and the indexation process is stopped. This first version doesn't expose the panic message but marks the task as failed.
The current implementation exposes a `ThreadPoolNoAbort` wrapper. The `rayon::ThreadPool` has been wrapped to check that nothing went wrong after running the `ThreadPool::install` function. An atomic boolean and some `store/load` logic make the system work efficiently.
Before, Meilisearch was completely crashing...
<img width="1563" alt="Capture d’écran 2024-04-22 à 15 49 02" src="https://github.com/meilisearch/meilisearch/assets/3610253/ce114917-a881-4fbb-85df-c195fcf0c7cb">
Now, it handles the panics correctly and marks the task as failed.
<img width="1558" alt="Capture d’écran 2024-04-22 à 15 42 14" src="https://github.com/meilisearch/meilisearch/assets/3610253/8bd031ef-5e8f-4a12-a91e-c823597a2344">
Co-authored-by: Clément Renault <clement@meilisearch.com>
4582: Fix some typos in comments r=curquiza a=writegr
# Pull Request
## Related issue
No
## What does this PR do?
fix some typos in comments
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: writegr <wellweek@outlook.com>
4576: increase the default search time budget from 150ms to 1.5s r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes#4575
## What does this PR do?
- increase the default search time budget from 150ms to 1.5s
Co-authored-by: Tamo <tamo@meilisearch.com>
4581: Always show facet numbers in alpha order in the facet distribution r=ManyTheFish a=Kerollmops
This PR fixes#4559 by making sure that the number facets (facets that come from numbers from the documents) are always displayed in alpha order, even when there is a small amount to display.
The issue was due to some algorithms executed when the number of facet values to display was small. We can see that now, facet values are always displayed correctly.
```json
"facetDistribution": {
"release_year": {
"2010": 1,
"2011": 1,
"2012": 1,
"2013": 1,
"2014": 1,
"2015": 1,
"2016": 1,
"2017": 1,
"2018": 1,
"2019": 19,
"2020": 1,
"2021": 1,
"2022": 1,
"2023": 1,
"2024": 1,
"2025": 1
}
}
```
Co-authored-by: Clément Renault <clement@meilisearch.com>
4580: Update the search logs r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4579
## What does this PR do?
- Update the debug implementation of the search query and search results so it’s way smaller and doesn’t display useless information
Co-authored-by: Tamo <tamo@meilisearch.com>
4568: Fix some typos in comments r=curquiza a=yudrywet
# Pull Request
## Related issue
No
## What does this PR do?
fix some typos in comments
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: yudrywet <yudeyao@yeah.net>
4560: Bring back change from v1.7.5 to main r=curquiza a=irevoire
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: irevoire <irevoire@users.noreply.github.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
4554: Update version for the next release (v1.7.5) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: irevoire <irevoire@users.noreply.github.com>
4548: v1.8 hybrid search changes r=dureuill a=dureuill
Implements the search changes from the [usage page](https://meilisearch.notion.site/v1-8-AI-search-API-usage-135552d6e85a4a52bc7109be82aeca42#40f24df3da694428a39cc8043c9cfc64)
### ⚠️ Breaking changes in an experimental feature:
- Removed the `_semanticScore`. Use the `_rankingScore` instead.
- Removed `vector` in the response of the search (output was too big).
- Removed all the vectors from the `vectorSort` ranking score details
- target vector appearing in the name of the rule
- matched vector appearing in the details of the rule
### Other user-facing changes
- Added `semanticHitCount`, indicating how many hits were returned from the semantic search. This is especially useful in the hybrid search.
- Embed lazily: Meilisearch no longer generates an embedding when the keyword results are "good enough".
- Graceful embedding failure in hybrid search: when doing hybrid search (`semanticRatio in ]0.0, 1.0[`), an embedding failure no longer causes the search request to fail. Instead, only the keyword search is performed. When doing a full vector search (`semanticRatio==1.0`), a failure to embed will still result in failing that search.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4549: Hugging Face embedder improvements r=dureuill a=dureuill
Architectural changes/Internal improvements
### 1. Prefer safetensors weights over pytorch weights when available
safetensors weights are memory mapped, which reduces memory usage of supported models.
### 2. Update candle
Updates candle to `0.4.1`, now targeting crates.io and the tokenizers to `v0.15.2` (still on github).
This might fix https://github.com/meilisearch/meilisearch/issues/4399 thanks to the now included https://github.com/huggingface/candle/issues/1454
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4535: Support Negative Keywords r=ManyTheFish a=Kerollmops
This PR fixes#4422 by supporting `-` before any word in the query.
The minus symbol `-`, from the ASCII table, is not the only character that can be considered the negative operator. You can see the two other matching characters under the `Based on "-" (U+002D)` section on [this unicode reference website](https://www.compart.com/en/unicode/U+002D).
It's important to notice the strange behavior when a query includes and excludes the same word; only the derivative ( synonyms and split) will be kept:
- If you input `progamer -progamer`, the engine will still search for `pro gamer`.
- If you have the synonym `like = love` and you input `like -like`, it will still search for `love`.
## TODO
- [x] Add analytics
- [x] Add support to the `-` operator
- [x] Make sure to support spaces around `-` well
- [x] Support phrase negation
- [x] Add tests
Co-authored-by: Clément Renault <clement@meilisearch.com>
4546: Fix some typos in conments r=curquiza a=redistay
# Pull Request
## What does this PR do?
- fix some typos in conments
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: redistay <wujunjing@outlook.com>
4543: Bring back changes from v1.7.4 into main r=Kerollmops a=dureuill
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: dureuill <dureuill@users.noreply.github.com>
4536: Limit concurrent search requests r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4489
## What does this PR do?
- Adds a « search queue » that limits the number of search requests we can process at the same time and stores search requests to be processed
- Process only one search request per core/thread (we use available_parallelism)
- When the search queue is full, new search requests replace old ones **randomly**. The reason is that:
- If we serve the oldest one first, like Typesense, we give the worst performances to everyone
- If we serve the latest one, it gets too easy to DoS us (you just need to fill the queue with as many search requests as we can process simultaneously to ensure no other request will ever be processed)
- By picking the search request randomly, we give a chance to recent search requests to be processed while ensuring that we can't be owned unless they fill our queue entirely and we start returning errors 5xx
- Adds an experimental parameter to control the size of the queue
- Adds a bunch of tests to ensure the search queue works correctly
- Ensure the loop consuming the search queue is running in the health route and crashes if it’s not the case
Co-authored-by: Tamo <tamo@meilisearch.com>
4532: Add `url` and `api_key` to ollama r=ManyTheFish a=dureuill
See [Usage page](https://meilisearch.notion.site/v1-8-AI-search-API-usage-135552d6e85a4a52bc7109be82aeca42#5c77ef49e78e43388c1d3d5429151357)
### Motivation
- Before this PR, the url for ollama is only read from the environment. This is a needless restriction that will be troublesome in settings where passing an environment variable is complex or impossible (e.g., the Cloud)
- Before this PR, ollama did not support an api_key. While ollama does not natively support API keys, [a common practice](https://github.com/ollama/ollama/issues/849) is to put a publicly accessible ollama server behind a proxy to support authentication.
### Skip changelog
ollama embedder was added to v1.8
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4520: Add automation to create openAPI issue r=dureuill a=curquiza
Create automatically an issue to remind us to update open-api file when opening a milestone
Co-authored-by: curquiza <clementine@meilisearch.com>
4541: Update version for the next release (v1.7.4) in Cargo.toml r=Kerollmops a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: dureuill <dureuill@users.noreply.github.com>
4539: Don't optimize reindexing when fields contain dots r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4525
## What does this PR do?
- Don't try to optimize the amount of reindexing operation when nested fields are used anywhere in:
- the field distribution (e.g. a key actually contains a `.`)
- the old faceted fields
- the new faceted fields
This is because the facet distribution is not reporting on existing nested fields.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4516: Update sprint_issue.md r=Kerollmops a=curquiza
Following decision made about specification
Also
- removed useless parts of the template
- add automatic labels -> better to forget to remove them rather than forgetting to add them (some mistakes happened in the past)
Co-authored-by: Clémentine U. - curqui <clementine@meilisearch.com>
4530: fix: set the histogram bucket boundaries to follow the otel spec r=curquiza a=rohankmr414
# Pull Request
## What does this PR do?
- Fixes the http request duration histogram bucket boundaries to follow the opentelemetry spec, currently the bucket boundaries are too granular and only track latencies below 1s.
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Rohan Kumar <rohankmr414@gmail.com>
4373: feat: add status code label to prometheus http request counter r=irevoire a=rohankmr414
# Pull Request
## What does this PR do?
- This PR adds the `status` label (the value is http status code) to the `meilisearch_http_requests_total` metric.
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Rohan Kumar <rohankmr414@gmail.com>
4526: chore: remove repetitive word r=curquiza a=availhang
# Pull Request
## Related issue
Fixes #<issue_number>
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: availhang <mayangang@outlook.com>
4522: Brings back change to main r=curquiza a=irevoire
# Pull Request
Bring back changes to main
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: irevoire <irevoire@users.noreply.github.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4519: Update version for the next release (v1.7.3) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4466: Implements the search cutoff r=irevoire a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4488
## What does this PR do?
- Adds a cutoff to the bucket sort after 150ms has been spent
- Adds a new setting to customize the default value of 150ms
- When the time is exceeded, we exit early with what we had the time to sort
- If the cutoff has been reached, the search details are updated with a new `Skip` ranking details for the ranking rules that were skipped
- Adds analytics to measure the total number of degraded search requests
- Adds the number of degraded search requests to the Prometheus metrics and Grafana dashboard
- The cutoff **must not** skip the filters; otherwise, we would leak documents to people who don’t have the right to see them
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4513: Revert "Merge remote-tracking branch 'origin/main' into release-v1.7.1" r=Kerollmops a=irevoire
This reverts commit bd74cce86a, reversing changes made to d2f77e88bd.
This commit wasn’t supposed to be merged on the `release-v1.7.1` branch
Co-authored-by: Tamo <tamo@meilisearch.com>
4512: Revert "Revert "Merge remote-tracking branch 'origin/main' into release-v1.7.1"" r=Kerollmops a=irevoire
Reverts meilisearch/meilisearch#4510
This PR was supposed to be merged on `release-v1.7.1` not main 🤦
Co-authored-by: Tamo <irevoire@protonmail.ch>
handles the niche case 🐩 in the hybrid search where:
1. a sort ranking rule is the first rule.
2. the keyword search is skipped at the first rule.
3. the semantic search is not skipped at the first rule.
Previously, we would have the skipped search winning, whereas we want the non skipped one winning.
4510: Revert "Merge remote-tracking branch 'origin/main' into release-v1.7.1" r=Kerollmops a=irevoire
In https://github.com/meilisearch/meilisearch/pull/4502 we merged main into release-v1.7.1 instead of a temporary branch thus we now need to revert this merge commit.
This reverts commit bd74cce86a, reversing changes made to d2f77e88bd.
Co-authored-by: Tamo <tamo@meilisearch.com>
4500: Don't display dimensions as 0 when it is not set r=ManyTheFish a=dureuill
Fixes regression in embedders where `dimensions: 0` was displayed when it hadn't be set for the `openAi` source.
Was breaking a PHP SDK integration test: cbaecb8c55/tests/Settings/EmbeddersTest.php (L28)
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4499: Fix milli link in contributing doc r=curquiza a=mohsen-alizadeh
# Pull Request
## Related issue
Fixes#4498
## What does this PR do?
The milli link in CONTRIBUTING.md targeted the archived milli repository. it has to be changed to target to the milli crate in the main repo
## PR checklist
Please check if your PR fulfills the following requirements:
- [X] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [X] Have you read the contributing guidelines?
- [X] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Mohsen Alizadeh <mohsen@alizadeh.us>
Co-authored-by: Clémentine U. - curqui <clementine@meilisearch.com>
4491: chore: remove repetitive words r=curquiza a=shuangcui
# Pull Request
## Related issue
Fixes #<issue_number>
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: shuangcui <fliter@qq.com>
4483: Workflows: Fix reason param when benches are triggered from a comment. r=irevoire a=dureuill
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4479: Skip reindexing when modifying unknown faceted fields r=dureuill a=Kerollmops
This PR improves Meilisearch's decision to reindex when a faceted field is added to the settings, but not a single document contains this field. It is effectively a waste of time to reindex documents when the engine needs to know a field.
This is related to a conversation [we have with our biggest customer (internal link)](https://discord.com/channels/1006923006964154428/1101213808627830794/1217112918857089187). They have 170 million documents, so reindexing this amount would be problematic.
---
The image is available by using the following Docker command. You can see the advancement of the image's build [on the GitHub CI page](https://github.com/meilisearch/meilisearch/actions/runs/8251688778).
```
docker pull getmeili/meilisearch:prototype-no-reindex-unknown-fields-0
```
Here is the hand-made test that shows that when modifying unknown filterable attributes, here `lol`, it doesn't reindex. However, when modifying the known `genre` field, it does reindex. You can see all that by looking at the time spent processing the update.
```json
{
"uid": 3,
"indexUid": "movies",
"status": "succeeded",
"type": "settingsUpdate",
"canceledBy": null,
"details": {
"filterableAttributes": [
"genres"
]
},
"error": null,
"duration": "PT9.237703S",
"enqueuedAt": "2024-03-12T15:34:26.836083Z",
"startedAt": "2024-03-12T15:34:26.836374Z",
"finishedAt": "2024-03-12T15:34:36.074077Z"
},
{
"uid": 2,
"indexUid": "movies",
"status": "succeeded",
"type": "settingsUpdate",
"canceledBy": null,
"details": {
"filterableAttributes": [
"lol"
]
},
"error": null,
"duration": "PT0.000751S",
"enqueuedAt": "2024-03-12T15:33:53.563923Z",
"startedAt": "2024-03-12T15:33:53.565259Z",
"finishedAt": "2024-03-12T15:33:53.56601Z"
},
{
"uid": 0,
"indexUid": "movies",
"status": "succeeded",
"type": "documentAdditionOrUpdate",
"canceledBy": null,
"details": {
"receivedDocuments": 31944,
"indexedDocuments": 31944
},
"error": null,
"duration": "PT3.120723S",
"enqueuedAt": "2024-02-17T10:35:55.042864Z",
"startedAt": "2024-02-17T10:35:55.043505Z",
"finishedAt": "2024-02-17T10:35:58.164228Z"
}
```
Co-authored-by: Clément Renault <clement@meilisearch.com>
4487: Update version for the next release (v1.7.1) in Cargo.toml r=Kerollmops a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: Kerollmops <Kerollmops@users.noreply.github.com>
4476: Make the `/facet-search` route use the `sortFacetValuesBy` setting r=irevoire a=Kerollmops
This PR fixes#4423 by ensuring that the `/facet-search` route uses the `sortFacetValuesBy` setting.
Note for the documentation team (to be moved in the tracking issue): Using the new `sortFacetValuesBy` setting can slow down the facet-search requests as Meilisearch iterates over the whole list of facet values and computes the count of documents on every entry. That is hardly or even impossible to optimize correctly.
### TODO
- [x] Create a custom HashMap wrapper for the facet `OrderBy` settings.
This wrapper will return the `OrderBy` setting of the facet, if not defined will use the default `*` one, and if not there either (strange) will fall back on the lexicographic one.
- [x] Create a `ValuesCollection` wrapper that implements the logic for the lexicographic and count order by.
- [x] Use it when there is no search query.
- [x] Use it when there is a search query with and without allowed typos.
- [x] Do not change the original logic, only use a wrapper.
- [x] Add tests
Co-authored-by: Clément Renault <clement@meilisearch.com>
4475: Allow running benchmarks without sending results to the dashboard r=irevoire a=dureuill
Adds a `--no-dashboard` option to avoid sending results to the dashboard.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4456: Add Ollama as an embeddings provider r=dureuill a=jakobklemm
# Pull Request
## Related issue
[Related Discord Thread](https://discord.com/channels/1006923006964154428/1211977150316683305)
## What does this PR do?
- Adds Ollama as a provider of Embeddings besides HuggingFace and OpenAI under the name `ollama`
- Adds the environment variable `MEILI_OLLAMA_URL` to set the embeddings URL of an Ollama instance with a default value of `http://localhost:11434/api/embeddings` if no variable is set
- Changes some of the structs and functions in `openai.rs` to be public so that they can be shared.
- Added more error variants for Ollama specific errors
- It uses the model `nomic-embed-text` as default, but any string value is allowed, however it won't automatically check if the model actually exists or is an embedding model
Tested against Ollama version `v0.1.27` and the `nomic-embed-text` model.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Jakob Klemm <jakob@jeykey.net>
Co-authored-by: Louis Dureuil <louis.dureuil@gmail.com>
Instead of the user manually specifying the model dimensions it will now automatically get determined
Just like with hf.rs the word "test" gets embedded to determine the dimensions of the output
Add a dedicated error type for if the model doesn't exist (don't automatically pull it though) and set the fault of that error to be the user
4473: Bring back changes from v1.7.0 to main r=curquiza a=curquiza
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Many the fish <many@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
4463: Add tests when the field limit is reached r=Kerollmops a=irevoire
# Pull Request
## Related issue
Related to https://github.com/meilisearch/meilisearch/discussions/4429#discussioncomment-8689101
This user found out that the error message we’re supposed to return when the maximum number of attributes is reached is _not_ returned in some cases
## What does this PR do?
- This PR adds four tests around the maximum number of attributes:
1. Add a document with u16::MAX + 1 fields - Meilisearch panics
2. Add two documents which together adds up to u16::MAX + 1 fields - Meilisearch returns the expected error
3. Add a document with u16::MAX + 1 **nested fields** - No error message but the document isn’t indexed
4. Add two documents which together add up to u16::MAX + 1 nested fields - Meilisearch doesn’t return any error but doesn’t index the document
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Tamo <tamo@meilisearch.com>
4462: Divide threshold by ten r=dureuill a=ManyTheFish
Change the facet incremental vs bulk indexing threshold to better fit our user needs, it might be changed in the future if we have more insights
Co-authored-by: ManyTheFish <many@meilisearch.com>
4458: Replace logging timer by spans r=Kerollmops a=dureuill
- Remove logging timer dependency.
- Remplace last uses in search by spans
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4459: Put a bound on OpenAI timeout r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes#4460
## What does this PR do?
- Makes sure that the timeout of the openai embedder is limited to max 1min, rather than the prior 15min+
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4445: Add subcommand to run benchmarks r=irevoire a=dureuill
# Pull Request
## Related issue
Not user-facing, no issue
## What does this PR do?
- Adds a new `cargo xtask bench` subcommand that can run one or multiple workload files and report the results to a server
- A workload file is a JSON file with a specific schema
- Refactor our use of the `vergen` crate:
- update to the beta `vergen-git2` crate
- VERGEN_GIT_SEMVER_LIGHTWEIGHT => VERGEN_GIT_DESCRIBE
- factor logic in a single `build-info` crate that is used both by meilisearch and xtask (prevents vergen variables from overriding themselves)
- checked that defining the variables by hand when no git repo is available (docker build case) still works.
- Add CI to run `cargo xtask bench`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4450: Add the content type in the webhook + improve the test r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4436
## What does this PR do?
- Specify the content type of the webhook
- Ensure it’s the case in the test
Co-authored-by: Tamo <tamo@meilisearch.com>
4457: Bump mio from 0.8.9 to 0.8.11 r=Kerollmops a=dependabot[bot]
Bumps [mio](https://github.com/tokio-rs/mio) from 0.8.9 to 0.8.11.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/tokio-rs/mio/blob/master/CHANGELOG.md">mio's changelog</a>.</em></p>
<blockquote>
<h1>0.8.11</h1>
<ul>
<li>Fix receiving IOCP events after deregistering a Windows named pipe
(<a href="https://redirect.github.com/tokio-rs/mio/pull/1760">tokio-rs/mio#1760</a>, backport pr:
<a href="https://redirect.github.com/tokio-rs/mio/pull/1761">tokio-rs/mio#1761</a>).</li>
</ul>
<h1>0.8.10</h1>
<h2>Added</h2>
<ul>
<li>Solaris support
(<a href="https://redirect.github.com/tokio-rs/mio/pull/1724">tokio-rs/mio#1724</a>).</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="0328bdef90"><code>0328bde</code></a> Release v0.8.11</li>
<li><a href="7084498512"><code>7084498</code></a> Fix warnings</li>
<li><a href="90d4fe00df"><code>90d4fe0</code></a> named-pipes: fix receiving IOCP events after deregister</li>
<li><a href="c710a307f8"><code>c710a30</code></a> Add v0.8.x to the CI</li>
<li><a href="c29e21c244"><code>c29e21c</code></a> Release v0.8.10</li>
<li><a href="f6a20da1c8"><code>f6a20da</code></a> Add Solaris operating system support (<a href="https://redirect.github.com/tokio-rs/mio/issues/1724">#1724</a>)</li>
<li>See full diff in <a href="https://github.com/tokio-rs/mio/compare/v0.8.9...v0.8.11">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Initial prototype of Ollama embeddings actually working, error handlign / retries still missing.
Allow model to be any String and require dimensions parameter
Fixed rustfmt formatting issues
There were some formatting issues in the initial PR and this should not make the changes comply with the Rust style guidelines
Because I accidentally didn't follow the style guide for commits in my commit messages I squashed them into one to comply
4453: Don't test on nightly r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes#4441 better 😅
## What does this PR do?
- No longer run tests on nightly
The motivation for this change is that we are now updating Rust at fixed points in time, and so no longer need nightly runs to ensure that a change won't get into stable and break our build at the worst possible moment.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4451: Fix nightly build r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes#4441
## What does this PR do?
- Change imports following https://github.com/rust-lang/rust/pull/117772
## Note
This one is going to be annoying a bit until the lint stabilizes:
- We only get the warning on nightly, so we will discover them when it runs in the CI that uses the nightly compiler (not on regular PRs)
- There's the case of `TryInto`/`TryFrom` traits. They have been added to the prelude in Rust edition 2021, so it means that `use`ing them is a warning on nightly for 2021 edition crates (most crates), but not `use`ing them is an error anywhere for 2018 Rust edition crates, such as `milli`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4433: Enhance facet incremental r=Kerollmops a=ManyTheFish
# Pull Request
## Related issue
Fixes#4367Fixes#4409
## What does this PR do?
- Add a test reproducing #4409
- Fix#4409 by removing a document from a level only if it is no more present in all the linked sub-level nodes
- Optimize facet Incremental indexing by creating or deleting a complete level once per field id instead of for each facet value
- Optimize facet Incremental indexing by doing the additions and the deletions in the same process instead of doing them separately
Co-authored-by: ManyTheFish <many@meilisearch.com>
4446: Do not omit vectors when importing a dump r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#4447
## What does this PR do?
- Correctly populate the maps of embedders before starting the indexing operations, while importing a dump
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4435: Make update file deletion atomic r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4432
Fixes https://github.com/meilisearch/meilisearch/issues/4438 by adding the logs the user asked
## What does this PR do?
- Adds a bunch of logs to help debug this kind of issue in the future
- Delete the update files AFTER committing the update in the `index-scheduler` (thus, if a restart happens, we are able to re-process the batch successfully)
- Multi-thread the deletion of all update files.
Co-authored-by: Tamo <tamo@meilisearch.com>
4443: Add GPU analytics r=dureuill a=dureuill
# Pull Request
## Related issue
Adds analytics indicating whether Meilisearch was compiled with the `milli/cuda` feature.
Cc `@macraig`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4442: Send custom task r=ManyTheFish a=irevoire
This PR has already been merged on main but was supposed to be merged on `release-v1.7.0` thus we need to merge it a second time; sorry 😓
### This PR implements the necessary parameters for the High Availability
Introduce a new CLI flag called `--experimental-replication-parameters` that changes a few behaviors in the engine:
- [The auto-deletion of tasks is disabled](https://specs.meilisearch.com/specifications/text/0060-tasks-api.html#_2-technical-details)
- Upon registering a task, you can choose its task ID by sending a new header: `TaskId: 456645`. It must be a valid number, which must be superior to the last task id ever seen.
- Add the ability to « dry-register » a task. That means meilisearch will answer to you with a valid task ID like everything went well, but won’t actually write anything in the database. To do that, you need to use the `DryRun: true` header.
- Specification’s here: https://github.com/meilisearch/specifications/pull/266
Co-authored-by: Tamo <tamo@meilisearch.com>
4042: Implements the new replication parameters r=ManyTheFish a=irevoire
### This PR implements the necessary parameters for the High Availability
- [ ] Update the spec
Introduce a new CLI flag called `--experimental-replication-parameters` that changes a few behaviors in the engine:
- [The auto-deletion of tasks is disabled](https://specs.meilisearch.com/specifications/text/0060-tasks-api.html#_2-technical-details)
- Upon registering a task, you can choose its task ID by sending a new header: `TaskId: 456645`. It must be a valid number, which must be superior to the last task id ever seen.
- Add the ability to « dry-register » a task. That means meilisearch will answer to you with a valid task ID like everything went well, but won’t actually write anything in the database. To do that, you need to use the `DryRun: true` header.
----
Old prototype `prototype-custom-task-id-0`:
- Adds the capability to specify your own task ID via the `TaskId` http header
- Make the task IDs a u64 instead of a u32
Co-authored-by: Tamo <tamo@meilisearch.com>
4418: Output logs to stderr r=dureuill a=irevoire
Output the logs to `stderr` instead of `stdout`. This was introduced in the `v1.7.0-rc.0` and is a bug; logs should always be outputted to stderr.
Fix#4419
Co-authored-by: Tamo <tamo@meilisearch.com>
4410: Implement the experimental log mode cli flag and log level updates at runtime r=dureuill a=irevoire
# Pull Request
This PR fixes two issues at once because they’re highly correlated in the codebase.
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4415
Fixes https://github.com/meilisearch/meilisearch/issues/4413
## What does this PR do?
- It makes the fmt logger configurable to output json or human-readable logs (like we already do today)
- It moves the fmt logger under a `reload` layer so we can update its targets at runtime
- Add the possibility to stream logs in the json mode
- Adds an analytics for the new CLI flag
Co-authored-by: Tamo <tamo@meilisearch.com>
4400: Upgrade rustls to 0.21.10 and ring to 0.17 r=curquiza a=hack3ric
# Pull Request
## What does this PR do?
- Upgrade dependencies that uses ring 0.16 so that they rely on ring 0.17 instead
- Use rustls 0.21 for actix-{http,tls}, since newer versions of rustls uses ring 0.17
- Fix some trivial breaking API changes caused by above
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Eric Long <i@hack3r.moe>
4401: Update version for the next release (v1.7.0) in Cargo.toml r=irevoire a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: irevoire <irevoire@users.noreply.github.com>
4391: Tracing r=dureuill a=irevoire
# Pull Request
- [ ] Hide the parameters of the process batch
- [x] Make actix-web trace every call on every route
- [x] Remove all `env_logger`/`logs` dependencies
- [x] Be able to enable or disable the memory measurement using the `/logs` route parameters
See the following product discussion: https://github.com/orgs/meilisearch/discussions/721
Supersedes https://github.com/meilisearch/meilisearch/pull/4338
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4317
## What does this PR do?
Update the format of the logs from:
```
[2024-02-06T14:54:11Z INFO actix_server::builder] starting 10 workers
```
to
```
2024-02-06T13:58:14.710803Z INFO actix_server::builder: 200: starting 10 workers
```
First, run meilisearch with the route enabled via the feature flag:
- `cargo run --experimental-enable-logs-route`
- Or at runtime by sending the following payload:
```
curl \
-X PATCH 'http://localhost:7700/experimental-features/' \
-H 'Content-Type: application/json' \
--data-binary '{
"logsRoute": true
}'
```
Then gather data from meilisearch by calling for example:
```
curl \
-X POST http://localhost:7700/logs \
-H 'Content-Type: application/json' \
--data-binary '{
"mode": "fmt",
"target": "milli=trace"
}'
```
Once your operation is over, tell meilisearch to stop the route:
```
curl \
-X DELETE http://localhost:7700/logs
```
----
In the case you’re profiling code, you will be interested by the next command that converts the output of the route to a format that the firefox profiler can understand.
```bash
cargo run --release --bin trace-to-firefox -- 2024-01-17_17:07:55-indexing-trace.json
```
Then go to https://profiler.firefox.com and load it.
Note that we can also share the profiles using the https://share.firefox.dev website.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
4388: Cap the maximum memory of the grenad sorters r=curquiza a=Kerollmops
This PR clamps the memory usage of the grenad sorters to a reasonable maximum. Grenad sorters are opened on multiple threads at a time. This can result in higher memory usage than expected, even though it shouldn't consume more than the memory available.
Fixes#4152.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4389: Stabilize scoreDetails r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes#4359
## What does this PR do?
### User standpoint
- Users no longer need to enable the `scoreDetails` experimental feature to use `showRankingScoreDetails` in search queries.
- ⚠️ **Breaking change**: sending an object containing the key `"scoreDetails"` to the `/experimental-features` route is now an error. However, importing a dump of a database where that feature was enabled completes successfully.
### Implementation standpoint
- remove `scoreDetails` from the experimental features
- remove check on the experimental feature `scoreDetails` before accepting `showRankingScoreDetails`
- remove `scoreDetails` from the accepted fields in the `/experimental-features` route
- fix tests accordingly
## Manual tests
1. exported a dump with the `scoreDetails` feature enabled on `main`
- tried to import the dump after the changes in this PR
- the dump imported successfully
2. tried to make a search with `showRankingScoreDetails: true`
- the ranking score details are displayed
- an automated test case also exists and passes
3. tried to enable the `scoreDetails` in `/experimental-features`
- get error message
```
Unknown field `scoreDetails`: expected one of `vectorStore`, `metrics`, `exportPuffinReports`
```
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4375: Feat: add new OpenAI models and ability to override dimensions r=dureuill a=Gosti
# Pull Request
Fixes#4394
## Related discussion
https://github.com/orgs/meilisearch/discussions/677#discussioncomment-8306384
## What does this PR do?
- Add text-embedding-3-small
- Add text-embedding-3-large
- Add optional dimensions parameter for both new models
## Note
As the dimensions option is not available for text-embedding-ada-002 I've added a manual check to prevent, but I feel it could be implemented in a more idiomatic rust
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Gosti <gostitsog@gmail.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
-> make sure the settings change is rejected or the settings task fails when the specified model doesn't support
overriding `dimensions` and the passed `dimensions` differs from the model's default dimensions.
4360: fix readme broken links r=curquiza a=Elliot67
# Pull Request
## What does this PR do?
- fix some links in the readme
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Elliot Lintz <45725915+Elliot67@users.noreply.github.com>
Co-authored-by: gui machiavelli <hey@guimachiavelli.com>
4364: Revert "Remove panic on the geosearch" r=curquiza a=irevoire
After more thought about it, we want to fix this bug in a patch release instead of `main`.
I revert this PR for now, but the fix will still land on `main` once we bring back the change of the `v1.6.1` on `main`.
Reverts meilisearch/meilisearch#4337
Co-authored-by: Tamo <irevoire@protonmail.ch>
4304: Add CUDA GPU support for Hugging Face embedders r=Kerollmops a=dureuill
Adds a "cuda" feature to `milli`.
Compiling with this feature requires that the CUDA support library be installed (see "with CUDA support" paragraph in https://huggingface.github.io/candle/guide/installation.html), and adds CUDA support to the `huggingFace` embedder.
To enable GPU support, users will need to:
1. Have a compatible NVidia GPU under Linux
2. Follow [the guide](https://huggingface.github.io/candle/guide/installation.html) to install the CUDA dependencies
3. Compile Meilisearch with the `cuda` feature: `cargo build --release --features cuda`
# Impact
Enabling the CUDA feature allows to use an available GPU to compute embeddings with a `huggingFace` embedder.
On an AWS Graviton 2, this yields a x3 - x5 improvement on indexing time.
# Technical details
- I had to change the CI so that the cuda feature is not included in the `Tests all features` workflow
- To achieve that, I had to add a binary following the `cargo xtask` design pattern, to list all features excepted the cuda one.
- I then changed the workflow accordingly (renamed to "Tests almost all features" 😉)
- A test run of the new feature was done on a temporary version of this PR that had it enabled for PRs: [See the results here](https://github.com/meilisearch/meilisearch/actions/runs/7461331929/job/20301216732)
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4345: Bump h2 from 0.3.20 to 0.3.24 r=curquiza a=dependabot[bot]
Bumps [h2](https://github.com/hyperium/h2) from 0.3.20 to 0.3.24.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/hyperium/h2/releases">h2's releases</a>.</em></p>
<blockquote>
<h2>v0.3.24</h2>
<h2>Fixed</h2>
<ul>
<li>Limit error resets for misbehaving connections.</li>
</ul>
<h2>v0.3.23</h2>
<h2>What's Changed</h2>
<ul>
<li>cherry-pick fix: streams awaiting capacity lockout in <a href="https://redirect.github.com/hyperium/h2/pull/734">hyperium/h2#734</a></li>
</ul>
<h2>v0.3.22</h2>
<h2>What's Changed</h2>
<ul>
<li>Add <code>header_table_size(usize)</code> option to client and server builders.</li>
<li>Improve throughput when vectored IO is not available.</li>
<li>Update indexmap to 2.</li>
</ul>
<h2>New Contributors</h2>
<ul>
<li><a href="https://github.com/tottoto"><code>`@tottoto</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/714">hyperium/h2#714</a></li>
<li><a href="https://github.com/xiaoyawei"><code>`@xiaoyawei</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/712">hyperium/h2#712</a></li>
<li><a href="https://github.com/Protryon"><code>`@Protryon</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/719">hyperium/h2#719</a></li>
<li><a href="https://github.com/4JX"><code>`@4JX</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/638">hyperium/h2#638</a></li>
<li><a href="https://github.com/vuittont60"><code>`@vuittont60</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/724">hyperium/h2#724</a></li>
</ul>
<h2>v0.3.21</h2>
<h2>What's Changed</h2>
<ul>
<li>Fix opening of new streams over peer's max concurrent limit.</li>
<li>Fix <code>RecvStream</code> to return data even if it has received a <code>CANCEL</code> stream error.</li>
<li>Update MSRV to 1.63.</li>
</ul>
<h2>New Contributors</h2>
<ul>
<li><a href="https://github.com/DDtKey"><code>`@DDtKey</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/703">hyperium/h2#703</a></li>
<li><a href="https://github.com/jwilm"><code>`@jwilm</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/707">hyperium/h2#707</a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/hyperium/h2/blob/v0.3.24/CHANGELOG.md">h2's changelog</a>.</em></p>
<blockquote>
<h1>0.3.24 (January 17, 2024)</h1>
<ul>
<li>Limit error resets for misbehaving connections.</li>
</ul>
<h1>0.3.23 (January 10, 2024)</h1>
<ul>
<li>Backport fix from 0.4.1 for stream capacity assignment.</li>
</ul>
<h1>0.3.22 (November 15, 2023)</h1>
<ul>
<li>Add <code>header_table_size(usize)</code> option to client and server builders.</li>
<li>Improve throughput when vectored IO is not available.</li>
<li>Update indexmap to 2.</li>
</ul>
<h1>0.3.21 (August 21, 2023)</h1>
<ul>
<li>Fix opening of new streams over peer's max concurrent limit.</li>
<li>Fix <code>RecvStream</code> to return data even if it has received a <code>CANCEL</code> stream error.</li>
<li>Update MSRV to 1.63.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="7243ab5854"><code>7243ab5</code></a> Prepare v0.3.24</li>
<li><a href="d919cd6fd8"><code>d919cd6</code></a> streams: limit error resets for misbehaving connections</li>
<li><a href="a7eb14a487"><code>a7eb14a</code></a> v0.3.23</li>
<li><a href="b668c7fbe2"><code>b668c7f</code></a> fix: streams awaiting capacity lockout (<a href="https://redirect.github.com/hyperium/h2/issues/730">#730</a>) (<a href="https://redirect.github.com/hyperium/h2/issues/734">#734</a>)</li>
<li><a href="0f412d8b9c"><code>0f412d8</code></a> v0.3.22</li>
<li><a href="c7ca62f69b"><code>c7ca62f</code></a> docs: fix typos (<a href="https://redirect.github.com/hyperium/h2/issues/724">#724</a>)</li>
<li><a href="ef743ecb22"><code>ef743ec</code></a> Add a setter for header_table_size (<a href="https://redirect.github.com/hyperium/h2/issues/638">#638</a>)</li>
<li><a href="56651e6e51"><code>56651e6</code></a> fix lint about unused import</li>
<li><a href="4aa7b16342"><code>4aa7b16</code></a> Fix documentation for max_send_buffer_size (<a href="https://redirect.github.com/hyperium/h2/issues/718">#718</a>)</li>
<li><a href="d03c54a80d"><code>d03c54a</code></a> chore(dependencies): update tracing minimal version to 0.1.35</li>
<li>Additional commits viewable in <a href="https://github.com/hyperium/h2/compare/v0.3.20...v0.3.24">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
4325: Add Setting API reminder in issue template r=ManyTheFish a=ManyTheFish
When adding a new setting, several important points can be easily forgotten.
This PR adds a small reminder list of some of these points in the issue template.
Co-authored-by: Many the fish <many@meilisearch.com>
4330: Add job variable to grafana dashboard r=irevoire a=capJavert
# Pull Request
## Related issue
Fixes https://github.com/orgs/meilisearch/discussions/625#discussioncomment-8143282
## What does this PR do?
"meilisearch" as [job_name](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#job_name) was hardcoded in the dashboard config so if user sets anything but "meilisearch" as job_name on prometheus side the dashboard does not work.
With this change dasboard will auto load the values from data source (much like instance variable) and show the correct data. This now also adds support for multiple meilisearch jobs in single dashboard.
See: https://github.com/orgs/meilisearch/discussions/625#discussioncomment-8143282
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: capJavert <ante@kickass.website>
4337: Remove panic on the geosearch r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes #4333
## What does this PR do?
- Add tests for the enrich pipeline on malformed documents with `null` value
- Reproduce the issue when updating the settings while there is malformed documents in the DB
- Fix the bug
Co-authored-by: Tamo <tamo@meilisearch.com>
4332: Update the dependencies r=irevoire a=Kerollmops
This PR upgrades the dependencies and fixes#4287.
- ~We keep arroy at the current commit. We will release and use the latest version published when possible~
- We also updated arroy to 0.2.0.
- I rolled back the version of rustls has too many breaking changes.
- I had to keep HTTP to 0.2.11 due to actix-cors.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4263: Bump rustls-webpki from 0.101.3 to 0.101.7 r=irevoire a=dependabot[bot]
Bumps [rustls-webpki](https://github.com/rustls/webpki) from 0.101.3 to 0.101.7.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/rustls/webpki/releases">rustls-webpki's releases</a>.</em></p>
<blockquote>
<h2>0.101.7</h2>
<ul>
<li>Upgrades <code>*ring*</code> to 0.17, and <code>untrusted</code> to 0.9. Note: since <code>untrusted</code> appears in the <code>Error</code> API this may be a breaking change for applications using two <code>untrusted</code> versions.</li>
</ul>
<h2>What's Changed</h2>
<ul>
<li>Simplify tests for DER errors by <a href="https://github.com/djc"><code>`@djc</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/193">rustls/webpki#193</a></li>
<li>Upgrade to ring 0.17, untrusted 0.9 by <a href="https://github.com/djc"><code>`@djc</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/193">rustls/webpki#193</a></li>
<li>Bump MSRV to 1.61 by <a href="https://github.com/djc"><code>`@djc</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/193">rustls/webpki#193</a></li>
<li>Upgrade to rcgen 0.11.3 by <a href="https://github.com/cpu"><code>`@cpu</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/189">rustls/webpki#189</a>, <a href="https://redirect.github.com/rustls/webpki/pull/195">rustls/webpki#195</a></li>
<li>v0.101.7 preparation by <a href="https://github.com/cpu"><code>`@cpu</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/199">rustls/webpki#199</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/rustls/webpki/compare/v/0.101.6...v/0.101.7">https://github.com/rustls/webpki/compare/v/0.101.6...v/0.101.7</a></p>
<h2>0.101.6</h2>
<ul>
<li>The <code>CertificateRevocationList</code> trait's <code>verify_signature</code> <code>Budget</code> argument was removed. This was a semver incompatible change mistakenly introduced in v0.101.5.</li>
</ul>
<h2>What's Changed</h2>
<ul>
<li>crl: rm Budget from verify_signature fn by <a href="https://github.com/cpu"><code>`@cpu</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/187">rustls/webpki#187</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/rustls/webpki/compare/v/0.101.5...v/0.101.6">https://github.com/rustls/webpki/compare/v/0.101.5...v/0.101.6</a></p>
<h2>0.101.5</h2>
<ul>
<li>Path building complexity is now limited to a maximum budget of path finding operations, avoiding exponential processing time when encountering certificate chains containing many certificates with the same subject/issuer distinguished name but different subject public key information.</li>
<li>Name constraints evaluation is now limited to a maximum number of comparison operations, avoiding exponential processing time when encountering certificate chains containing many name constraints and subject alternate names.</li>
<li>Subject common names are no longer parsed for name iteration, or applying name constraints. Webpki only uses Subject Alternate Names when validating certificates, and the common name handling was buggy, producing <code>Error::BadDer</code> when iterating certificates with printable string subject common names, or omitted common names encoded as an empty sequence.</li>
</ul>
<h2>What's Changed</h2>
<p>The following PRs were backported to the rel-0.101 branch in <a href="https://redirect.github.com/rustls/webpki/issues/170">#170</a>:</p>
<ul>
<li>Further limits on expensive path building (<a href="https://redirect.github.com/rustls/webpki/issues/163">#163</a>)</li>
<li>Budget tweaks (<a href="https://redirect.github.com/rustls/webpki/issues/164">#164</a>)</li>
<li>Bound name constraint comparisons (<a href="https://redirect.github.com/rustls/webpki/issues/165">#165</a>)</li>
<li>Remove subject common name parsing (<a href="https://redirect.github.com/rustls/webpki/issues/169">#169</a>, thanks to <a href="https://github.com/hawkw"><code>`@hawkw</code></a>)</li>`
<li>Correct handling of fatal errors (<a href="https://redirect.github.com/rustls/webpki/issues/168">#168</a>)</li>
</ul>
<p>Thanks to all who have contributed, on behalf of the rustls team (<a href="https://github.com/ctz"><code>`@ctz</code></a>,` <a href="https://github.com/cpu"><code>`@cpu</code></a>` and <a href="https://github.com/djc"><code>`@djc</code></a>)!</p>`
<h2>0.101.4</h2>
<h2>Release notes</h2>
<ul>
<li>certificate path building and verification is now capped at 100 signature validation operations to avoid the risk of CPU usage denial-of-service attack when validating crafted certificate chains producing quadratic runtime. This risk affected both clients, as well as servers that verified client certificates.</li>
</ul>
<h2>What's Changed</h2>
<ul>
<li>v0.101.4 prep by <a href="https://github.com/cpu"><code>`@cpu</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/153">rustls/webpki#153</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/rustls/webpki/compare/v/0.101.3...v/0.101.4">https://github.com/rustls/webpki/compare/v/0.101.3...v/0.101.4</a></p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="ee5aab1dff"><code>ee5aab1</code></a> Cargo: v0.101.6 -> v0.101.7</li>
<li><a href="4f721a901f"><code>4f721a9</code></a> Upgrade to rcgen 0.11.3</li>
<li><a href="3be3625584"><code>3be3625</code></a> Bump MSRV to 1.61</li>
<li><a href="bb7c7f47ab"><code>bb7c7f4</code></a> Upgrade to ring 0.17, untrusted 0.9</li>
<li><a href="2eeb2920cf"><code>2eeb292</code></a> Simplify tests for DER errors</li>
<li><a href="7956538ee7"><code>7956538</code></a> Cargo: v0.101.5 -> v0.101.6</li>
<li><a href="7f8208ec06"><code>7f8208e</code></a> crl: rm <code>Budget</code> from <code>verify_signature</code> fn</li>
<li><a href="7cb6c646a0"><code>7cb6c64</code></a> Cargo: bump version 0.101.4 -> 0.101.5</li>
<li><a href="2dd2a06016"><code>2dd2a06</code></a> verify_cert: use enum for build chain error</li>
<li><a href="c255d61a6a"><code>c255d61</code></a> verify_cert: correct handling of fatal errors</li>
<li>Additional commits viewable in <a href="https://github.com/rustls/webpki/compare/v/0.101.3...v/0.101.7">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
4319: Update README r=curquiza a=codesmith-emmy
# Pull Request
## Related issue
Fixes #<issue_number>
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: emmanuel <154705254+codesmith-emmy@users.noreply.github.com>
When adding a new setting, there are several important points that can be easily forgotten.
This PR adds a small reminder list of some of these points.
4318: Hide embedders r=ManyTheFish a=dureuill
Hides `embedders` when it is an empty dictionary.
Manual tests:
- getting settings with empty embedders: not displayed
- getting settings with non-empty embedders: displayed like before
- dump with empty embedders: can be imported
- dump with non-empty embedders: can be imported
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4313: Fix document formatting performances r=Kerollmops a=ManyTheFish
reduce the formatted option list to the attributes that should be formatted,
instead of all the attributes to display.
The time to compute the `format` list scales with the number of fields to format;
cumulated with `map_leaf_values` that iterates over all the nested fields, it gives a quadratic complexity:
`d*f` where `d` is the total number of fields to display and `f` is the total number of fields to format.
Co-authored-by: ManyTheFish <many@meilisearch.com>
4314: Fix proximity precision telemetry r=Kerollmops a=ManyTheFish
The proximity precision telemetry was partially missing in the global setting route.
This PR adds the missing field and return the default value when the value is not set.
Co-authored-by: ManyTheFish <many@meilisearch.com>
4311: Limit the number of values returned by the facet search r=dureuill a=Kerollmops
This PR fixes a bug where the number of values per facet returned by the `indexes/{index}/facet-search` route was not tacking the `faceting.maxValuePerFacet` setting. It also adds a test.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4308: Fix hang on `/indexes` and `/stats` routes r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#4218
## Context
- A previous fix added a field to the `IndexScheduler` to memorize the `currently_updating_index`, so that accessing it through the search would return the handle without trying to open it. This resolved a hang on the search, but #4218 reported further hangs on the `/indexes` and `/stats` routes
- These routes were shunting the `IndexScheduler` and using internal `IndexMapper` logic to access the indexes, again trying to reopen the updating index.
## What does this PR do?
- Moves the logic relative to the `currently_updating_index` from the `IndexScheduler` to the `IndexMapper`, so that any index request to the `IndexMapper` can benefit from it.
## Test
1. Follow reproducer from #4218
2. Before this PR, notice a hang on `/stats` and `/indexes`, but not on `/indexes/<updating_index>/search`
3. After this PR, notice no hang on either of `/stats`, `/indexes` or `/indexes/<updating_index>/search`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4296: Fix single element search r=irevoire a=dureuill
# Pull Request
Before this PR, indexing a single vector in a single document would result in the vector not being found by the vector search.
This PR adds a test case for this condition, and resolves it by bumping arroy to a version containing the fix.
# Test case
Output of the test before and after this PR:
```diff
diff --git a/meilisearch/tests/search/hybrid.rs b/meilisearch/tests/search/hybrid.rs
index 2cd4b83e7..79819cab2 100644
--- a/meilisearch/tests/search/hybrid.rs on release-v1.6.0
+++ b/meilisearch/tests/search/hybrid.rs on fix-single-element-search
`@@` -171,5 +171,5 `@@` async fn single_document() {
.await;
snapshot!(code, `@"200` OK");
- snapshot!(response["hits"][0], `@r###"{"title":"Shazam!","desc":"a` Captain Marvel ersatz","id":"1","_vectors":{"default":[1.0,3.0]},"_rankingScore":0.0}"###);
+ snapshot!(response["hits"][0], `@r###"{"title":"Shazam!","desc":"a` Captain Marvel ersatz","id":"1","_vectors":{"default":[1.0,3.0]},"_rankingScore":1.0,"_semanticScore":1.0}"###);
}
```
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4293: Update SDK test dependencies r=curquiza a=curquiza
Replace dependabot updates
The changes are really un-impactful for the engine team velocity because is about a CI
- that does not run during release deployment
- that does not run to merge a PR
It's only a weekly scheduled CI to check the breaking we introduced in the integrations.
I updated the dependencies based on what we do on the integration CIs
For example for dart, I looked at what we have in the [Dart CI](63fd758882/.github/workflows/tests.yml (L16-L54)) and I updated our CI in this repo accordingly. I did the same for each repository. This ensures we test the same things.
Co-authored-by: curquiza <clementine@meilisearch.com>
4294: fix compilation warnings for release v1.6 r=curquiza a=irevoire
# Pull Request
## Related issue
Fixes#4292
## What does this PR do?
- Removed unused imports
#4295 fixes the issue no main
Co-authored-by: Tamo <tamo@meilisearch.com>
4279: Check experimental feature on setting update query rather than in the task. r=ManyTheFish a=dureuill
Improve the UX by checking for the vector store feature and returning an error synchronously when sending a setting update, rather than in the indexing task.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4238: Task queue webhook r=dureuill a=irevoire
# Prototype `prototype-task-queue-webhook-1`
The prototype is available through Docker by using the following command:
```bash
docker run -p 7700:7700 -v $(pwd)/meili_data:/meili_data getmeili/meilisearch:prototype-task-queue-webhook-1
```
# Pull Request
Implements the task queue webhook.
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4236
## What does this PR do?
- Provide a new cli and env var for the webhook, respectively called `--task-webhook-url` and `MEILI_TASK_WEBHOOK_URL`
- Also supports sending the requests with a custom `Authorization` header by specifying the optional `--task-webhook-authorization-header` CLI parameter or `MEILI_TASK_WEBHOOK_AUTHORIZATION_HEADER` env variable.
- Throw an error if the specified URL is invalid
- Every time a batch is processed, send all the finished tasks into the webhook with our public `TaskView` type as a JSON Line GZIPed body.
- Add one test.
## PR checklist
### Before becoming ready to review
- [x] Add a test
- [x] Compress the data we send
- [x] Chunk and stream the data we send
- [x] Remove the unwrap in the index-scheduler when sending the data fails
- [x] The analytics are missing
### Before merging
- [x] Release a prototype
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
4277: Update mini-dashboard to v0.2.12 r=curquiza a=mdubus
# Pull Request
## Related issue
Fixes#4276
## What does this PR do?
Upgrade mini-dashboard to version 0.2.12 ([see changes](https://github.com/meilisearch/mini-dashboard/releases/tag/v0.2.12))
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Morgane Dubus <30866152+mdubus@users.noreply.github.com>
4275: Flatten settings r=dureuill a=dureuill
# Pull Request
## Related issue
Initial internal feedback seems to indicate that the current shape of the `embedders` setting is undesirable: it has too much depth.
This PR changes this by flattening the structure of the embedders to the following:
```json5
// NEW structure
"embedders": {
// still starts with the embedder name
"default": {
"source": "huggingFace", // now a string
// properties of the source are all at the same level as the source
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
"revision": "a9c555277f9bcf24f28fa5e092e665fc6f7c49cd",
"documentTemplate": "A product titled '{{doc.title}}'" // now a string
}
}
```
By comparison, the old structure was:
```json5
// PREVIOUS version, no longer working with this PR
"embedders": {
// still starts with the embedder name
"default": {
"source": {
"huggingFace": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
"revision": "a9c555277f9bcf24f28fa5e092e665fc6f7c49cd"
},
"documentTemplate": {
"template": "A product titled '{{doc.title}}'" // now a string
}
}
}
```
The fields that are accepted in the new version of the `embedders` setting are depending on the value of the `source` field:
```json5
// huggingFace
"embedders": {
"default": {
"source": "huggingFace",
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
"revision": "a9c555277f9bcf24f28fa5e092e665fc6f7c49cd",
"documentTemplate": "A product titled '{{doc.title}}'"
}
}
// openAi
"embedders": {
"default": {
"source": "openAi",
"model": "text-embedding-ada-002",
"apiKey": "open_ai_api_key",
"documentTemplate": "A product titled '{{doc.title}}'"
}
}
// userProvided
"embedders": {
"default": {
"source": "userProvided",
"dimensions": 42, // mandatory
}
}
```
## What does this PR do?
- Flatten the settings structure
- Validate the prompt earlier to return a synchronous error on setting change rather than in the failing task
- Make it an error to pass a field for the wrong source (see above for allowed fields for each source)
- Not changed: It is still an error not to pass `dimensions` to the `userProvided` embedder
- If `source` was specified in the settings, validate the setting early to return a synchronous error in case of a missing mandatory field for the userProvided source (dimensions) or a forbidden field for the specified source.
- If `source` was not specified in the settings, still validate the setting, but only at indexing time, by using the source stored in the DB.
- Resets all values if the source changes, even if the user did not reset them explicitly.
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Change the public facing guide for using the API
- [ ] Change examples of use in the changelog
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4272: Don't pass default revision when the model is explicitly set in config r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#4271
## What does this PR do?
- When the `model` is explicitly set in the `embedders` setting, we reset the `revision` to `None`, such that if the user doesn't specify a revision, the head of the model repository is chosen.
- Not changed: If the user specifies a revision, it applies, like previously.
- Not changed: If the user doesn't specify a model, the default model with the default revision applies, like previously.
## Manual testing on a fresh DB
1. Enable experimental feature:
```sh
curl \
-X PATCH 'http://localhost:7700/experimental-features/' \
-H 'Content-Type: application/json' -H 'Authorization: Bearer foo' \
--data-binary '{ "vectorStore": true
}'
```
2. Send settings with a specified model but no specified revision:
```sh
curl \
-X PATCH 'http://localhost:7700/indexes/products/settings' \
-H 'Content-Type: application/json' --data-binary \
'{ "embedders": { "default": { "source": { "huggingFace": { "model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" } }, "documentTemplate": { "template": "A product titled '{{doc.title}}'"} } } }'
```
3. Check that the task was successful:
```sh
curl 'http://localhost:7700/tasks/0'
{"uid":0,"indexUid":"products","status":"succeeded","type":"settingsUpdate","canceledBy":null,"details":{"embedders":{"default":{"source":{"huggingFace":{"model":"sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"}},"documentTemplate":{"template":"A product titled {{doc.title}}"}}}},"error":null,"duration":"PT0.001892S","enqueuedAt":"2023-12-20T09:17:01.73789Z","startedAt":"2023-12-20T09:17:01.73854Z","finishedAt":"2023-12-20T09:17:01.740432Z"}
```
4. Send documents to index:
```sh
curl 'https://localhost:7700/indexes/products/documents' -H 'Content-Type: application/json' --data-binary '{"id": 0, "title": "Best product"}'
```
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4269: Remove dependency that requires libstdc++ r=dureuill a=dureuill
Removes the dependency that caused the additional runtime dependency on libstdc++ by disabling the default features of the hf tokenizer.
## Discussion
- This removes a feature that is using a C++ dependency and is supposed to accelerate the tokenizer. As the tokenizer is likely to be a significant bottleneck for embedding texts using a HF model, this is an issue.
- We should at least rerun the movies vector indexing and check that it still works correctly and that it has a runtime in the ballpark of what it used to be.
Co-authored-by: Louis Dureuil <louis.dureuil@xinra.net>
4268: Add libstdc++ in Dockerfile r=curquiza a=sanders41
# Pull Request
## Related issue
Fixes#4267
## What does this PR do?
- Add libstdc++ in the Dockerfile
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Paul Sanders <psanders1@gmail.com>
4262: Update version for the next release (v1.6.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4257: Change proximity precision settings r=dureuill a=ManyTheFish
- [x] Add proximity_precision value into the analytics
- [x] Change the naming of `attributeScale` and `wordScale` into `byAttribute` and `byWord`
- [x] Remove proximityPrecision from the experimental feature
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Many the fish <many@meilisearch.com>
4226: Hybrid search r=dureuill a=dureuill
Allows to perform hybrid search requests that combine the results of semantic and keyword search and automatically generate embeddings.
## How to use
See [feature description](https://meilisearch.notion.site/v1-6-Hybrid-Search-Embedders-ea42c82f90cc4bc0be1eeb917c1118c8)
## Changes
- work is based on #4213
- milli::new search now takes an input universe directly, rather than computing it from a filter. This adds flexibility to require results on a subset of documents
- vector search is now a regular ranking rule (akin to sort and geosort) and reports its score as a ScoreDetail
- separate keyword search and vector search functions, vector search now respects (geo)sort ranking rules
- add automatic embedding
- add hybrid search
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
- DistributionShift in Search object (to be set from model in embed?)
- Fix issue where embedder index wasn't computed at search time
- Accept as default embedder either the "default" one, or the only embedder when there is only one
4254: Bring back v1.5.1 changes into main r=ManyTheFish a=Kerollmops
This pull request brings back changes from the _release-v1.5.1_ branch into _main_.
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
4250: Update version for the next release (v1.5.1) in Cargo.toml r=dureuill a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4239: Remove the actix-web dependency from milli r=dureuill a=Kerollmops
Just remove actix-web from milli.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4233: Add test reproducing #4232 r=dureuill a=ManyTheFish
- add a test reproducing the bug
- fix the bug by creating 2 different restricting lists of attributes, one for the exact attributes, and the other for the tolerant attributes
## Related issue
Fixes#4232
Co-authored-by: ManyTheFish <many@meilisearch.com>
4223: Update to heed 0.20 r=dureuill a=Kerollmops
This PR brings the v0.20-alpha.9 version of heed into Meilisearch 🎉 The main goal is to test it in a real environment to make the necessary changes if needed. We also want to merge it as soon as possible during the pre-release phase to ensure we catch bugs before the release.
Most of the calls to heed are the same as before, except:
- The `PolyDatabase` has been replaced with a `Database<Unspecified, Unspecified>`. We replaced the `get<T, U>()` by a `remap<T, U>().get()` calls.
- The `Database` `append(...)` method has been replaced with a `put_with_flags(PutFlags::APPEND, ...)`.
- The `RwTxn<'e, 'p>` has been simplified into a `RwTxn<'e>`.
- The `BytesEncode/Decode` traits return a `Result<_, BoxedError>` instead of an `Option<_>`.
- We no longer need to wrap and unwrap the `BEU32` integer when storing/getting them from heed.
### TODO
- [x] Create actual, simple error types instead of using strings in the codecs.
### Follow-up work
- Move the codecs into another member crate (we depend on the uuid one in the meilitool crate).
- Display the internal decoding error in the `SerializationError` internal error variant.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4234: Fix puffin in the index scheduler r=dureuill a=irevoire
Currently, we can't compile the index scheduler without this feature.
It could be cool to specify the dependencies in the main workspace cargo toml like quickwit does to avoid this kind of error in the future; https://github.com/quickwit-oss/quickwit/blob/main/quickwit/Cargo.toml#L41
Co-authored-by: Tamo <tamo@meilisearch.com>
4231: Fixed payload limit setting being ignored for delete documents by batch r=Kerollmops a=Karribalu
# Pull Request
## Related issue
Fixes#4224
## What does this PR do?
- Added http_payload_size_limit to JsonConfig to allow deleting documents in batches with a payload size greater than 2MB, which is the default limit set in the JsonConfig crate.
## PR checklist
Please check if your PR fulfills the following requirements:
- [Y] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [Y] Have you read the contributing guidelines?
- [Y] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: karribalu <karri.balu123456@gmail.com>
4090: Diff indexing r=ManyTheFish a=ManyTheFish
This pull request aims to reduce the indexing time by computing a difference between the data added to the index and the data removed from the index before writing in LMDB.
## Why focus on reducing the writings in LMDB?
The indexing in Meilisearch is split into 3 main phases:
1) The computing or the extraction of the data (Multi-threaded)
2) The writing of the data in LMDB (Mono-threaded)
3) The processing of the prefix databases (Mono-threaded)
see below:

Because the writing is mono-threaded, it represents a bottleneck in the indexing, reducing the number of writes in LMDB will reduce the pressure on the main thread and should reduce the global time spent on the indexing.
## Give Feedback
We created [a dedicated discussion](https://github.com/meilisearch/meilisearch/discussions/4196) for users to try this new feature and to give feedback on bugs or performance issues.
## Technical approach
### Part 1: merge the addition and the deletion process
This part:
a) Aims to reduce the time spent on indexing only the filterable/sortable fields of documents, for example:
- Updating the number of "likes" or "stars" of a song or a movie
- Updating the "stock count" or the "price" of a product
b) Aims to reduce the time spent on writing in LMDB which should reduce the global indexing time for the highly multi-threaded machines by reducing the writing bottleneck.
c) Aims to reduce the average time spent to delete documents without having to keep the soft-deleted documents implementation
- [x] Create a preprocessing function that creates the diff-based documents chuck (`OBKV<fid, OBKV<AddDel, value>>`)
- [x] and clearly separate the faceted fields and the searchable fields in two different chunks
- Change the parameters of the input extractor by taking an `OBKV<fid, OBKV<AddDel, value>>` instead of `OBKV<fid, value>`.
- [x] extract_docid_word_positions
- [x] extract_geo_points
- [x] extract_vector_points
- [x] extract_fid_docid_facet_values
- Adapt the searchable extractors to the new diff-chucks
- [x] extract_fid_word_count_docids
- [x] extract_word_pair_proximity_docids
- [x] extract_word_position_docids
- [x] extract_word_docids
- Adapt the facet extractors to the new diff-chucks
- [x] extract_facet_number_docids
- [x] extract_facet_string_docids
- [x] extract_fid_docid_facet_values
- [x] FacetsUpdate
- [x] Adapt the prefix database extractors ⚠️⚠️
- [x] Make the LMDB writer remove the document_ids to delete at the same time the new document_ids are added
- [x] Remove document deletion pipeline
- [x] remove `new_documents_ids` entirely and `replaced_documents_ids`
- [x] reuse extracted external id from transform instead of re-extracting in `TypedChunks::Documents`
- [x] Remove deletion pipeline after autobatcher
- [x] remove autobatcher deletion pipeline
- [x] everything uses `IndexOperation::DocumentOperation`
- [x] repair deletion by internal id for filter by delete
- [x] Improve the deletion via internal ids by avoiding iterating over the whole set of external document ids.
- [x] Remove soft-deleted documents
#### FIXME
- [x] field distribution is not correctly updated after deletion
- [x] missing documents in the tests of tokenizer_customization
### Part 2: Only compute the documents field by field
This part aims to reduce the global indexing time for any kind of partial document modification on any size of machine from the mono-threaded one to the highly multi-threaded one.
- [ ] Make the preprocessing function only send the fields that changed to the extractors
- [ ] remove the `word_docids` and `exact_word_docids` database and adapt the search (⚠️ could impact the search performances)
- [ ] replace the `word_pair_proximity_docids` database with a `word_pair_proximity_fid_docids` database and adapt the search (⚠️ could impact the search performances)
- [ ] Adapt the prefix database extractors ⚠️⚠️
## Technical Concerns
- The part 1 implementation could increase the indexing time for the smallest machines (with few threads) by increasing the extracting time (multi-threaded) more than the writing time (mono-threaded)
- The part 2 implementation needs to change the databases which could have a significant impact on the search performances
- The prefix databases are a bit special to process and may be a pain to adapt to the difference-based indexing
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4203: Extract external document docids from docs on deletion by filter r=Kerollmops a=dureuill
This fixes some of the performance regression observed on `diff-indexing` when doing delete-by-filter with a filter matching many documents.
To delete 19 768 771 documents (hackernews dataset, all documents matching `type = comment`), here are the observed time:
|branch (commit sha1sum)|time|speed-down factor (lower is better)|
|--|--|--|
|`main` (48865470d7)|1212.885536s (~20min)|x1.0 (baseline)|
|`diff-indexing` (523519fdbf)|5385.550543s (90min)|x4.44|
|**`diff-indexing-extract-primary-key`**(f8289cd974)|2582.323324s (43min) | x2.13|
So we're still suffering a speed-down of x2.13, but that's much better than x4.44.
---
Changes:
- Refactor the logic of PrimaryKey extraction to a struct
- Add a trait to abstract the extraction of field id from a name between `DocumentBatch` and `FieldIdMap`.
- Add `Index::external_id_of` to get the external ids of a bitmap of internal ids.
- Use this new method to add new Transform and Batch methods to remove documents that are known to be from the DB.
- Modify delete-by-filter to use the new method
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4205: Prevent search hang on the processing index r=Kerollmops a=dureuill
Fixes#4206, an issue originally [reported on Discord](https://discord.com/channels/1006923006964154428/1148983671026618579/1148983671026618579) where having parallel search requests on more indexes than the index cache capacity would cause search requests on the currently updating index to hang until the index is done updating.
## Test setup
- Create 20 empty indexes by sending settings to them
- repeatedly send placeholder search requests to each of the indexes in a loop
- Create another index and send a significant batch of documents to index.
- Attempt to perform a search request on that last index.
- Before this PR, the search request hangs while the index update task is processing
- After this PR, the search request respond immediately even while the index update task is processing
## Changes
- When getting the handle to an index for some potentially long running batches of tasks, save it in the index scheduler.
- Drop the handle from the index-scheduler when the task is done so that we don't leak indexes.
- When getting an index from outside the task queue processor, check if there is such an handle matching the requested index. If so, skip the cache entirely and clone the handle.
Co-authored-by: Louis Dureuil <louis.dureuil@xinra.net>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4204: Throw error when the vector search is sent with the wrong size r=Kerollmops a=dureuill
# Pull Request
## Related issue
Fixes#4201
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4185: Bump Swatinem/rust-cache from 2.6.2 to 2.7.1 r=curquiza a=dependabot[bot]
Bumps [Swatinem/rust-cache](https://github.com/swatinem/rust-cache) from 2.6.2 to 2.7.1.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/swatinem/rust-cache/releases">Swatinem/rust-cache's releases</a>.</em></p>
<blockquote>
<h2>v2.7.0</h2>
<h2>What's Changed</h2>
<ul>
<li>Fix save-if documentation in readme by <a href="https://github.com/rukai"><code>`@rukai</code></a>` in <a href="https://redirect.github.com/Swatinem/rust-cache/pull/166">Swatinem/rust-cache#166</a></li>
<li>Support for <code>trybuild</code> and similar macro testing tools by <a href="https://github.com/neysofu"><code>`@neysofu</code></a>` in <a href="https://redirect.github.com/Swatinem/rust-cache/pull/168">Swatinem/rust-cache#168</a></li>
</ul>
<h2>New Contributors</h2>
<ul>
<li><a href="https://github.com/rukai"><code>`@rukai</code></a>` made their first contribution in <a href="https://redirect.github.com/Swatinem/rust-cache/pull/166">Swatinem/rust-cache#166</a></li>
<li><a href="https://github.com/neysofu"><code>`@neysofu</code></a>` made their first contribution in <a href="https://redirect.github.com/Swatinem/rust-cache/pull/168">Swatinem/rust-cache#168</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/Swatinem/rust-cache/compare/v2.6.2...v2.7.0">https://github.com/Swatinem/rust-cache/compare/v2.6.2...v2.7.0</a></p>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/blob/master/CHANGELOG.md">Swatinem/rust-cache's changelog</a>.</em></p>
<blockquote>
<h2>2.7.1</h2>
<ul>
<li>Update toml parser to fix parsing errors.</li>
</ul>
<h2>2.7.0</h2>
<ul>
<li>Properly cache <code>trybuild</code> tests.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="3cf7f8cc28"><code>3cf7f8c</code></a> 2.7.1</li>
<li><a href="e03705e031"><code>e03705e</code></a> changelog</li>
<li><a href="b86d1c6caa"><code>b86d1c6</code></a> bump all the other dependencies too</li>
<li><a href="f27990c89a"><code>f27990c</code></a> Update Dependencies (<a href="https://redirect.github.com/swatinem/rust-cache/issues/172">#172</a>)</li>
<li><a href="a95ba19544"><code>a95ba19</code></a> 2.7.0</li>
<li><a href="82c8487d00"><code>82c8487</code></a> changelog</li>
<li><a href="67c46e7159"><code>67c46e7</code></a> Support for <code>trybuild</code> and similar macro testing tools (<a href="https://redirect.github.com/swatinem/rust-cache/issues/168">#168</a>)</li>
<li><a href="44b6087283"><code>44b6087</code></a> Fix save-if documentation in readme (<a href="https://redirect.github.com/swatinem/rust-cache/issues/166">#166</a>)</li>
<li>See full diff in <a href="https://github.com/swatinem/rust-cache/compare/v2.6.2...v2.7.1">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
4167: Introduce the `meilitool` command line interface r=Kerollmops a=Kerollmops
This PR introduces a small tool to help the Cloud team:
- Clear the tasks queue by removing all the tasks
- Dump a Meilisearch database without having to enqueue the task
- Access this `meilitool` binary from the Docker Image
## TODO
- [x] Modify the Docker File to ship with this new tool (`@curquiza,` could you review that, please?)
- [x] Clear the tasks queue by removing all the tasks
- [x] Add more logs to explain what is happening
- [x] Clear the `update_files` folder
- [x] Dump a Meilisearch database without having to enqueue the task
- [x] Add more logs to explain what is happening
- [x] Introduce a flag to skip dumping enqueued and processing tasks.
- [x] Dump the instance uid.
- [x] Dump the keys.
- [x] Dump the tasks with the update files.
- [x] Dump the index documents and settings.
- [ ] ~Dump the experimental features~
Co-authored-by: Clément Renault <clement@meilisearch.com>
4169: update charabia r=curquiza a=ManyTheFish
Update Charabia to v0.8.5 and add the new khmer tokenizer
Co-authored-by: ManyTheFish <many@meilisearch.com>
4132: Extract the creation and last updated timestamp from v2 dumps r=irevoire a=vivek-26
# Pull Request
## Related issue
Fixes#2989
## What does this PR do?
This PR -
- extracts the `created_at` and `updated_at` dates from v2 dumps.
- updates the unit tests.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Vivek Kumar <vivek.26@outlook.com>
4154: Update version for the next release (v1.5.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4126: Make the experimental route /metrics activable via HTTP r=dureuill a=braddotcoffee
# Pull Request
## Related issue
Closes#4086
## What does this PR do?
- [x] Make `/metrics` available via HTTP as described in #4086
- [x] The users can still launch Meilisearch using the `--experimental-enable-metrics` flag.
- [x] If the flag `--experimental-enable-metrics` is activated, a call to the `GET /experimental-features` route right after the launch will show `"metrics": true` even if the user has not called the `PATCH /experimental-features` route yet.
- [x] Even if the --experimental-enable-metrics flag is present at launch, calling the `PATCH /experimental-features` route with `"metrics": false` disables the experimental feature.
- [x] Update the spec
- I was unable to find docs in this repository to update about the `/experimental-features` endpoint. I'll happily update if you point me in the right direction!
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: bwbonanno <bradfordbonanno@gmail.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
4134: Bump rustix from 0.36.15 to 0.36.16 r=Kerollmops a=dependabot[bot]
Bumps [rustix](https://github.com/bytecodealliance/rustix) from 0.36.15 to 0.36.16.
<details>
<summary>Commits</summary>
<ul>
<li><a href="6534992521"><code>6534992</code></a> chore: Release rustix version 0.36.16</li>
<li><a href="4928cf7a38"><code>4928cf7</code></a> Disable riscv64 testing.</li>
<li><a href="8cc159c4c3"><code>8cc159c</code></a> Fix the <code>test_ttyname_ok</code> test when /dev/stdin is inaccessable. (<a href="https://redirect.github.com/bytecodealliance/rustix/issues/821">#821</a>)</li>
<li><a href="6dc7ba9478"><code>6dc7ba9</code></a> Downgrade dependencies and disable tests to compile under Rust 1.48.</li>
<li><a href="ded8986e7e"><code>ded8986</code></a> Disable MIPS in CI. (<a href="https://redirect.github.com/bytecodealliance/rustix/issues/793">#793</a>)</li>
<li><a href="739f9c3ba0"><code>739f9c3</code></a> Fixes for <code>Dir</code> on macOS, FreeBSD, and WASI.</li>
<li><a href="87481a97f4"><code>87481a9</code></a> Merge pull request from GHSA-c827-hfw6-qwvm</li>
<li>See full diff in <a href="https://github.com/bytecodealliance/rustix/compare/v0.36.15...v0.36.16">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
4073: Simplify Puffin report exports r=ManyTheFish a=Kerollmops
This PR changes how we export Puffin reports by directly writing them to disk when the `exportPuffinReports` [experimental feature is enabled](https://www.meilisearch.com/docs/learn/experimental/overview) on the `/experimental-features` route. It also adds more puffing logging to the deletion phase and grenad helpers. The puffin reports are identified by the date and time at which they are exported.
## Todo List
- [x] Change the CLI flag to be an API experimental option.
- [x] Create [a PRD for this experimental feature (private)](https://www.notion.so/meilisearch/Export-Puffin-Reports-091df151e71c4edfb7d72f4bf995b3ea).
- [x] Create and complete [a product discussion](https://github.com/meilisearch/product/discussions/693) (copy/paste PROFILING markdown?).
- [x] Update the _PROFILING.md_ markdown file instructions.
- [x] Change the debug logs of the processing operation (visible in puffin viewer).
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
4101: Bump webpki from 0.22.1 to 0.22.2 r=curquiza a=dependabot[bot]
Bumps [webpki](https://github.com/briansmith/webpki) from 0.22.1 to 0.22.2.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/briansmith/webpki/commits">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
4108: Fix bug where search with distinct attribute and no ranking, returns offset+limit hits r=curquiza a=vivek-26
# Pull Request
## Related issue
Fixes#4078
## What does this PR do?
This PR -
- Fixes bug where search with distinct attribute and no ranking, returns offset+limit hits.
- Adds unit and integration tests.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Vivek Kumar <vivek.26@outlook.com>
4089: Use a bufreader and bufwriter everytime there is a grenad<file> r=curquiza a=irevoire
# Pull Request
Wrap all the files we give to a grenad in a `BufReader` or `BufWriter`.
The dump import I tried in the issue went from 2h to 10 minutes on my machine.
I also ran a bunch of benchmarks on my machine, and we're faster by a few seconds everywhere but nothing huge.
-----
The one thing I’m afraid about is if we used to get the inner file in a grenad and then do a read right after without a seek at the beginning of the file or a reopen.
Since we now use a bufreader our read would return the bytes one buffer later and probably completely corrupt what we were supposed to read.
From what I see, it looks like it works, but I may have missed something, I don't know much about this part of the codebase.
This issue should not arise on the bufwriter, though, because if we're not able to write the content of the buffer I ensured that the `into_inner` of the bufwriter should return an internal error.
## Related issue
Fixes#4087
Co-authored-by: Tamo <tamo@meilisearch.com>
4112: Update version for the next release (v1.4.1) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
4102: Introduce the first bot that shows benchmarks results r=curquiza a=Kerollmops
TBD
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
4074: Enable analytics in debug builds r=Kerollmops a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4072
## What does this PR do?
- Stop disabling the analytics if meilisearch has been compiled in debug mode
Co-authored-by: Tamo <tamo@meilisearch.com>
4065: Dependency issue every 6 months r=curquiza a=curquiza
To avoid spending too much time on it (1 every two sprints)
If you disagree `@Kerollmops,` for security or any reason, please close the PR
Co-authored-by: Clémentine U. - curqui <clementine@meilisearch.com>
4044: Add more integrations to SDK CI r=curquiza a=curquiza
For the integration scope management, but also to anticipate bugs and breaking changes for engine team, we need to add more SDKs tests into the CI
Co-authored-by: curquiza <clementine@meilisearch.com>
Display docker image
Add strapi and firebase
Add rails and symfony tests
Remove strapi and firestore tests
Fix dotnet SDK CI
Use specific dart SDK version
Disable coverage for ruby SDK
Prevent pushing coverage information to codecov
Remove codecoverage token
Trigger Build
Trigger Build
Trigger Build
Trigger Build
Trigger Build
4056: Rewrite segment_analytics module with the destructuring syntax r=Kerollmops a=vivek-26
# Pull Request
## Related issue
Fixes#3928
## What does this PR do?
- This PR uses Rust Destructuring syntax in the `segment_analytics` module, such that adding or deleting fields causes an error at compile time.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Vivek Kumar <vivek.26@outlook.com>
4053: Fix the stats of the documents deletion by filter r=Kerollmops a=irevoire
# Pull Request
The issue was that the operation « DocumentDeletionByFilter » was not declared as an index operation. That means the index stats were not reprocessed after the application of the operation.
## Related issue
Fixes#4018
## What does this PR do?
- Move the `DocumentDeletionByFilter` internal operation into the category of the `IndexOperation`. This means that the stats will automatically be re-processed after a batch is processed.
- Update a test to ensure that the stats are valid after each operation
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Tamo <tamo@meilisearch.com>
4051: Implement the snapshots on demand r=Kerollmops a=irevoire
# Pull Request
Private link: [PRD available here](https://www.notion.so/meilisearch/On-demand-snapshots-5676e542b905459d96eec228da133b00#847ff0cafeb64fe09e8ee7150852b474)
Specification here: https://github.com/meilisearch/specifications/pull/258
## Prototype
A prototype is available under the name: `prototype-snapshot-on-demand-0`.
## Related issue
Fixes#4052
## What does this PR do?
- Introduce a new route, `POST /snapshots` to create snapshots on demand
- Introduce a new api-key action `snapshot.create`
- Introduce a new analytic `Snapshot Created` sent every time a snapshot is created.
## Notes for the team
I made a prototype so users can test the feature before the v1.5 comes out. But we can merge the PR as-is.
Co-authored-by: Tamo <tamo@meilisearch.com>
3997: Refactor empty arrays/objects should return empty instead of null r=Kerollmops a=dogukanakkaya
# Pull Request
## What does this PR do?
At the moment if we select empty objects and array of object properties with dot notations like:
```json
{
"array": [],
"object": {}
}
```
```rs
GetDocumentOptions { fields: Some(vec!["array.name", "object.name"]) }
```
returns null if the array/object has no property yet.
I am not sure if this is expected or it's the correct behaviour but I add my document with a property that is assigned to an empty array/object, later on when I select it, returns null which is kinda weird and unexpected in my opinion.
This PR fixes that issue by returning an empty vector if the array is empty or an empty map if object is empty. This is not added for `permissive-json-pointer/src/lib.rs:224` because `create_array` loops over each item. Selecting a single property that is an object, in an array of objects would result other objects to be empty maps instead of none.
```json
"doggos": [
{
"jean": {
"race": {
"name": "bernese mountain",
}
}
},
{
"marc": {
"age": 4,
"race": {
"name": "golden retriever",
}
}
}
]
```
```rs
GetDocumentOptions { fields: Some(vec!["doggos.jean"]) }
```
Would result in `jean` object and an extra empty object for `marc`.
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: dogukanakkaya <doguakkaya27@hotmail.com>
4009: Bump rustls-webpki from 0.100.1 to 0.100.2 r=Kerollmops a=dependabot[bot]
Bumps [rustls-webpki](https://github.com/rustls/webpki) from 0.100.1 to 0.100.2.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/rustls/webpki/releases">rustls-webpki's releases</a>.</em></p>
<blockquote>
<h2>v/0.100.2</h2>
<h2>Release notes</h2>
<ul>
<li>certificate path building and verification is now capped at 100 signature validation operations to avoid the risk of CPU usage denial-of-service attack when validating crafted certificate chains producing quadratic runtime. This risk affected both clients, as well as servers that verified client certificates.</li>
</ul>
<h2>What's Changed</h2>
<ul>
<li>v0.100.2 prep by <a href="https://github.com/cpu"><code>`@cpu</code></a>` in <a href="https://redirect.github.com/rustls/webpki/pull/154">rustls/webpki#154</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/rustls/webpki/compare/v/0.100.1...v/0.100.2">https://github.com/rustls/webpki/compare/v/0.100.1...v/0.100.2</a></p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="c8b821450b"><code>c8b8214</code></a> Bump MSRV to 1.60</li>
<li><a href="855752292e"><code>8557522</code></a> Avoid testing MSRV of dev-dependencies</li>
<li><a href="73a7f0c7d7"><code>73a7f0c</code></a> Cargo: version 0.100.1 -> 0.100.2</li>
<li><a href="4ea052366f"><code>4ea0523</code></a> verify_cert: enforce maximum number of signatures.</li>
<li>See full diff in <a href="https://github.com/rustls/webpki/compare/v/0.100.1...v/0.100.2">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
The issue was that the operation « DocumentDeletionByFilter » was not
declared as an index operation. That means the indexes stats were not
reprocessed after the application of the operation.
4050: Bump webpki from 0.22.0 to 0.22.1 r=Kerollmops a=dependabot[bot]
Bumps [webpki](https://github.com/briansmith/webpki) from 0.22.0 to 0.22.1.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/briansmith/webpki/commits">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
* [Update] test-suite.yml
Added New run command for cargo tree without default features using if-then block
* [Updated] test-disabled-tokenization in test-suite.yml
* [Updated] test-suite.yml
* Update .github/workflows/test-suite.yml
---------
Co-authored-by: Clémentine U. - curqui <clementine@meilisearch.com>
4028: Fix highlighting bug when searching for a phrase with cropping r=ManyTheFish a=vivek-26
# Pull Request
## Related issue
Fixes#3975
## What does this PR do?
This PR -
- Fixes the bug where searching **only** for a phrase (containing multiple words) along with cropping, highlighted only the first word of the phrase.
- Adds unit test case for the above mentioned scenario.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Vivek Kumar <vivek.26@outlook.com>
4041: Register the swap indexe task in a spawn blocking to be sure to never… r=ManyTheFish a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/4040
## What does this PR do?
- Register the swap indexes task in a spawn blocking task
Co-authored-by: Tamo <tamo@meilisearch.com>
4039: Fix multiple vectors dimensions r=ManyTheFish a=Kerollmops
This PR fixes#4035, making providing multiple vectors in documents possible. This is fixed by extracting the vectors from the non-flattened version of the documents.
Co-authored-by: Kerollmops <clement@meilisearch.com>
4038: Fix filter escaping issues r=ManyTheFish a=Kerollmops
This PR fixes#4034 by always escaping the sequences. Users must always put quotes (simple or double) to escape the filter values.
Co-authored-by: Kerollmops <clement@meilisearch.com>
4037: Update version for the next release (v1.3.3) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
3994: Fix synonyms with separators r=Kerollmops a=ManyTheFish
# Pull Request
## Related issue
Fixes#3977
## Available prototype
```
$ docker pull getmeili/meilisearch:prototype-fix-synonyms-with-separators-0
```
## What does this PR do?
- add a new test
- filter the empty synonyms after normalization
Co-authored-by: ManyTheFish <many@meilisearch.com>
4016: Define the full Homebrew formula path r=curquiza a=Kerollmops
This PR fixes#4015 by defining the full Homebrew formula path.
Co-authored-by: Clément Renault <clement@meilisearch.com>
4025: Bump Swatinem/rust-cache from 2.5.1 to 2.6.2 r=curquiza a=dependabot[bot]
Bumps [Swatinem/rust-cache](https://github.com/swatinem/rust-cache) from 2.5.1 to 2.6.2.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/swatinem/rust-cache/releases">Swatinem/rust-cache's releases</a>.</em></p>
<blockquote>
<h2>v2.6.2</h2>
<h2>What's Changed</h2>
<ul>
<li>dep: Use <code>smol-toml</code> instead of <code>toml</code> by <a href="https://github.com/NobodyXu"><code>`@NobodyXu</code></a>` in <a href="https://redirect.github.com/Swatinem/rust-cache/pull/164">Swatinem/rust-cache#164</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/Swatinem/rust-cache/compare/v2...v2.6.2">https://github.com/Swatinem/rust-cache/compare/v2...v2.6.2</a></p>
<h2>v2.6.1</h2>
<ul>
<li>Fix hash contributions of <code>Cargo.lock</code>/<code>Cargo.toml</code> files.</li>
</ul>
<h2>v2.6.0</h2>
<h2>What's Changed</h2>
<ul>
<li>Add "buildjet" as a second <code>cache-provider</code> backend <a href="https://github.com/joroshiba"><code>`@joroshiba</code></a>` in <a href="https://redirect.github.com/Swatinem/rust-cache/pull/154">Swatinem/rust-cache#154</a></li>
<li>Clean up sparse registry index.</li>
<li>Do not clean up src of <code>-sys</code> crates.</li>
<li>Remove <code>.cargo/credentials.toml</code> before saving.</li>
</ul>
<h2>New Contributors</h2>
<ul>
<li><a href="https://github.com/joroshiba"><code>`@joroshiba</code></a>` made their first contribution in <a href="https://redirect.github.com/Swatinem/rust-cache/pull/154">Swatinem/rust-cache#154</a></li>
</ul>
<p><strong>Full Changelog</strong>: <a href="https://github.com/Swatinem/rust-cache/compare/v2.5.1...v2.6.0">https://github.com/Swatinem/rust-cache/compare/v2.5.1...v2.6.0</a></p>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/blob/master/CHANGELOG.md">Swatinem/rust-cache's changelog</a>.</em></p>
<blockquote>
<h2>2.6.2</h2>
<ul>
<li>Fix <code>toml</code> parsing.</li>
</ul>
<h2>2.6.1</h2>
<ul>
<li>Fix hash contributions of <code>Cargo.lock</code>/<code>Cargo.toml</code> files.</li>
</ul>
<h2>2.6.0</h2>
<ul>
<li>Add "buildjet" as a second <code>cache-provider</code> backend.</li>
<li>Clean up sparse registry index.</li>
<li>Do not clean up src of <code>-sys</code> crates.</li>
<li>Remove <code>.cargo/credentials.toml</code> before saving.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="e207df5d26"><code>e207df5</code></a> 2.6.2</li>
<li><a href="decb69d790"><code>decb69d</code></a> Update dependencies and add changelog</li>
<li><a href="ab6b2769d1"><code>ab6b276</code></a> dep: Use <code>smol-toml</code> instead of <code>toml</code> (<a href="https://redirect.github.com/swatinem/rust-cache/issues/164">#164</a>)</li>
<li><a href="578b235f6e"><code>578b235</code></a> 2.6.1</li>
<li><a href="5113490c3f"><code>5113490</code></a> prepare 2.6.1</li>
<li><a href="c0e052c18c"><code>c0e052c</code></a> Fix hashing of parsed <code>Cargo.toml</code> (<a href="https://redirect.github.com/swatinem/rust-cache/issues/160">#160</a>)</li>
<li><a href="4e0f4b19dd"><code>4e0f4b1</code></a> Fix typo in hashing parsed <code>Cargo.lock</code> (<a href="https://redirect.github.com/swatinem/rust-cache/issues/159">#159</a>)</li>
<li><a href="b919e1427f"><code>b919e14</code></a> feat: Add logging to <code>Cargo.lock</code>/<code>Cargo.toml</code> hashing (<a href="https://redirect.github.com/swatinem/rust-cache/issues/156">#156</a>)</li>
<li><a href="b8a6852b4f"><code>b8a6852</code></a> 2.6.0</li>
<li><a href="80c47cc945"><code>80c47cc</code></a> Clean up <code>credentials.toml</code></li>
<li>Additional commits viewable in <a href="https://github.com/swatinem/rust-cache/compare/v2.5.1...v2.6.2">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
4020: Update version for the next release (v1.4.0) in Cargo.toml r=Kerollmops a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: Kerollmops <Kerollmops@users.noreply.github.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
4013: Fix the ranking rule by temporarily disabling an assert in the bucket sort algorithm r=Kerollmops a=Kerollmops
This PR temporarily disables an assertion, making the search crash. [I created a tracking issue](https://github.com/meilisearch/meilisearch/issues/4012) to find a better way to fix this.
It no longer reverts a20e4d447c, which seemed to generate unreachable graphs and make the bucket sort ranking algorithm panic because of entering an unreachable state. We discussed that below in the comments.
Temporary fixes#4002, fixes#4006, and fixes#3995.
---
It took me approximately 2 days to find the first bad commit just because I'm bad in `git bisect` x `bash`, i.e. [I misused `%1` with `$!` to kill the most recently backgrounded job](https://unix.stackexchange.com/a/340084/212574)...
<details>
<summary>Here is the script I used to find the invalid commit</summary>
```bash
#!/usr/bin/env bash
set -x
# remove the data
rm -rf data.ms
# build meilisearch
cargo build --release
# ignore this commit if it doesn't compile
if [[ $? != 0 ]]; then
exit 125
fi
# index the dump and start from it
./target/release/meilisearch \
--http-addr 'localhost:7705' \
--import-dump $HOME/Downloads/modified-20230822-083016113.dump &
# wait 10 sec while it indexes the docs
sleep 5
# check if the server crashes on requests
echo '{
"q": "rtx 305",
"attributesToHighlight": [
"*"
],
"highlightPreTag": "<ais-highlight-0000000000>",
"highlightPostTag": "</ais-highlight-0000000000>",
"limit": 21,
"offset": 0
}' | xh 'localhost:7705/indexes/arvutitark_local_orderables/search'
last_exit_code=$?
# Now kill Meilisearch
kill $!
# Clean the potential Cargo.lock
git checkout .
exit $last_exit_code
```
</details>
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
3945: Do not leak field information on error r=Kerollmops a=vivek-26
# Pull Request
## Related issue
Fixes#3865
## What does this PR do?
This PR ensures that `InvalidSortableAttribute`and `InvalidFacetSearchFacetName` errors do not leak field information i.e. fields which are not part of `displayedAttributes` in the settings are hidden from the error message.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Vivek Kumar <vivek.26@outlook.com>
4000: Update version for the next release (v1.3.2) in Cargo.toml r=irevoire a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: irevoire <irevoire@users.noreply.github.com>
3998: Accept the `null` JSON value as a value of the `_vectors` field r=irevoire a=Kerollmops
This PR fixes#3979 by accepting `null` JSON values in the `_vectors` fields provided by the user.
Can the reviewer please verify that I am merging in the right branch?
I think we must create a new _release-v1.3.2_.
Co-authored-by: Kerollmops <clement@meilisearch.com>
3990: Removed unnecessary borrow call that failed nightly tests r=irevoire a=JannisK89
# Pull Request
## Related issue
Fixes#3988
## What does this PR do?
- Removes unnecessary borrow call that was causing warnings when running tests on nightly.
## PR checklist
Please check if your PR fulfills the following requirements:
- [ x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ x] Have you read the contributing guidelines?
- [ x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Please let me know if there is anything else I can do to improve this PR.
Thank you.
Co-authored-by: JannisK89 <jannis.karanikis@gmail.com>
3976: Fix the get stats method r=ManyTheFish a=irevoire
# Pull Request
- The get stats method of the index-scheduler was not using at all the processing tasks. That was returning a wrong number of enqueued tasks and 0 processing tasks.
- Added a test
- Currently this method was **ONLY** used to compute the `meilisearch_nb_tasks` field of the **experimental feature** metrics.
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3972
Co-authored-by: Tamo <tamo@meilisearch.com>
3946: Settings customizing tokenization r=irevoire a=ManyTheFish
# Pull Request
This pull Request allows the User to customize Meilisearch Tokenization by providing specialized settings.
## Small documentation
All the new settings can be set and reset like the other index settings by calling the route `/indexes/:name/settings`
### `nonSeparatorTokens`
The Meilisearch word segmentation uses a default list of separators to segment words, however, for specific use cases some of the default separators shouldn't be considered separators, the `nonSeparatorTokens` setting allows to remove of some tokens from the default list of separators.
***Request payload `PUT`- `/indexes/articles/settings/non-separator-tokens`***
```json
["`@",` "#", "&"]
```
### `separatorTokens`
Some use cases need to define additional separators, some are related to a specific way of parsing technical documents some others are related to encodings in documents, the `separatorTokens` setting allows adding some tokens to the list of separators.
***Request payload `PUT`- `/indexes/articles/settings/separator-tokens`***
```json
["§", "&sep"]
```
### `dictionary`
The Meilisearch word segmentation relies on separators and language-based word-dictionaries to segment words, however, this segmentation is inaccurate on technical or use-case specific vocabulary (like `G/Box` to say `Gear Box`), or on proper nouns (like `J. R. R.` when parsing `J. R. R. Tolkien`), the `dictionary` setting allows defining a list of words that would be segmented as described in the list.
***Request payload `PUT`- `/indexes/articles/settings/dictionary`***
```json
["J. R. R.", "J.R.R."]
```
these last feature synergies well with the `stopWords` setting or the `synonyms` setting allowing to segment words and correctly retrieve the synonyms:
***Request payload `PATCH`- `/indexes/articles/settings`***
```json
{
"dictionary": ["J. R. R.", "J.R.R."],
"synonyms": {
"J.R.R.": ["jrr", "J. R. R."],
"J. R. R.": ["jrr", "J.R.R."],
"jrr": ["J.R.R.", "J. R. R."],
}
}
```
### Related specifications:
- https://github.com/meilisearch/specifications/pull/255
- https://github.com/meilisearch/specifications/pull/254
### Try it with Docker
```bash
$ docker pull getmeili/meilisearch:prototype-tokenizer-customization-3
```
## Related issue
Fixes#3610Fixes#3917
Fixes https://github.com/meilisearch/product/discussions/468
Fixes https://github.com/meilisearch/product/discussions/160
Fixes https://github.com/meilisearch/product/discussions/260
Fixes https://github.com/meilisearch/product/discussions/381
Fixes https://github.com/meilisearch/product/discussions/131
Related to https://github.com/meilisearch/meilisearch/issues/2879Fixes#2760
## What does this PR do?
- Add a setting `nonSeparatorTokens` allowing to remove a token from the default separator tokens
- Add a setting `separatorTokens` allowing to add a token in the separator tokens
- Add a setting `dictionary` allowing to override the segmentation on specific words
- add new error code `invalid_settings_non_separator_tokens` (invalid_request)
- add new error code `invalid_settings_separator_tokens` (invalid_request)
- add new error code `invalid_settings_dictionary` (invalid_request)
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Many the fish <many@meilisearch.com>
3986: Fix geo bounding box with strings r=ManyTheFish a=irevoire
# Pull Request
When sending a document with one geofield of type string (i.e.: `{ "_geo": { "lat": 12, "lng": "13" }}`), the geobounding box would exclude this document.
This PR fixes this issue by automatically parsing the string value in case we're working on a geofield.
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3973
## What does this PR do?
- Automatically parse the facet value iif we're working on a geofield.
- Make insta works with snapshots in loops or closure executed multiple times. (you may need to update your cli if it panics after this PR: `cargo install cargo-insta`).
- Add one integration test in milli and in meilisearch to ensure it works forever.
- Add three snapshots for the dump that mysteriously disappeared I don't know how
Co-authored-by: Tamo <tamo@meilisearch.com>
3981: Truncate the normalized long facets used in the search for facet value r=irevoire a=ManyTheFish
# Pull Request
Truncate the normalized long facets used in the search for facet value
## targeted release
v1.3.1
## Related issue
Fixes#3978
Co-authored-by: ManyTheFish <many@meilisearch.com>
3982: Update version for the next release (v1.3.1) in Cargo.toml r=irevoire a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: irevoire <irevoire@users.noreply.github.com>
3968: Bump svenstaro/upload-release-action from 2.6.1 to 2.7.0 r=curquiza a=dependabot[bot]
Bumps [svenstaro/upload-release-action](https://github.com/svenstaro/upload-release-action) from 2.6.1 to 2.7.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/svenstaro/upload-release-action/releases">svenstaro/upload-release-action's releases</a>.</em></p>
<blockquote>
<h2>2.7.0</h2>
<ul>
<li>Allow setting an explicit target_commitish <a href="https://redirect.github.com/svenstaro/upload-release-action/pull/46">#46</a> (thanks <a href="https://github.com/Spikatrix"><code>`@Spikatrix</code></a>)</li>`
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/svenstaro/upload-release-action/blob/master/CHANGELOG.md">svenstaro/upload-release-action's changelog</a>.</em></p>
<blockquote>
<h2>[2.7.0] - 2023-07-28</h2>
<ul>
<li>Allow setting an explicit target_commitish <a href="https://redirect.github.com/svenstaro/upload-release-action/pull/46">#46</a> (thanks <a href="https://github.com/Spikatrix"><code>`@Spikatrix</code></a>)</li>`
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="1beeb572c1"><code>1beeb57</code></a> 2.7.0</li>
<li><a href="5206d34958"><code>5206d34</code></a> Bump deps</li>
<li><a href="80d7a7e41c"><code>80d7a7e</code></a> Merge pull request <a href="https://redirect.github.com/svenstaro/upload-release-action/issues/46">#46</a> from Spikatrix/master</li>
<li><a href="5eb2ffd70b"><code>5eb2ffd</code></a> Merge pull request <a href="https://redirect.github.com/svenstaro/upload-release-action/issues/110">#110</a> from svenstaro/dependabot/npm_and_yarn/word-wrap-1.2.4</li>
<li><a href="07af2f374a"><code>07af2f3</code></a> Bump word-wrap from 1.2.3 to 1.2.4</li>
<li><a href="5164410c7d"><code>5164410</code></a> Push dist</li>
<li><a href="f47fb36ff1"><code>f47fb36</code></a> Use the ref api to check if a tag exists</li>
<li><a href="212d4babf8"><code>212d4ba</code></a> Rethrow getTag error if not 404</li>
<li><a href="7670b98fa0"><code>7670b98</code></a> Push dist files</li>
<li><a href="ac438791c4"><code>ac43879</code></a> Warn when target_commit is ignored</li>
<li>Additional commits viewable in <a href="https://github.com/svenstaro/upload-release-action/compare/2.6.1...2.7.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
3969: Bump Swatinem/rust-cache from 2.5.0 to 2.5.1 r=curquiza a=dependabot[bot]
Bumps [Swatinem/rust-cache](https://github.com/swatinem/rust-cache) from 2.5.0 to 2.5.1.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/swatinem/rust-cache/releases">Swatinem/rust-cache's releases</a>.</em></p>
<blockquote>
<h2>v2.5.1</h2>
<ul>
<li>Fix hash contribution of <code>Cargo.lock</code>.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/blob/master/CHANGELOG.md">Swatinem/rust-cache's changelog</a>.</em></p>
<blockquote>
<h2>2.5.1</h2>
<ul>
<li>Fix hash contribution of <code>Cargo.lock</code>.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="dd05243424"><code>dd05243</code></a> 2.5.1</li>
<li><a href="65dbc54a5d"><code>65dbc54</code></a> update changelog</li>
<li><a href="be7377e68e"><code>be7377e</code></a> fix <code>src/config.ts</code>: Remove <code>sort_object</code> (<a href="https://redirect.github.com/swatinem/rust-cache/issues/152">#152</a>)</li>
<li>See full diff in <a href="https://github.com/swatinem/rust-cache/compare/v2.5.0...v2.5.1">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
3967: Bring back changes from `release-v1.3.0` into `main` r=ManyTheFish a=curquiza
Using a temp branch because of git conflict
Co-authored-by: Cong Chen <cong.chen@ocrlabs.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
3963: Fix the milli crate r=ManyTheFish a=irevoire
Milli was using the serde feature of either without enabling it first; thus, it wasn't working.
It was working in meilisearch, though, because `meilisearch-types` was using the feature which enables it globally for all the other crates.
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3962
Co-authored-by: Tamo <tamo@meilisearch.com>
3957: fix: upgrade mimalloc dependency to resolve FreeBSD build r=irevoire a=ThatOneCalculator
# Pull Request
## Related issue
Fixes#3806
## What does this PR do?
- Upgrades mimalloc to 0.1.37
- Fixes build on FreeBSD
Ref: https://github.com/meilisearch/meilisearch/issues/3806#issuecomment-1653693468
Tested and working on FreeBSD 13.1-RELEASE-p5
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: ThatOneCalculator <kainoa@t1c.dev>
3955: Update mini-dashboard to version 0.2.11 r=curquiza a=bidoubiwa
# Pull Request
## What does this PR do?
- Updates the mini-dashboard to version [0.2.11](https://github.com/meilisearch/mini-dashboard/releases/tag/v0.2.11)
## PR checklist
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Charlotte Vermandel <charlottevermandel@gmail.com>
3952: Use the new safe `read-txn-no-tls` heed feature r=ManyTheFish a=Kerollmops
[We recently found out](https://github.com/meilisearch/heed/issues/191#issuecomment-1650280513) that the `read-sync-txn` heed feature was invalid and must be removed from this crate. We were declaring it in milli/meilisearch but, fortunately, not sharing the `RoTxn`s across threads 😮💨
[I recently introduced the `read-txn-no-tls` heed feature](https://github.com/meilisearch/heed/pull/194), which implements `RoTxn: Send` and allows multiple read transactions on a single thread (which we use).
This PR removes the `sync-read-txn` heed feature from the _Cargo.toml_ file. I will fix this in heed v0.20.0 and will fill a RustSec advisory in the meantime.
Co-authored-by: Clément Renault <clement@meilisearch.com>
3953: Update UTM campaign r=curquiza a=macraig
# Pull Request
## What does this PR do?
Redirect CTAs to Cloud landing page
Co-authored-by: María <maria@Marias-MacBook-Pro.local>
3942: Normalize for the search the facets values r=ManyTheFish a=Kerollmops
This PR improves and fixes the search for facet values feature. Searching for _bre_ wasn't returning facet values like _brévent_ or _brô_.
The issue was related to the fact that facets are normalized but not in the same way as the `searchableAttributes` are. We decided to normalize them further and add another intermediate database where the key is the normalized facet value, and the value is a set of the non-normalized facets. We then use these non-normalized ones to get the correct counts by fetching the associated databases.
### What's missing in this PR?
- [x] Apply the change to the whole set of `SearchForFacetValue::execute` conditions.
- [x] Factorize the code that does an intermediate normalized value fetch in a function.
- [x] Add or modify the search for facet value test.
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
3948: Fix hnsw internal panic by using another library r=ManyTheFish a=Kerollmops
This pull request fixes#3923. The issue concerns the `hnsw` crate panicking due to a wrong call to the `[T]::copy_from_slice` function.
I decided to switch the library to `instant-distance`, which is maintained [by someone of trust](https://lib.rs/~djc), who maintains a lot of very important crates.
- [x] Make Clippy happy with the first commit.
- [x] Reproduce the #3923 bug without this patch
- [x] Check if the bug disappeared with this PR.
- [x] Test with [the Algolia e-commerce dataset](https://www.notion.so/meilisearch/Algolia-Ecommerce-c5fa3b5f23a7485295df7e87306d5859).
Co-authored-by: Kerollmops <clement@meilisearch.com>
3940: Update mini dashboard v0.2.9 r=gillian-meilisearch a=bidoubiwa
# Pull Request
## What does this PR do?
- Updates the mini-dashboard to version [0.2.9](https://github.com/meilisearch/mini-dashboard/releases/tag/v0.2.9)
## PR checklist
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Charlotte Vermandel <charlottevermandel@gmail.com>
3937: Update Charabia to the last version r=Kerollmops a=ManyTheFish
# Pull Request
## Related issue
Fixes#3924
## What does this PR do?
- Update Charabia
Co-authored-by: ManyTheFish <many@meilisearch.com>
3913: Expose a Puffin server to profile the indexing process r=Kerollmops a=Kerollmops
This PR exposes a puffin HTTP server to expose the internal timing it takes to index documents, delete documents, or update the settings of an index.
<img width="1752" alt="Capture d’écran 2023-07-10 à 18 44 58" src="https://github.com/meilisearch/meilisearch/assets/3610253/a3c7a6bf-db5b-42f4-8be1-c4e31c869843">
## To be done
- [x] Move the puffin HTTP server under a feature flag.
- [x] Use [the `puffin::set_scopes_on` function](https://docs.rs/puffin/latest/puffin/fn.set_scopes_on.html) to toggle it (by using the feature directly).
When this function is called with `false`, [a call to `profile_scope!` talked 1-2ns](https://docs.rs/puffin/latest/puffin/fn.set_scopes_on.html).
- [x] Create a _PROFILING.md_ file explaining how to use it.
- [x] Explain that merging scopes on the interface is not always useful.
- [x] Add more info on the number of batched tasks (using the `puffin::profile_scope!` macro data).
- I added more info, but that's more continuous work when we consider we need more info here and there.
- [x] Clean up some scopes, and don't touch too much code to inject puffin.
- I am not sure that the _index_documents/mod.rs_ function is that complex with the addition of the scope.
- [x] Think about what we consider frames. One indexation operation or the wall program. When must we stop the frame, then?
- What we consider a frame is one single `IndexScheduler::tick` execution.
- We can change that later.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
3932: Add UTM tracking to README r=gillian-meilisearch a=Strift
# Pull Request
Hi `@macraig` `@curquiza` 👋
## Related issue
N/A
## What does this PR do?
This PR adds UTM tracking to the links in the README.
It add UTM params to:
- links in the nav
- links to where2watch
- links in the Features section
- Docs & Getting started links (cc `@guimachiavelli)`
- links in the SDKs section
- links in the Advanced usage section
- links in the Telemetry section
- links in the Get in touch section
Additionally, this PR adds a link to the Meilisearch logo (there is currently none.)
## On the UTM pattern
All links in this PR use the new convention `@gmourier` and I agreed on:
- utm_campaign=oss
- utm_source=github
- utm_medium=meilisearch
- utm_content= where the link is in the page
It's worth considering updating the tracking link for the Cloud, which is the only one that doesn’t follow the new convention. It is currently using `utm_campaign=oss&utm_source=engine&utm_medium=meilisearch`.
Merging analytics from different UTMs is doable on Amplitude, but can't be done in Fathom. Plus, having two different conventions creates knowledge overhead, and is bound to result in corrupt analytics at some point. I suggest we change the Cloud UTM trackers too — the sooner we eat the frog, the better imo.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Strift <strift@Strifts-MacBook-Pro.local>
Co-authored-by: Strift <laurent@meilisearch.com>
3935: Update mini-dashboard to version 0.2.8 r=Kerollmops a=bidoubiwa
# Pull Request
## What does this PR do?
- Updates the mini-dashboard to version [0.2.8](https://github.com/meilisearch/mini-dashboard/releases/tag/v0.2.8)
## PR checklist
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Charlotte Vermandel <charlottevermandel@gmail.com>
3933: Stop computing the update files size r=ManyTheFish a=Kerollmops
This PR, related #3934, removes the part which computes the total size of the `data.ms/update_files` folder, which can take a lot of time when many updates must be processed.
It is not breaking API-side but is breaking on the result we will show to the user. The `databaseSize` field returned by the `/stats` endpoint will be reduced.
Co-authored-by: Kerollmops <clement@meilisearch.com>
3929: Fix a panic when sorting geo fields represented by strings r=Kerollmops a=Kerollmops
This issue fixes#3927 by retrieving and parsing the original string values into f64s. I also added a test to ensure we don't break it in a future version.
Co-authored-by: Kerollmops <clement@meilisearch.com>
3921: Deactivate camel case segmentation r=dureuill a=ManyTheFish
# Pull Request
This PR deactivates the camel case segmentation to retrieve the possibility to accept typos over camel-cased words
## Related issue
Fixes#3869Fixes#3818
## What does this PR do?
- deactivates camelcase segmentation
related to #3919
Co-authored-by: ManyTheFish <many@meilisearch.com>
3907: Add telemetry for define field to search on at query time r=dureuill a=ManyTheFish
Add "attributes_to_search_on" telemetry usage counter:
```json
"attributes_to_search_on": {
"total_number_of_use": 12,
},
```
This measures the number of search queries that the user uses `attributesToSearchOn` field.
related to https://github.com/meilisearch/specifications/pull/251
## reviewers:
- `@macraig` for validating the telemetry's name
- `@dureuill` for validating the code
Co-authored-by: ManyTheFish <many@meilisearch.com>
3915: `attributesToSearchOn` supports wildcards r=ManyTheFish a=dureuill
# Pull Request
## Related issue
Fixes#3912 and #3911
## What does this PR do?
- Adding `*` in the list of `attributesToSearchOn` allows searching on all the `searchableAttributes`.
- If `searchableAttributes contains "*"`, then any attribute is accepted in the `attributesToSearchOn` list.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3918: Update and fix the Test Suite CI r=dureuill a=Kerollmops
This Pull Request renames the _Run test with Rust_ into _Setup test with Rust_ for more clarity and `cargo update -p proc-macro2` to make the project compile with the latest Rust Nightly.
Co-authored-by: Kerollmops <clement@meilisearch.com>
3908: Allow a comma-separated value to the `vector` argument in GET search r=Kerollmops a=dureuill
# Pull Request
For request:
```
curl \
-X GET 'http://localhost:7700/indexes/movies/search?vector=0.123,1.124,244'
```
Before PR:
```
{"message":"Invalid value type for parameter `vector`: expected a string, but found a string: `0,1,2`","code":"invalid_search_vector","type":"invalid_request","link":"https://docs.meilisearch.com/errors#invalid_search_vector"}%
```
After PR:
```
{"hits":[],"query":"","vector":[0.123,1.124,244.0],"processingTimeMs":0,"limit":20,"offset":0,"estimatedTotalHits":1000}%
```
cc `@gmourier` `@bidoubiwa`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3904: Sort by lexicographic order after normalization r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3893
## What does this PR do?
- Re-sort stop words after normalization so they're not sent out-of-order to the FST
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3895: Update README.md r=curquiza a=ferdi05
Adding the free-trial option
# Pull Request
## Related issue
Fixes #<issue_number>
## What does this PR do?
- ...
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Ferdinand Boas <ferdinand.boas@gmail.com>
3897: Add automated tests for `/experimental-features` route r=Kerollmops a=dureuill
# Pull Request
## What does this PR do?
- Make `RuntimeTogglableFeatures` `Eq`
- Add various tests for the `/experimental-features` route
- Integration tests for the route itself
- Integration tests for the effect of enabling `scoreDetails` and `vectorStore` through this route.
- Dump integration tests
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3889: Display the total number of tasks matching a filter/query r=dureuill a=Kerollmops
This PR returns a new field on the `/tasks` routes. The `total` field exposes the total number of tasks that matches the given filter/query. It is useful to display information on a user interface and can help understand when progress is made in processing tasks, i.e., the total number of tasks on `/tasks?statuses=succeeded` will increase over time.
Fixes#3888.
- [ ] Update the specs fo the `/tasks` route.
## How have I implemented it?
I found it much easier to run two times the task filtering system. Once with the original `from` and `limit` parameters and a second time without. The second call will return the total number of tasks that match the query, not only the number of tasks on the current page.
So far, in terms of performance, there doesn't seem to be any issue. I tried different filters with something like 250k tasks. Note that there is a limit of 1M tasks in the queue.
Co-authored-by: Clément Renault <clement@meilisearch.com>
3891: Fix the way we compute the 99th percentile r=dureuill a=Kerollmops
This PR fixes how we compute the 99th percentile by avoiding using float and doing the multiplication and divisions in the correct order avoiding going out of the buffer of timings. You can see the issue on [this rust playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021).
When there are a very small number of successful requests, the number is so tiny that the 99th percentile calculus sometimes gives an index out of the buffer. In this example, the `1`/`1.0` represent the number of timings you collected (one). As you can see, the float computation gives us the index `1.0`, with is out of a vector of only one value. This makes the engine generate a `null` value.
```rust
1 * 99 / 100 = 0 // with integers
0.99_f64 * (1.0 - 1.0) + 1.0 = 1.0 // with floats
```
Co-authored-by: Clément Renault <clement@meilisearch.com>
3890: Fix the analytics of the sort facet values by count feature r=dureuill a=Kerollmops
This PR ensures we return the right analytics from the settings route.
Co-authored-by: Clément Renault <clement@meilisearch.com>
3877: update the total_received properties of multiple events r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes#3814
## What does this PR do?
-fix name of `total_received` for several events
Co-authored-by: Tamo <tamo@meilisearch.com>
3878: Remove unsafe `atty` dependency r=dureuill a=Kerollmops
This PR replaces the `atty` dependency with the `is-terminal` one. We do that to fix GHSA-g98v-hv3f-hcfr.
Co-authored-by: Kerollmops <clement@meilisearch.com>
3851: Expose lastUpdate and isIndexing in /stats endpoint r=dureuill a=gentcys
# Pull Request
## Related issue
Fixes#3843
## What does this PR do?
- expose lastUpdate in `/stats` endpoint
- expose isIndex in `stats` endpoint
- add a method `is_task_processing` in index-scheduler/src/lib.rs.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Cong Chen <cong.chen@ocrlabs.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3874: Update version for the next release (v1.3.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: gillian-meilisearch <gillian-meilisearch@users.noreply.github.com>
3873: Format let-else ❤️🎉 r=Kerollmops a=dureuill
# Pull Request
Allows passing CI after landing of 6162f6f123
## What does this PR do?
- `cargo +nightly fmt`
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3866: Update charabia v0.8.0 r=dureuill a=ManyTheFish
# Pull Request
Update Charabia:
- enhance Japanese segmentation
- enhance Latin Tokenization
- words containing `_` are now properly segmented into several words
- brackets `{([])}` are no more considered as context separators so word separated by brackets are now considered near together for the proximity ranking rule
- fixes#3815
- fixes#3778
- fixes [product#151](https://github.com/meilisearch/product/discussions/151)
> Important note: now the float numbers are segmented around the `.` so `3.22` is segmented as [`3`, `.`, `22`] but the middle dot isn't considered as a hard separator, which means that if we search `3.22` we find documents containing `3.22`
Co-authored-by: ManyTheFish <many@meilisearch.com>
3780: Be able to sort facet values by alpha or count r=dureuill a=Kerollmops
This PR introduces a new `sortFacetValuesBy` settings parameter to expose the facet distribution in either count or lexicographic/alpha order.
## Mini Spec of the `sortFacetValuesBy` Settings Parameter
This parameter can be set in the settings to change how the engine returns the facet values. There are two possible values to this parameter.
Please note that the current behavior changed a bit, and keys are returned in lexicographic order instead of undefined order. The previous order wasn't defined as we were using a `HashMap`, which returns entries in hash order (undefined), and we are now using an `IndexMap`, which returns them in insertion order (the order we actually want).
Also, note that there are performance issues when the dataset is enormous. Here are the timings of the engine running on my Macbook Pro M1 (16Go of RAM). [The dataset is 40 million songs file](https://www.notion.so/meilisearch/Songs-from-MusicBrainz-686e31b2bd3845898c7746f502a6e117), and the database size is about 50GiB. Even if you think 800ms is not that high, don't forget that the API is public, and anybody can ask for multiple facets in a single query.
| Search Kind | Get Facets | Max Values per Facet | Time for Alpha | Time for Count | Count but with #3788 |
|------------:|------------|----------------------|:--------------:|----------------|----------------------|
| Placeholder | genres | default (100) | 7ms | 187ms | 122ms |
| Placeholder | genres | 20 | 6ms | 124ms | 75ms |
| Placeholder | album | default (100) | 9ms | 808ms | 677ms |
| Placeholder | album | 20 | 8ms | 579ms | 446ms |
| Placeholder | artist | default (100) | 9ms | 462ms | 344ms |
| Placeholder | artist | 20 | 9ms | 341ms | 246ms |
### Order Values in Alphanumeric Order
This is the default one. Values will be returned by lexicographic order, ascending from A to Z.
```bash
# First, update the settings
curl 'localhost:7700/indexes/movies/settings/facetting' \
-H "Content-Type: application/json" \
-d '{ "sortFacetValuesBy": { "*": "alpha" } }'
# Then, ask for the facet distribution
curl 'localhost:7700/indexes/movies/search?facets=genres'
```
```json5
{
"hits": [
/* list of results */
],
"query": "",
"processingTimeMs": 0,
"limit": 20,
"offset": 0,
"estimatedTotalHits": 1000,
"facetDistribution": {
"genres": {
"Action": 3215,
"Adventure": 1972,
"Animation": 1577,
"Comedy": 5883,
"Crime": 1808,
// ...
}
},
"facetStats": {}
}
```
### Order Values in Count Order
Facet values are sorted by decreasing count. The count is the number of records containing this facet value in the query results.
```bash
# First, update the settings
curl 'localhost:7700/indexes/movies/settings/facetting' \
-H "Content-Type: application/json" \
-d '{ "sortFacetValuesBy": { "*": "count" } }'
# Then, ask for the facet distribution
curl 'localhost:7700/indexes/movies/search?facets=genres'
```
```json5
{
"hits": [
/* list of results */
],
"query": "",
"processingTimeMs": 0,
"limit": 20,
"offset": 0,
"estimatedTotalHits": 1000,
"facetDistribution": {
"genres": {
"Drama": 7337,
"Comedy": 5883,
"Action": 3215,
"Thriller": 3189,
"Romance": 2507,
// ...
}
},
"facetStats": {}
}
```
## Todo List
- [x] Add tests
- [x] Send analytics when a user change the `sortFacetValuesBy`
- [x] Create a prototype and announce it in https://github.com/meilisearch/product/discussions/519.
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
3864: Remove `/experimental-features` verbs that weren't in the PRD r=dureuill a=dureuill
Removes:
- POST `/experimental-features`
- DELETE `/experimental-features`
keeping only:
- PATCH `/experimental-features`
- GET `/experimental-features`
The two routes that are described in the PRD.
Following `@guimachiavelli's` [question](https://github.com/meilisearch/documentation/issues/2482#issuecomment-1611845372) about the POST route.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3699: Search for Facet Values r=Kerollmops a=Kerollmops
This PR introduces the first version of [the _Search for Facet Values_ feature](https://github.com/meilisearch/product/discussions/515) that allows a user to search for facets, by optionally using a prefix string and optionally specifying the `q` and `filter` original search parameters to restrict the candidates to search in.
The steps to merge it into Meilisearch will first start by providing prototype Docker images. This way users will be able to test the prototypes before using them.
The current route to use the _Search for Facet Values_ feature is the `POST /indexes/{index}/facet-search` where the body is a JSON object that looks like the following:
```json5
{
"q": "spiderman", // optional
"filter": "rating > 10", // optional
"facetName": "genres",
"facetQuery": "a" // optional
}
```
## What is missing?
- [x] Send some analytics.
- [x] Support the `matchingStrategy` parameter.
- [x] Make sure that the errors are the right ones.
- [x] Use the [Index typo tolerance settings](https://www.meilisearch.com/docs/learn/configuration/typo_tolerance#minwordsizefortypos) when matching facet values.
- [x] minWordSizeForTypos.oneTypo
- [x] minWordSizeForTypos.twoTypo
- [x] Add tests
- [x] Log the time it took to compute the results.
- [x] Fix the compilation warnings.
- [x] [Create an issue to fix potential performance issues when indexing](https://github.com/meilisearch/meilisearch/issues/3862).
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
3861: Add "meilisearch" prefix to last metrics that were missing it r=Kerollmops a=dureuill
# Pull Request
## Related issue
Related to #3790
## What does this PR do?
- change implementation to follow the spec on metrics name
- regenerate grafana dashboard from the code
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3834: Define searchable fields at runtime r=Kerollmops a=ManyTheFish
## Summary
This feature allows the end-user to search in one or multiple attributes using the search parameter `attributesToSearchOn`:
```json
{
"q": "Captain Marvel",
"attributesToSearchOn": ["title"]
}
```
This feature act like a filter, forcing Meilisearch to only return the documents containing the requested words in the attributes-to-search-on. Note that, with the matching strategy `last`, Meilisearch will only ensure that the first word is in the attributes-to-search-on, but, the retrieved documents will be ordered taking into account the word contained in the attributes-to-search-on.
## Trying the prototype
A dedicated docker image has been released for this feature:
#### last prototype version:
```bash
docker pull getmeili/meilisearch:prototype-define-searchable-fields-at-search-time-1
```
#### others prototype versions:
```bash
docker pull getmeili/meilisearch:prototype-define-searchable-fields-at-search-time-0
```
## Technical Detail
The attributes-to-search-on list is given to the search context, then, the search context uses the `fid_word_docids`database using only the allowed field ids instead of the global `word_docids` database. This is the same for the prefix databases.
The database cache is updated with the merged values, meaning that the union of the field-id-database values is only made if the requested key is missing from the cache.
### Relevancy limits
Almost all ranking rules behave as expected when ordering the documents.
Only `proximity` could miss-order documents if all the searched words are in the restricted attribute but a better proximity is found in an ignored attribute in a document that should be ranked lower. I put below a failing test showing it:
```rust
#[actix_rt::test]
async fn proximity_ranking_rule_order() {
let server = Server::new().await;
let index = index_with_documents(
&server,
&json!([
{
"title": "Captain super mega cool. A Marvel story",
// Perfect distance between words in an ignored attribute
"desc": "Captain Marvel",
"id": "1",
},
{
"title": "Captain America from Marvel",
"desc": "a Shazam ersatz",
"id": "2",
}]),
)
.await;
// Document 2 should appear before document 1.
index
.search(json!({"q": "Captain Marvel", "attributesToSearchOn": ["title"], "attributesToRetrieve": ["id"]}), |response, code| {
assert_eq!(code, 200, "{}", response);
assert_eq!(
response["hits"],
json!([
{"id": "2"},
{"id": "1"},
])
);
})
.await;
}
```
Fixing this would force us to create a `fid_word_pair_proximity_docids` and a `fid_word_prefix_pair_proximity_docids` databases which may multiply the keys of `word_pair_proximity_docids` and `word_prefix_pair_proximity_docids` by the number of attributes in the searchable_attributes list. If we think we should fix this test, I'll suggest doing it in another PR.
## Related
Fixes#3772
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
3745: tests: add unit test for `PayloadTooLarge` error r=curquiza a=cymruu
# Pull Request
Add a unit test for the `Payload`, which verifies that a request with a payload that is too large is rejected with the appropriate message.
This was requested in this PR https://github.com/meilisearch/meilisearch/pull/3739
## Related issue
https://github.com/meilisearch/meilisearch/pull/3739
## What does this PR do?
- Adds requested test
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [ ] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Filip Bachul <filipbachul@gmail.com>
3859: Merge all analytics events pertaining to updating the experimental features r=Kerollmops a=dureuill
Follow-up to #3850
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3825: Accept semantic vectors and allow users to query nearest neighbors r=Kerollmops a=Kerollmops
This Pull Request brings a new feature to the current API. The engine accepts a new `_vectors` field akin to the `_geo` one. This vector is stored in Meilisearch and can be retrieved via search. This work is the first step toward hybrid search, bringing the best of both worlds: keyword and semantic search ❤️🔥
## ToDo
- [x] Make it possible to get the `limit` nearest neighbors from a user-generated vector by using the `vector` field of search route.
- [x] Delete the documents and vectors from the HNSW-related data structures.
- [x] Do it the slow and ugly way (we need to be able to iterate over all the values).
- [ ] Do it the efficient way (Wait for a new method or implement it myself).
- [ ] ~~Move from the `hnsw` crate to the hgg one~~ The hgg crate is too slow.
Meilisearch takes approximately 88s to answer a query. It is related to the time it takes to deserialize the `Hgg` data structure or search in it. I didn't take the time to measure precisely. We moved back to the hnsw crate which takes approximately 40ms to answer.
- [ ] ~~Wait for a fix for https://github.com/rust-cv/hgg/issues/4.~~
- [x] Fix the current dot product function.
- [x] Fill in the other `SearchResult` fields.
- [x] Remove the `hnsw` dependency of the meilisearch crate.
- [x] Fix the pages by taking the offset into account.
- [x] Release a first prototype https://github.com/meilisearch/product/discussions/621#discussioncomment-6183647
- [x] Make the pagination and filtering faster and more correct.
- [x] Return the original vector in the output search results (like `query`).
- [x] Return an `_semanticSimilarity` field in the documents (it's a dot product)
- [x] Return this score even if the `_vectors` field is not displayed
- [x] Rename the field `_semanticScore`.
- [ ] Return the `_geoDistance` value even if the `_geo` field is not displayed
- [x] Store the HNSW on possibly multiple LMDB values.
- [ ] Measure it and make it faster if needed
- [ ] Export the `ReadableSlices` type into a small external crate
- [x] Accept an `_vectors` field instead of the `_vector` one.
- [x] Normalize all vectors.
- [ ] Remove the `_vectors` field from the default searchable attributes (as we do with `_geo`?).
- [ ] Correctly compute the candidates by remembering the documents having a valid `_vectors` field.
- [ ] Return the right errors:
- [ ] Return an error when the query vector is not the same length as the vectors in the HNSW.
- [ ] We must return the user document id that triggered the vector dimension issue.
- [x] If an indexation error occurs.
- [ ] Fix the error codes when using the search route.
- [ ] ~~Introduce some settings:~~
We currently ensure that the vector length is consistent over the whole set of documents and return an error for when a vector dimension doesn't follow the current number of dimensions.
- [ ] The length of the vector the user will provide.
- [ ] The distance function (we only support dot as of now).
- [ ] Introduce other distance functions
- [ ] Euclidean
- [ ] Dot Product
- [ ] Cosine
- [ ] Make them SIMD optimized
- [ ] Give credit to qdrant
- [ ] Add tests.
- [ ] Write a mini spec.
- [ ] Release it in v1.3 as an experimental feature.
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
3853: docs: fixed some broken links r=gillian-meilisearch a=0xflotus
Some of the links in the README file were broken.
Co-authored-by: 0xflotus <0xflotus@gmail.com>
3850: Experimental features r=Kerollmops a=dureuill
# Pull Request
## Related issue
- Fixes https://github.com/meilisearch/meilisearch/issues/3857
- Related to https://github.com/meilisearch/meilisearch/issues/3771
## What does this PR do?
### Example
<details>
<summary>Using the feature to enable `scoreDetails`</summary>
```json
❯ curl \
-X POST 'http://localhost:7700/indexes/index-word-count-10-count/search' \
-H 'Content-Type: application/json' \
--data-binary '{ "q": "Batman", "limit": 1, "showRankingScoreDetails": true, "attributesToRetrieve": ["title"]}' | jsonxf
{
"message": "Computing score details requires enabling the `score details` experimental feature. See https://github.com/meilisearch/product/discussions/674",
"code": "feature_not_enabled",
"type": "invalid_request",
"link": "https://docs.meilisearch.com/errors#feature_not_enabled"
}
```
```json
❯ curl \
-X PATCH 'http://localhost:7700/experimental-features/' \
-H 'Content-Type: application/json' \
--data-binary '{
"scoreDetails": true
}'
{"scoreDetails":true,"vectorSearch":false}
```
```json
❯ curl \
-X POST 'http://localhost:7700/indexes/index-word-count-10-count/search' \
-H 'Content-Type: application/json' \
--data-binary '{ "q": "Batman", "limit": 1, "showRankingScoreDetails": true, "attributesToRetrieve": ["title"]}' | jsonxf
{
"hits": [
{
"title": "Batman",
"_rankingScoreDetails": {
"words": {
"order": 0,
"matchingWords": 1,
"maxMatchingWords": 1,
"score": 1.0
},
"typo": {
"order": 1,
"typoCount": 0,
"maxTypoCount": 1,
"score": 1.0
},
"proximity": {
"order": 2,
"score": 1.0
},
"attribute": {
"order": 3,
"attribute_ranking_order_score": 1.0,
"query_word_distance_score": 1.0,
"score": 1.0
},
"exactness": {
"order": 4,
"matchType": "exactMatch",
"score": 1.0
}
}
}
],
"query": "Batman",
"processingTimeMs": 3,
"limit": 1,
"offset": 0,
"estimatedTotalHits": 46
}
```
</details>
### User standpoint
- Add new route GET/POST/PATCH/DELETE `/experimental-features` to switch on or off some of the experimental features in a manner persistent between instance restarts
- Use these new routes to allow setting on/off the following experimental features:
- vector store **TODO:** fill in issue
- score details (related to https://github.com/meilisearch/meilisearch/issues/3771)
- Make the way of checking feature availability and error message uniform for the Prometheus metrics experimental feature
- Save the enabled features in dump, restore from dumps
- **TODO:** tests:
- Test new security permissions (do they allow access with ALL, do they prevent access when missing)
- Test dump behavior, in particular ability to import existing v6 dumps
- Test basic behavior when calling the rule
### Implementation standpoint
- New DB "experimental-features"
- dumps are modified to save the state of that new DB as a `experimental-features.json` file, that is then loaded back when importing the dump. This doesn't change the dump version, as the file is optional and it missing will not cause the dump to fail
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3821: Add normalized and detailed scores to documents returned by a query r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes#3771
## What does this PR do?
### User standpoint
<details>
<summary>Request ranking score</summary>
```
echo '{
"q": "Badman dark knight returns",
"showRankingScore": true,
"limit": 10,
"attributesToRetrieve": ["title"]
}' | mieli search -i index-word-count-10-count
```
</details>
<details>
<summary>Response</summary>
```json
{
"hits": [
{
"title": "Batman: The Dark Knight Returns, Part 1",
"_rankingScore": 0.947520325203252
},
{
"title": "Batman: The Dark Knight Returns, Part 2",
"_rankingScore": 0.947520325203252
},
{
"title": "Batman Unmasked: The Psychology of the Dark Knight",
"_rankingScore": 0.6657594086021505
},
{
"title": "Legends of the Dark Knight: The History of Batman",
"_rankingScore": 0.6654905913978495
},
{
"title": "Angel and the Badman",
"_rankingScore": 0.2196969696969697
},
{
"title": "Angel and the Badman",
"_rankingScore": 0.2196969696969697
},
{
"title": "Batman",
"_rankingScore": 0.11553030303030302
},
{
"title": "Batman Begins",
"_rankingScore": 0.11553030303030302
},
{
"title": "Batman Returns",
"_rankingScore": 0.11553030303030302
},
{
"title": "Batman Forever",
"_rankingScore": 0.11553030303030302
}
],
"query": "Badman dark knight returns",
"processingTimeMs": 12,
"limit": 10,
"offset": 0,
"estimatedTotalHits": 46
}
```
</details>
- If adding a `showRankingScore` parameter to the search query, then documents returned by a search now contain an additional field `_rankingScore` that is a float bigger than 0 and lower or equal to 1.0. This field represents the relevancy of the document, relatively to the search query and the settings of the index, with 1.0 meaning "perfect match" and 0 meaning "not matching the query" (Meilisearch should never return documents not matching the query at all).
- The `sort` and `geosort` ranking rules do not influence the `_rankingScore`.
<details>
<summary>Request detailed ranking scores</summary>
```
echo '{
"q": "Badman dark knight returns",
"showRankingScoreDetails": true,
"limit": 5,
"attributesToRetrieve": ["title"]
}' | mieli search -i index-word-count-10-count
```
</details>
<details>
<summary>Response</summary>
```json
{
"hits": [
{
"title": "Batman: The Dark Knight Returns, Part 1",
"_rankingScoreDetails": {
"words": {
"order": 0,
"matchingWords": 4,
"maxMatchingWords": 4,
"score": 1.0
},
"typo": {
"order": 1,
"typoCount": 1,
"maxTypoCount": 4,
"score": 0.8
},
"proximity": {
"order": 2,
"score": 0.9545454545454546
},
"attribute": {
"order": 3,
"attributes_ranking_order": 1.0,
"attributes_query_word_order": 0.926829268292683,
"score": 0.926829268292683
},
"exactness": {
"order": 4,
"matchType": "noExactMatch",
"score": 0.26666666666666666
}
}
},
{
"title": "Batman: The Dark Knight Returns, Part 2",
"_rankingScoreDetails": {
"words": {
"order": 0,
"matchingWords": 4,
"maxMatchingWords": 4,
"score": 1.0
},
"typo": {
"order": 1,
"typoCount": 1,
"maxTypoCount": 4,
"score": 0.8
},
"proximity": {
"order": 2,
"score": 0.9545454545454546
},
"attribute": {
"order": 3,
"attributes_ranking_order": 1.0,
"attributes_query_word_order": 0.926829268292683,
"score": 0.926829268292683
},
"exactness": {
"order": 4,
"matchType": "noExactMatch",
"score": 0.26666666666666666
}
}
},
{
"title": "Batman Unmasked: The Psychology of the Dark Knight",
"_rankingScoreDetails": {
"words": {
"order": 0,
"matchingWords": 3,
"maxMatchingWords": 4,
"score": 0.75
},
"typo": {
"order": 1,
"typoCount": 1,
"maxTypoCount": 3,
"score": 0.75
},
"proximity": {
"order": 2,
"score": 0.6666666666666666
},
"attribute": {
"order": 3,
"attributes_ranking_order": 1.0,
"attributes_query_word_order": 0.8064516129032258,
"score": 0.8064516129032258
},
"exactness": {
"order": 4,
"matchType": "noExactMatch",
"score": 0.25
}
}
},
{
"title": "Legends of the Dark Knight: The History of Batman",
"_rankingScoreDetails": {
"words": {
"order": 0,
"matchingWords": 3,
"maxMatchingWords": 4,
"score": 0.75
},
"typo": {
"order": 1,
"typoCount": 1,
"maxTypoCount": 3,
"score": 0.75
},
"proximity": {
"order": 2,
"score": 0.6666666666666666
},
"attribute": {
"order": 3,
"attributes_ranking_order": 1.0,
"attributes_query_word_order": 0.7419354838709677,
"score": 0.7419354838709677
},
"exactness": {
"order": 4,
"matchType": "noExactMatch",
"score": 0.25
}
}
},
{
"title": "Angel and the Badman",
"_rankingScoreDetails": {
"words": {
"order": 0,
"matchingWords": 1,
"maxMatchingWords": 4,
"score": 0.25
},
"typo": {
"order": 1,
"typoCount": 0,
"maxTypoCount": 1,
"score": 1.0
},
"proximity": {
"order": 2,
"score": 1.0
},
"attribute": {
"order": 3,
"attributes_ranking_order": 1.0,
"attributes_query_word_order": 0.8181818181818182,
"score": 0.8181818181818182
},
"exactness": {
"order": 4,
"matchType": "noExactMatch",
"score": 0.3333333333333333
}
}
}
],
"query": "Badman dark knight returns",
"processingTimeMs": 9,
"limit": 5,
"offset": 0,
"estimatedTotalHits": 46
}
```
</details>
- If adding a `showRankingScoreDetails` parameter to the search query, then the returned documents will now contain an additional `_rankingScoreDetails` field that is a JSON object containing one field per ranking rule that was applied, whose value is a JSON object with the following fields:
- `order`: a number indicating the order this rule was applied (0 is the first applied ranking rule)
- `score` (except for `sort` and `geosort`): a float indicating how the document matched this particular rule.
- other fields that are specific to the rule, indicating for example how many words matched for a document and how many typos were counted in a matching document.
- If the `displayableAttributes` list is defined in the settings of the index, any ranking rule using an attribute **not** part of that list will be marked as `<hidden-rule>` in the `_rankingScoreDetails`.
- Search queries that are part of a `multi-search` requests are modified in the same way and each of the queries can take the `showRankingScore` and `showRankingScoreDetails` parameters independently. The results are still returned in separate lists and providing a unified list of results between multiple queries is not in the scope of this PR (but is unblocked by this PR and can be done manually by using the scores of the various documents).
### Implementation standpoint
- Fix difference in how the position of terms were computed at indexing time and query time: this difference meant that a query containing a hard separator would fail the exactness check.
- Fix the id reported by the sort ranking rule (very minor)
- Change how the cost of removing words is computed. After this change the cost no longer works for any other ranking rule than `words`. Also made `words` have a cost of 0 such that the entire cost of `words` is given by the termRemovalStrategy. The new cost computation makes it so the score is computed in a way consistent with the number of words in the query. Additionally, the words that appear in phrases in the query are also counted as matching words.
- When any score computation is requested through `showRankingScore` or `showRankingScoreDetails`, remove optimization where ranking rules are not executed on buckets of a single document: this is important to allow the computation of an accurate score.
- add virtual conditions to fid and position to always have the max cost: this ensures that the score is independent from the dataset
- the Position ranking rule now takes into account the distance to the position of the word in the query instead of the distance to the position 0.
- modified proximity ranking rule cost calculation so that the cost is 0 for documents that are perfectly matching the query
- Add a new `milli::score_details` module containing all the types that are involved in score computation.
- Make it so a bucket of result now contains a `ScoreDetails` and changed the ranking rules to produce their `ScoreDetails`.
- Expose the scores in the REST API.
- Add very light analytics for scoring.
- Update the search tests to add the expected scores.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3842: fix some typos r=dureuill a=cuishuang
# Pull Request
## Related issue
Fixes #<issue_number>
## What does this PR do?
- fix some typos
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: cui fliter <imcusg@gmail.com>
3799: Fix error messages in `check-release.sh` r=curquiza a=vvv
- `check_tag`: Report file name correctly. Use named variables.
- Introduce `read_version` helper function. Simplify the implementation.
- Show meaningful error message if `GITHUB_REF` is not set or its format is incorrect.
Co-authored-by: Valeriy V. Vorotyntsev <valery.vv@gmail.com>
3844: Fix SDK CI (again) r=curquiza a=curquiza
Following this PR: https://github.com/meilisearch/meilisearch/pull/3813
Sorry `@Kerollmops,` here is (I hope) the latest fix 🙏 I made tests last time that were not sufficient. I really did a lot this time. I hope I have not missed anything.
Co-authored-by: curquiza <clementine@meilisearch.com>
- `check_tag`: Report file name correctly. Use named variables.
- Introduce `read_version` helper function. Simplify the implementation.
- Show meaningful error message if `GITHUB_REF` is not set or its format
is incorrect.
3670: Fix addition deletion bug r=irevoire a=irevoire
The first commit of this PR is a revert of https://github.com/meilisearch/meilisearch/pull/3667. It re-enable the auto-batching of addition and deletion of tasks. No new changes have been introduced outside of `milli`. So all the changes you see on the autobatcher have actually already been reviewed.
It fixes https://github.com/meilisearch/meilisearch/issues/3440.
### What was happening?
The issue was that the `external_documents_ids` generated in the `transform` were used in a very strange way that wasn’t compatible with the deletion of documents.
Instead of doing a clear merge between the external document IDs of the DB and the one returned by the transform + writing it on disk, we were doing some weird tricks with the soft-deleted to avoid writing the fst on disk as much as possible.
The new algorithm may be a bit slower but is way more straightforward and doesn’t change depending on if the soft deletion was used or not. Here is a list of the changes introduced:
1. We now do a clear distinction between the `new_external_documents_ids` coming from the transform and only held on RAM and the `external_documents_ids` coming from the DB.
2. The `new_external_documents_ids` (coming out of the transform) are now represented as an `fst`. We don't need to struggle with the hard, soft distinction + the soft_deleted => That's easier to understand
3. When indexing documents, we merge the `external_documents_ids` coming from the DB and the `new_external_documents_ids` coming from the transform.
### Other things introduced in this PR
Since we constantly have to write small, very specialized fuzzers for this kind of bug, we decided to push the one used to reproduce this bug.
It's not perfect, but it's easy to improve in the future.
It'll also run for as long as possible on every merge on the main branch.
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Loïc Lecrenier <loic.lecrenier@icloud.com>
3835: Add more documentation to graph-based ranking rule algorithms + comment cleanup r=Kerollmops a=loiclec
In addition to documenting the `cheapest_path.rs` file, this PR cleans up a few outdated comments as well as some TODOs. These TODOs have been moved to https://github.com/meilisearch/meilisearch/issues/3776
Co-authored-by: Loïc Lecrenier <loic.lecrenier@icloud.com>
3836: Remove trailing whitespace in snapshots r=dureuill a=dureuill
# Pull Request
## Related issue
No issue, maintenance
## What does this PR do?
- Remove trailing whitespace in snapshots by adding a trailing `|` at the end of lines that would previously end with fixed-width integers
- This allows contributors whose editor is configured to remove trailing whitespace not to modify the tests when changing an unrelated part of the file containing the tests
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3813: Fix SDK CI for scheduled jobs r=curquiza a=curquiza
The SDK CI does not run for the scheduled job (`cron`) every day, and only works for manual triggers.
I added a job to define the Docker image we use depending on the event: `worflow_dispatch` = manual triggering, or `scheduled` = cron jobs
Co-authored-by: curquiza <clementine@meilisearch.com>
3824: Changes the way words are counted in the word count DB r=ManyTheFish a=dureuill
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3823
## What does this PR do?
- Apply offset when parsing query that is consistent with the indexing
### DB breaking changes
- Count the number of words in `field_id_word_count_docids`
- raise limit of word count for storing the entry in the DB from 10 to 30
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3789: Improve the metrics r=dureuill a=irevoire
# Pull Request
## Related issue
Implements https://github.com/meilisearch/meilisearch/issues/3790
Associated specification: https://github.com/meilisearch/specifications/pull/242
## Be cautious; it's DB-breaking 😱
While reviewing and after merging this PR, be cautious; if you already have a `data.ms` and run meilisearch with this code on it, it won't work because we need to cache a new information on the index stats (that are backed up on disk). You'll get internal errors.
### About the breaking-change label
We only break the API of the metrics route, which does not pose any problem since it's experimental.
## What does this PR do?
- Create a method to get the « facet distribution » of the task queue.
- Prefix all the metrics by `meilisearch_`
- Add the real database size used by meilisearch
- Add metrics on the task queue
- Update the grafana dashboard to these new changes
- Move the dashboard to the `assets` directory
- Provide a new prometheus file to scrape meilisearch easily
Co-authored-by: Tamo <tamo@meilisearch.com>
3788: Use `RoaringBitmap::deserialize_unchecked_from` to reduce the deserialization time r=irevoire a=Kerollmops
This pull request replaces the `RoaringBitmap::deserialize_from` methods with the `deserialize_unchecked_from` to avoid doing too much checks. We know the written bitmaps are valid as we do not disable the checks during the indexation phase.
I did a small test with #3780 and discovered that the deserialization time changed from 32% to 9.46% when using these changes. It seems it was low-hanging fruit hidden behind a leaf.
Co-authored-by: Kerollmops <clement@meilisearch.com>
3803: Bump Swatinem/rust-cache from 2.2.1 to 2.4.0 r=curquiza a=dependabot[bot]
Bumps [Swatinem/rust-cache](https://github.com/Swatinem/rust-cache) from 2.2.1 to 2.4.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/releases">Swatinem/rust-cache's releases</a>.</em></p>
<blockquote>
<h2>v2.4.0</h2>
<ul>
<li>Fix cache key stability.</li>
<li>Use 8 character hash components to reduce the key length, making it more readable.</li>
</ul>
<h2>v2.3.0</h2>
<ul>
<li>Add <code>cache-all-crates</code> option, which enables caching of crates installed by workflows.</li>
<li>Add installed packages to cache key, so changes to workflows that install rust tools are detected and cached properly.</li>
<li>Fix cache restore failures due to upstream bug.</li>
<li>Fix <code>EISDIR</code> error due to globed directories.</li>
<li>Update runtime <code>`@actions/cache</code>,` <code>`@actions/io</code>` and dev <code>typescript</code> dependencies.</li>
<li>Update <code>npm run prepare</code> so it creates distribution files with the right line endings.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/blob/master/CHANGELOG.md">Swatinem/rust-cache's changelog</a>.</em></p>
<blockquote>
<h2>2.4.0</h2>
<ul>
<li>Fix cache key stability.</li>
<li>Use 8 character hash components to reduce the key length, making it more readable.</li>
</ul>
<h2>2.3.0</h2>
<ul>
<li>Add <code>cache-all-crates</code> option, which enables caching of crates installed by workflows.</li>
<li>Add installed packages to cache key, so changes to workflows that install rust tools are detected and cached properly.</li>
<li>Fix cache restore failures due to upstream bug.</li>
<li>Fix <code>EISDIR</code> error due to globed directories.</li>
<li>Update runtime <code>`@actions/cache</code>,` <code>`@actions/io</code>` and dev <code>typescript</code> dependencies.</li>
<li>Update <code>npm run prepare</code> so it creates distribution files with the right line endings.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="988c164c3d"><code>988c164</code></a> 2.4.0</li>
<li><a href="bb80d0f127"><code>bb80d0f</code></a> chore: use 8 character hash components (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/143">#143</a>)</li>
<li><a href="ad97570a01"><code>ad97570</code></a> fix: cache key stability (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/142">#142</a>)</li>
<li><a href="060bda31e0"><code>060bda3</code></a> 2.3.0</li>
<li><a href="865fd1f6db"><code>865fd1f</code></a> "update dependencies and changelog"</li>
<li><a href="7c7e41ab01"><code>7c7e41a</code></a> chore: changelog v2.3.0 (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/139">#139</a>)</li>
<li><a href="68aeeba167"><code>68aeeba</code></a> chore: use linefix to ensure platform line endings (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/135">#135</a>)</li>
<li><a href="def0926359"><code>def0926</code></a> feat: add option to cache all crates (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/137">#137</a>)</li>
<li><a href="827c240e23"><code>827c240</code></a> fix: cache key dependency on installed packages (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/138">#138</a>)</li>
<li><a href="5e9fae966f"><code>5e9fae9</code></a> fix: cache restore failures (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/136">#136</a>)</li>
<li>Additional commits viewable in <a href="https://github.com/Swatinem/rust-cache/compare/v2.2.1...v2.4.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
3792: fix the type of the document deletion by filter tasks r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3791
## What does this PR do?
- Hide the deleteDocumentByFilter internal type from the users.
Co-authored-by: Tamo <tamo@meilisearch.com>
3786: Consistently use wrapping add to avoid overflow in debug when query s… r=dureuill a=dureuill
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3785
## What does this PR do?
- Some of the code paths would erroneously use the default addition operator that has the semantics that "overflow is an error, checked at runtime in debug" instead of the intended "overflow is expected" semantics that this code use (this code is using `u16::MAX` as a sentinel). This PR makes it so the wrapping add operator is used everywhere.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3781: Revert "Improve docker cache" r=Kerollmops a=curquiza
Reverts meilisearch/meilisearch#3566 because does not work as expected, and so I want to remove useless complexity from the CI and Dockerfile
Co-authored-by: Clémentine U. - curqui <clementine@meilisearch.com>
3775: Last error code changes on the new get/delete documents routes r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes#3774
## What does this PR do?
Following the specification: https://github.com/meilisearch/specifications/pull/236
1. Get rid of the `invalid_document_delete_filter` and always use the `invalid_document_filter`
2. Introduce a new `missing_document_filter` instead of returning `invalid_document_delete_filter` (that’s consistent with all the other routes that have a mandatory parameter)
3. Always return the `original_filter` in the details (potentially set to `null`) instead of hiding it if it wasn’t used
Co-authored-by: Tamo <tamo@meilisearch.com>
3768: Fix bugs in graph-based ranking rules + make `words` a graph-based ranking rule r=dureuill a=loiclec
This PR contains three changes:
## 1. Don't call the `words` ranking rule if the term matching strategy is `All`
This is because the purpose of `words` is only to remove nodes from the query graph. It would never do any useful work when the matching strategy was `All`. Remember that the universe was already computed before by computing all the docids corresponding to the "maximally reduced" query graph, which, in the case of `All`, is equal to the original graph.
## 2. The `words` ranking rule is replaced by a graph-based ranking rule.
This is for three reasons:
1. **performance**: graph-based ranking rules benefit from a lot of optimisations by default, which ensures that they are never too slow. The previous implementation of `words` could call `compute_query_graph_docids` many times if some words had to be removed from the query, which would be quite expensive. I was especially worried about its performance in cases where it is placed right after the `sort` ranking rule. Furthermore, `compute_query_graph_docids` would clone a lot of bitmaps many times unnecessarily.
2. **consistency**: every other ranking rule (except `sort`) is graph-based. It makes sense to implement `words` like that as well. It will automatically benefit from all the features, optimisations, and bug fixes that all the other ranking rules get.
3. **surfacing bugs**: as the first ranking rule to be called (most of the time), I'd like `words` to behave the same as the other ranking rules so that we can quickly detect bugs in our graph algorithms. This actually already happened, which is why this PR also contains a bug fix.
## 3. Fix the `update_all_costs_before_nodes` function
It is a bit difficult to explain what was wrong, but I'll try. The bug happened when we had graphs like:
<img width="730" alt="Screenshot 2023-05-16 at 10 58 57" src="https://github.com/meilisearch/meilisearch/assets/6040237/40db1a68-d852-4e89-99d5-0d65757242a7">
and we gave the node `is` as argument.
Then, we'd walk backwards from the node breadth-first. We'd update the costs of:
1. `sun`
2. `thesun`
3. `start`
4. `the`
which is an incorrect order. The correct order is:
1. `sun`
2. `thesun`
3. `the`
4. `start`
That is, we can only update the cost of a node when all of its successors have either already been visited or were not affected by the update to the node passed as argument. To solve this bug, I factored out the graph-traversal logic into a `traverse_breadth_first_backward` function.
Co-authored-by: Loïc Lecrenier <loic.lecrenier@me.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3757: Adjust the cost of edges in the `position` ranking rule by bucketing positions more aggressively r=loiclec a=loiclec
This PR significantly improves the performance of the `position` ranking rule when:
1. a query contains many words
2. the `position` ranking rule needs to be called many times
3. the score of the documents according to `position` is high
These conditions greatly increase:
1. the number of edge traversals that are needed to find a valid path from the `start` node to the `end` node
2. the number of edges that need to be deleted from the graph, and therefore the number of times that we need to recompute all the possible costs from START to END
As a result, a majority of the search time is spent in `visit_condition`, `visit_node`, and `update_all_costs_before_node`. This is frustrating because it often happens when the "universe" given to the rule consists of only a handful of document ids.
By limiting the number of possible edges between two nodes from `20` to `10`, we:
1. reduce the number of possible costs from START to END
2. reduce the number of edges that will be deleted
3. make it faster to update the costs after deleting an edge
4. reduce the number of buckets that need to be computed
In terms of relevancy, I don't think we lose or gain much. We still prefer terms that are in a lower positions, with decreasing precision as we go further. The previous choice of bucketing wasn't chosen in a principled way, and neither is this one. They both "feel" right to me.
Co-authored-by: Loïc Lecrenier <loic.lecrenier@me.com>
Co-authored-by: meili-bors[bot] <89034592+meili-bors[bot]@users.noreply.github.com>
3738: Add analytics on the get documents resource r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3737
Related spec https://github.com/meilisearch/specifications/pull/234
## What does this PR do?
Add the analytics for the following routes:
- `GET` - `/indexes/:uid/documents`
- `GET` - `/indexes/:uid/documents/:doc_id`
- `POST` - `/indexes/:uid/documents/fetch`
These analytics are aggregated between two events:
- `Documents Fetched GET`
- `Documents Fetched POST`
That shares the same payload:
Property name | Description | Example |
|---------------|-------------|---------|
| `requests.total_received` | Total number of request received in this batch | 325 |
| `per_document_id` | `false` | false |
| `per_filter` | `true` if `POST /indexes/:indexUid/documents/fetch` endpoint was used with a filter in this batch, otherwise `false` | false |
| `pagination.max_limit` | Highest value given for the `limit` parameter in this batch | 60 |
| `pagination.max_offset` | Highest value given for the `offset` parameter in this batch | 1000 |
Co-authored-by: Tamo <tamo@meilisearch.com>
3759: Invalid error code when parsing filters r=dureuill a=irevoire
# Pull Request
## Related issue
Fixes https://github.com/meilisearch/meilisearch/issues/3753
## What does this PR do?
Fix the error code in case the error comes from the evaluate of the filter for the get, fetch and delete documents routes.
Co-authored-by: Tamo <tamo@meilisearch.com>
3741: Add ngram support to the highlighter r=ManyTheFish a=loiclec
This PR fixes a bug introduced by the search refactor, where ngrams were not highlighted.
The solution was to add the ngrams to the vector of `LocatedQueryTerm` that is given to the `MatchingWords` structure.
Co-authored-by: Loïc Lecrenier <loic.lecrenier@me.com>
3749: Fix back: sort error message r=ManyTheFish a=ManyTheFish
This PR reintroduces the error message modified in https://github.com/meilisearch/milli/pull/375.
However, this added double-quotes around `sort` in the message. I don't think another message contains double-quotes, so I have added a separate commit replacing the double-quotes with back-ticks, which seems more consistent with the other error messages, this last change can be reverted easily.
## Detailed changes
#### v1.2-rc0
```
The sort ranking rule must be specified in the ranking rules settings to use the sort parameter at search time.
```
#### [Reintroduce fix (previous and expected behavior)](23d1c86825)
```
You must specify where "sort" is listed in the rankingRules setting to use the sort parameter at search time
```
#### [Replace double-quotes with back-ticks (my suggestion)](4d691d071a)
```
You must specify where `sort` is listed in the rankingRules setting to use the sort parameter at search time
```
## Related
Fixes#3722
## Reviewers
- technical review: `@irevoire`
- to validate the replacement: `@macraig`
Co-authored-by: ManyTheFish <many@meilisearch.com>
3651: Use the writemap flag to reduce the memory usage r=irevoire a=Kerollmops
This draft PR is showing some stats about the memory usage of Meilisearch when [the LMDB `MDB_WRITEMAP` flag](3947014aed/libraries/liblmdb/lmdb.h (L573-L581)) is enabled and when it is not. As you can see there is a reduction of about 50% of the memory usage pick. The dataset used was [the Wikipedia one](https://www.notion.so/meilisearch/Wikipedia-8b1486e4b17547c5bda485d2d97767a0) with the first 30 000 first CSV documents without settings. This PR depends on https://github.com/meilisearch/heed/pull/168.
I just [opened a discussion](https://github.com/meilisearch/product/discussions/652) for people to understand the tradeoffs and give their feedback.
- [x] Create an experiment flag `--experimental-reduce-indexing-memory-usage`.
- [x] Add it to the config file.
- [x] Explain the tradeoff and copy/link the LMDB documentation in the help message.
- [x] Add analytics about the experimental flag.
- [x] Document that this flag cannot be used on Windows, ~~or hide it~~.
<details>
<summary>The command I used to run the tests</summary>
#### Sign the binary to be able to use Instruments / xcrun
```sh
codesign -s - -f --entitlements ~/ent.plist target/release/meilisearch
```
where `ent.plist` contains:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>com.apple.security.get-task-allow</key>
<true/>
</dict>
</plist>
```
#### Run Meilisearch in measure-mode
```sh
xcrun xctrace record --template 'Allocations' --launch -- target/release/meilisearch --max-indexing-memory 0MiB
```
#### Send the wiki dataset available on notion.so / Public
```sh
for f in 0.csv 15000.csv; do echo sending $f; xh 'localhost:7700/indexes/wiki/documents' 'content-type:text/csv' `@$f;` done
```
#### Wait for the task to finish
```sh
watch --color xh --pretty all 'localhost:7700/tasks?statuses=processing'
```
</details>
Keep in mind that I tested that with the Instruments Apple tools on an iMac 5k 2019. More benchmarks must be done, especially on the indexation speed, as the flag is told to slow down writing into databases bigger that the amount of memory.
On the left Meilisearch is running without the flag. On the right, it is running with the flag.
<p align="center">
<img align="left" width="45%" alt="Instrument showing the memory usage of Meilisearch without the MDB_WRITEMAP flag" src="https://user-images.githubusercontent.com/3610253/234299524-7607f1df-6fc1-45d3-bd3d-4f9388002857.png">
<img align="right" width="45%" alt="Instrument showing the memory usage of Meilisearch with the MDB_WRITEMAP flag" src="https://user-images.githubusercontent.com/3610253/234299534-6cc3ae58-8bd9-426c-aa79-4c78f9e88b94.png">
</p>
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
3739: fix: update `payload_too_large` error message to include human readable maximum acceptable payload size r=Kerollmops a=cymruu
# Pull Request
## Related issue
Fixes#3736
## What does this PR do?
- update `payload_too_large` error message as requested in ticket
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Filip Bachul <filipbachul@gmail.com>
3742: Compute split words derivations of terms that don't accept typos r=ManyTheFish a=loiclec
Allows looking for the split-word derivation for short words in the user's query (like `the -> "t he"` or `door -> do or`) as well as for 3grams.
Co-authored-by: Loïc Lecrenier <loic.lecrenier@me.com>
3731: Move comments above keys in config.toml r=curquiza a=jirutka
The current style is very unusual, confusing and breaks compatibility with tools for parsing config files including comments. Everyone writes comments above the items to which they refer (maybe except pythonists), so let's stick to that.
Co-authored-by: Jakub Jirutka <jakub@jirutka.cz>
3734: Update version for the next release (v1.2.0) in Cargo.toml r=curquiza a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: curquiza <curquiza@users.noreply.github.com>
3726: Fix prefix highlighting r=loiclec a=ManyTheFish
The prefix queries were not properly highlighted, this PR now highlights only the start of a word when it matched with a prefix
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Loïc Lecrenier <loic.lecrenier@me.com>
The current style is very unusual, confusing and breaks compatibility
with tools for parsing config files including comments. Everyone writes
comments above the items to which they refer (maybe except pythonists),
so let's stick to that.
3687: Allow to disable specialized tokenizations (again) r=Kerollmops a=jirutka
In PR #2773, I added the `chinese`, `hebrew`, `japanese` and `thai` feature flags to allow melisearch to be built without huge specialed tokenizations that took up 90% of the melisearch binary size. Unfortunately, due to some recent changes, this doesn't work anymore. The problem lies in excessive use of the `default` feature flag, which infects the dependency graph.
Instead of adding `default-features = false` here and there, it's easier and more future-proof to not declare `default` in `milli` and `meilisearch-types`. I've renamed it to `all-tokenizers`, which also makes it a bit clearer what it's about.
Co-authored-by: Jakub Jirutka <jakub@jirutka.cz>
In PR #2773, I added the `chinese`, `hebrew`, `japanese` and `thai`
feature flags to allow melisearch to be built without huge specialed
tokenizations that took up 90% of the melisearch binary size.
Unfortunately, due to some recent changes, this doesn't work anymore.
The problem lies in excessive use of the `default` feature flag, which
infects the dependency graph.
Instead of adding `default-features = false` here and there, it's easier
and more future-proof to not declare `default` in `milli` and
`meilisearch-types`. I've renamed it to `all-tokenizers`, which also
makes it a bit clearer what it's about.
3570: Get documents by filter r=irevoire a=dureuill
# Pull Request
## Related issue
Associated spec: https://github.com/meilisearch/specifications/pull/234
None really, this is more of an extension of #3477: since after this issue we'll be able to delete documents by filter, it makes sense to also be able to get documents by filter.
## What does this PR do?
### User standpoint
- Add a new `filter` URL parameter to `GET /indexes/{:indexUid}/documents` and a new `POST /indexes/{:indexUid}/documents/fetch` route with the same `offset, limit, fields, filter`
### Implementation standpoint
- Add a new `Index::iter_documents` method to iterate on a set of documents rather than return a vector of these documents.
- Rewrite the other `Index::*documents` methods to use the new `Index::iter_documents` method.
## Usage
<details>
<summary>
Sample request and response
</summary>
```
curl -X POST 'http://localhost:7700/indexes/index-1101/documents/fetch' -H 'Content-Type: application/json' --data-binary '{ "filter": "genres = Comedy", "limit": 3, "offset": 8000}' | jsonxf
```
```json
{
"results": [
{
"id": 326126,
"title": "Bad Exorcists",
"overview": "A trio of awkward teens intend to win a horror festival by making their own movie, but wind up getting their actress possessed in the process.",
"genres": [
"Horror",
"Comedy"
],
"poster": "https://image.tmdb.org/t/p/w500/lwd65kPbjFacAw3QSXiwSsW6cFU.jpg",
"release_date": 1425081600
},
{
"id": 326215,
"title": "Ooops! Noah is Gone...",
"overview": "It's the end of the world. A flood is coming. Luckily for Dave and his son Finny, a couple of clumsy Nestrians, an Ark has been built to save all animals. But as it turns out, Nestrians aren't allowed. Sneaking on board with the involuntary help of Hazel and her daughter Leah, two Grymps, they think they're safe. Until the curious kids fall off the Ark. Now Finny and Leah struggle to survive the flood and hungry predators and attempt to reach the top of a mountain, while Dave and Hazel must put aside their differences, turn the Ark around and save their kids. It's definitely not going to be smooth sailing.",
"genres": [
"Animation",
"Adventure",
"Comedy",
"Family"
],
"poster": "https://image.tmdb.org/t/p/w500/gEJXHgpiKh89Vwjc4XUY5CIgUdB.jpg",
"release_date": 1427328000
},
{
"id": 326241,
"title": "For Here or to Go?",
"overview": "An aspiring Indian tech entrepreneur in the Silicon Valley finds himself unexpectedly battling the bizarre American immigration system to keep his dream alive or prepare to return home forever.",
"genres": [
"Drama",
"Comedy"
],
"poster": "https://image.tmdb.org/t/p/w500/ff8WaA7ItBgl36kdT232i0d0Fnq.jpg",
"release_date": 1490918400
}
],
"offset": 8000,
"limit": 3,
"total": 9331
}
```
<img width="1348" alt="Capture d’écran 2023-03-08 à 10 09 04" src="https://user-images.githubusercontent.com/41078892/223670905-6932b79b-f9b8-4a41-b59e-be2171705b7d.png">
</details>
# Draft status
- [ ] Route naming: having one route be `GET /indexes/{:indexUid}/documents` and the other `POST /indexes/{:indexUid}/documents/fetch` is suboptimal (also, technically a breaking change for documents with `fetch` as uid?), but `POST /indexes/{:indexUid}/documents` is already used to insert documents.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
3550: Delete documents by filter r=irevoire a=dureuill
# Prototype `prototype-delete-by-filter-0`
Usage:
A new route is available under `POST /indexes/{index_uid}/documents/delete` that allows you to delete your documents by filter.
The expected payload looks like that:
```json
{
"filter": "doggo = bernese",
}
```
It'll then enqueue a task in your task queue that'll delete all the documents matching this filter once it's processed.
Here is an example of the associated details;
```json
"details": {
"deletedDocuments": 53,
"originalFilter": "\"doggo = bernese\""
}
```
----------
# Pull Request
## Related issue
Related to https://github.com/meilisearch/meilisearch/issues/3477
## What does this PR do?
### User standpoint
- Modifies the `/indexes/{:indexUid}/documents/delete-batch` route to accept either the existing array of documents ids, or a JSON object with a `filter` field representing a filter to apply. If that latter variant is used, any document matching the filter will be deleted.
### Implementation standpoint
- (processing time version) Adds a new BatchKind that is not autobatchable and that performs the delete by filter
- Reuse the `documentDeletion` task with a new `originalFilter` detail that replaces the `providedIds` detail.
## Example
<details>
<summary>Sample request, response and task result</summary>
Request:
```
curl \
-X POST 'http://localhost:7700/indexes/index-10/documents/delete-batch' \
-H 'Content-Type: application/json' \
--data-binary '{ "filter" : "mass = 600"}'
```
Response:
```
{
"taskUid": 3902,
"indexUid": "index-10",
"status": "enqueued",
"type": "documentDeletion",
"enqueuedAt": "2023-02-28T20:50:31.667502Z"
}
```
Task log:
```json
{
"uid": 3906,
"indexUid": "index-12",
"status": "succeeded",
"type": "documentDeletion",
"canceledBy": null,
"details": {
"deletedDocuments": 3,
"originalFilter": "\"mass = 600\""
},
"error": null,
"duration": "PT0.001819S",
"enqueuedAt": "2023-03-07T08:57:20.11387Z",
"startedAt": "2023-03-07T08:57:20.115895Z",
"finishedAt": "2023-03-07T08:57:20.117714Z"
}
```
</details>
## Draft status
- [ ] Error handling
- [ ] Analytics
- [ ] Do we want to reuse the `delete-batch` route in this way, or create a new route instead?
- [ ] Should the filter be applied at request time or when the deletion task is processed?
- The first commit in this PR applies the filter at request time, meaning that even if a document is modified in a way that no longer matches the filter in a later update, it will be deleted as long as the deletion task is processed after that update.
- The other commits in this PR apply the filter only when the asynchronous deletion task is processed, meaning that documents that match the filter at processing time are deleted even if they didn't match the filter at request time.
- [ ] If keeping the filter at request time, find a more elegant way to recover the user document ids from the internal document ids. The current way implemented in the first commit of this PR involves getting all the documents matching the filter, looking for the value of their primary key, and turning it into a string by copy-pasting routines found in milli...
- [ ] Security consideration, if any
- [ ] Fix the tests (but waiting until product questions are resolved)
- [ ] Add delete by filter specific tests
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
3639: Add a dedicated error variant for planned failures in index scheduler tests r=Kerollmops a=Sufflope
# Pull Request
## Related issue
Fixes#3086
## What does this PR do?
- Add a dedicated test variant in test cfg to avoid reusing a misleading existing error
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Jean-Sébastien Bour <jean-sebastien@bour.name>
3693: Implement the auto deletion of tasks r=dureuill a=irevoire
Fixes https://github.com/meilisearch/meilisearch/issues/3622
This PR should be the definite fix for #3622.
It adds a limit (1M) to the maximum number of tasks the task queue can hold.
Once the task queue reaches this limit (1M of tasks are in the task queue, whatever their status is), meilisearch will schedule a task deletion that tries to delete the oldest 100k tasks.
If meilisearch can't delete 100k tasks because some of them are not yet finished, it will delete as many tasks as possible.
Once the limit is reached, you're still able to register new tasks. The engine will only stop you from adding new tasks once [the other hard limit](https://github.com/meilisearch/meilisearch/pull/3659) of 10GiB of tasks is reached (that's between 5M and 15M of tasks depending on your workflow).
-------
Technically;
- We only try to schedule our task deletion when calling the tick function but before creating a new batch. This means we never enqueue a task we're not going to process ~right away.
- If our task deletion doesn't delete anything, we don't enqueue it and log a warn the user that the engine is not working properly
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3542: Refactor of the search algorithms r=dureuill a=loiclec
This PR refactors a large part of the search logic (related to https://github.com/meilisearch/meilisearch/issues/3547)
- The "query tree" is replaced by a "query graph", which describes the different ways in which the search query can be interpreted and precomputes the word derivations for each query term. Example:
<img width="1162" alt="Screenshot 2023-02-27 at 10 26 50" src="https://user-images.githubusercontent.com/6040237/221525270-87917cc0-60d1-473f-847f-2c5a7de9e370.png">
- The control flow between the ~criterions~ ranking rules is managed in a single place instead of being independently implemented by each ranking rule.
- The set of document candidates is determined greedily from the beginning. It is often referred as the "universe" in the code.
- The ranking rules `proximity`, `attribute`, `typo`, and (maybe) `exactness` are or will be implemented using a K-shortest path graph algorithm. This minimises the number of database and bitmap operations we need to do to compute each ranking rule bucket. It also simplifies the code a lot since a lot of ranking rules will share a large part of their implementation.
- Pointers to database values are stored in a cache to avoid searching in the LMDB databases needlessly.
- The result of some roaring bitmap operations are also stored in a cache, although we'll need to measure the memory pressure this puts on the system and maybe deactivate this cache later on.
- Search requests can be visually logged and debugged in tests.
TODO:
- [ ] Reintroduce search benchmarks
- [x] Implement `disableOnWords` and `disableOnAttributes` settings of typo tolerance
- [x] Implement "exhaustive number of hits
- [x] Implement `attribute` ranking rule
- [x] Indexing changes: split into `word_fid_docids` and `word_position_docids` (with bucketed position)
- [x] Ranking rule implementations
- [ ] Implement `exactness` ranking rule
- [x] Initial implementation
- [ ] Correct implementation when followed by `Words`
- [ ] Implement `geosort` ranking rule
- [ ] Add tests
- [x] Typo tolerance `disableOnWords`/`disableOnAttributes`
- [ ] Geosort
- [x] Exactness
- [ ] Attribute/Position
- [ ] Interactions between ranking rules:
- [x] Typo/Proximity/Attribute not preceded by Words
- [x] Exactness not preceded by Words
- [x] Exactness -> Words (+ check universe correctness)
- [x] Exactness -> Typo, etc.
- [ ] Sort -> Words (performance tests)
- [ ] Attribute/Position -> Typo
- [ ] Attribute/Position -> Proximity
- [x] Typo -> Exactness
- [x] Typo -> Proximity
- [x] Proximity -> Typo
- [x] Words
- [x] Typo
- [x] Proximity
- [x] Sort
- [x] Ngrams
- [x] Split words
- [x] Ngram + Split Words
- [x] Term matching strategy
- [x] Distinct attribute
- [x] Phrase Search
- [x] Placeholder search
- [x] Highlighter
- [x] Limit the number of word derivations in a search query
- [x] Compute the initial universe correctly according to the terms matching strategy
- [x] Implement placeholder search
- [x] Get the list of ranking rules from the settings
- [x] Implement `distinct`
- [x] Determine what to do when one of `attribute`, `proximity`, `typo`, or `exactness` is placed before `words`
- [x] Make sure the correct number of allowed typos is used for each word, including the prefix one
- [x] Make sure stop words are treated correctly (e.g. correct position in query graph), including in phrases
- [x] Support phrases correctly
- [x] Support synonyms
- [x] Support split words
- [x] Support combination of ngram + split-words (e.g. `whiteh orse` -> `"white horse"`)
- [x] Implement `typo` ranking rule
- [x] Implement `sort` ranking rule
- [x] Use existing `Search` interface to use the new search algorithms
- [x] Remove old code
Co-authored-by: Loïc Lecrenier <loic.lecrenier@me.com>
Conflicts | resolution
----------|-----------
Cargo.lock | added mimalloc
Cargo.toml | took origin/main version
milli/src/search/criteria/exactness.rs | deleted after checking it was only clippy changes
milli/src/search/query_tree.rs | deleted after checking it was only clippy changes
3702: Update charabia v0.7.2 r=curquiza a=ManyTheFish
fixes#3701fixes#3689fixes#3285
3710: Updated messages pointing to the docs website r=curquiza a=roy9495
# Pull Request
Fixes partially #3668
## What does this PR do?
- ...Any messages referencing this docs site https://docs.meilisearch.com has been changed to this docs site https://meilisearch.com/docs .
Thanks.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: TATHAGATA ROY <98920199+roy9495@users.noreply.github.com>
3718: Fix broken README links r=curquiza a=Kerollmops
This PR fixes#3708 by changing the link to the new SDKs and API Reference pages. I would like to thank `@Tommy-42,` who also found the issue.
Co-authored-by: Clément Renault <clement@meilisearch.com>
3709: Add SDKs test in a CI r=Kerollmops a=curquiza
Add a CI running every week to run the `nightly` docker image of Meilisearch with the most "strategic" SDKs (most used, well tested, strongly typed SDK)
- meilisearch-js
- instant-meilisearch
- meilisearch-php
- meilisearch-python
- meilisearch-go
- meilisearch-ruby
- meilisearch-rust
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
3571: Introduce two filters to select documents with `null` and empty fields r=irevoire a=Kerollmops
# Pull Request
## Related issue
This PR implements the `X IS NULL`, `X IS NOT NULL`, `X IS EMPTY`, `X IS NOT EMPTY` filters that [this comment](https://github.com/meilisearch/product/discussions/539#discussioncomment-5115884) is describing in a very detailed manner.
## What does this PR do?
### `IS NULL` and `IS NOT NULL`
This PR will be exposed as a prototype for now. Below is the copy/pasted version of a spec that defines this filter.
- `IS NULL` matches fields that `EXISTS` AND `= IS NULL`
- `IS NOT NULL` matches fields that `NOT EXISTS` OR `!= IS NULL`
1. `{"name": "A", "price": null}`
2. `{"name": "A", "price": 10}`
3. `{"name": "A"}`
`price IS NULL` would match 1
`price IS NOT NULL` or `NOT price IS NULL` would match 2,3
`price EXISTS` would match 1, 2
`price NOT EXISTS` or `NOT price EXISTS` would match 3
common query : `(price EXISTS) AND (price IS NOT NULL)` would match 2
### `IS EMPTY` and `IS NOT EMPTY`
- `IS EMPTY` matches Array `[]`, Object `{}`, or String `""` fields that `EXISTS` and are empty
- `IS NOT EMPTY` matches fields that `NOT EXISTS` OR are not empty.
1. `{"name": "A", "tags": null}`
2. `{"name": "A", "tags": [null]}`
3. `{"name": "A", "tags": []}`
4. `{"name": "A", "tags": ["hello","world"]}`
5. `{"name": "A", "tags": [""]}`
6. `{"name": "A"}`
7. `{"name": "A", "tags": {}}`
8. `{"name": "A", "tags": {"t1":"v1"}}`
9. `{"name": "A", "tags": {"t1":""}}`
10. `{"name": "A", "tags": ""}`
`tags IS EMPTY` would match 3,7,10
`tags IS NOT EMPTY` or `NOT tags IS EMPTY` would match 1,2,4,5,6,8,9
`tags IS NULL` would match 1
`tags IS NOT NULL` or `NOT tags IS NULL` would match 2,3,4,5,6,7,8,9,10
`tags EXISTS` would match 1,2,3,4,5,7,8,9,10
`tags NOT EXISTS` or `NOT tags EXISTS` would match 6
common query : `(tags EXISTS) AND (tags IS NOT NULL) AND (tags IS NOT EMPTY)` would match 2,4,5,8,9
## What should the reviewer do?
- Check that I tested the filters
- Check that I deleted the ids of the documents when deleting documents
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
3464: Remove CLI changes for clippy r=curquiza a=dureuill
# Pull Request
## Related issue
Reverts #3434, which was linked to https://github.com/rust-lang/rust-clippy/issues/10087, as putting the lint in the pedantic group [is being uplifted to Rust 1.67.1](https://github.com/rust-lang/rust/pull/107743#issue-1573438821) (my thanks to everyone involved in this work 🎉).
## Motivation
- Using "standard issue" clippy in the CI spares our contributors and us from knowing/remembering to add the lint when running clippy locally
- In particular, spares us from configuring tools like rust-analyzer to take the lint into account.
- Should this lint come back in another form in the future, we won't blindly ignore it, and we will be able to reassess it, which will be good wrt writing idiomatic Rust. By the time this occurs, lints might be configurable through `clippy.toml` too, which would make disabling one globally much more convenient if needs be.
## Note
We should wait for the release of Rust 1.67.1 and its propagation to our CI before merging this. The PR won't pass CI before this.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3696: Remove the unused snapshot files r=dureuill a=irevoire
While « reverting by hand » the PR about the auto batching of the addition&deletion of documents, we forgot to remove the associated snapshot files.
Here is the command I used to generate this PR: `cargo insta test --delete-unreferenced-snapshots`
Co-authored-by: Tamo <tamo@meilisearch.com>
3566: Improve docker cache r=curquiza a=inductor
# Pull Request
## Related issue
Fixes #<issue_number>
## What does this PR do?
- Use `--mount=type=cache` and GHA build cache for faster build
- `=> => transferring context: 75.37MB` to `=> => transferring context: 19.21MB` with `.dockerignore`
## PR checklist
Please check if your PR fulfills the following requirements:
- [ ] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: inductor <kela@inductor.me>
Co-authored-by: Clémentine Urquizar - curqui <clementine@meilisearch.com>
3694: Remove Uffizzi because not used by the team r=Kerollmops a=curquiza
After discussion with the team, we don't really use Uffizzi and even had issues with it recently: the preview build failing randomly leading to unwanted GitHub notifications + issue to reach the container
<img width="628" alt="Capture d’écran 2023-04-25 à 11 55 39" src="https://user-images.githubusercontent.com/20380692/234298586-ef9cff85-ded8-4ec5-ba13-bb7a24d476b3.png">
Thanks for the involvement of Uffizzi team anyway, the tool is just not adapted to our team 😊
Co-authored-by: curquiza <clementine@meilisearch.com>
3661: Bump the dependencies r=Kerollmops a=Kerollmops
This PR bumps all the dependencies of Meilisearch and the sub-crates. I first did a `cargo upgrade --compatible`, fixed the tests, continued with a `cargo upgrade --incompatible`, and finally fixed the compilation issues.
I wasn't able to bump _rustls_ to _0.21.0_ (_actix-web_ is using _tokio-tls 0.23.4_, which uses the _0.20.8_) and neither _vergen_, which changed everything without any guide, I didn't find a way to declare that with the version 8.1.1.
bc25f378e8/meilisearch/build.rs (L4-L9)Fixes#3285
Co-authored-by: Kerollmops <clement@meilisearch.com>
3688: Following release v1.1.1: bring back changes into `main` r=curquiza a=curquiza
`@meilisearch/engine-team` ensure the changes we bring to `main` are the ones you want
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: bors[bot] <26634292+bors[bot]@users.noreply.github.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: dureuill <dureuill@users.noreply.github.com>
3674: Bump h2 from 0.3.15 to 0.3.17 r=Kerollmops a=dependabot[bot]
Bumps [h2](https://github.com/hyperium/h2) from 0.3.15 to 0.3.17.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/hyperium/h2/releases">h2's releases</a>.</em></p>
<blockquote>
<h2>v0.3.17</h2>
<h2>What's Changed</h2>
<ul>
<li>Add <code>Error::is_library()</code> method to check if the originated inside <code>h2</code>.</li>
<li>Add <code>max_pending_accept_reset_streams(usize)</code> option to client and server
builders.</li>
<li>Fix theoretical memory growth when receiving too many HEADERS and then
RST_STREAM frames faster than an application can accept them off the queue.
(CVE-2023-26964)</li>
</ul>
<h2>v0.3.16</h2>
<h2>What's Changed</h2>
<ul>
<li>Set <code>Protocol</code> extension on requests when received Extended CONNECT requests.</li>
<li>Remove <code>B: Unpin + 'static</code> bound requiremented of bufs</li>
<li>Fix releasing of frames when stream is finished, reducing memory usage.</li>
<li>Fix panic when trying to send data and connection window is available, but stream window is not.</li>
<li>Fix spurious wakeups when stream capacity is not available.</li>
</ul>
<h2>New Contributors</h2>
<ul>
<li><a href="https://github.com/vi"><code>`@vi</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/646">hyperium/h2#646</a></li>
<li><a href="https://github.com/silence-coding"><code>`@silence-coding</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/651">hyperium/h2#651</a></li>
<li><a href="https://github.com/gtsiam"><code>`@gtsiam</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/649">hyperium/h2#649</a></li>
<li><a href="https://github.com/howardjohn"><code>`@howardjohn</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/658">hyperium/h2#658</a></li>
<li><a href="https://github.com/cloneable"><code>`@cloneable</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/655">hyperium/h2#655</a></li>
<li><a href="https://github.com/aftersnow"><code>`@aftersnow</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/657">hyperium/h2#657</a></li>
<li><a href="https://github.com/vadim-eg"><code>`@vadim-eg</code></a>` made their first contribution in <a href="https://redirect.github.com/hyperium/h2/pull/661">hyperium/h2#661</a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/hyperium/h2/blob/master/CHANGELOG.md">h2's changelog</a>.</em></p>
<blockquote>
<h1>0.3.17 (April 13, 2023)</h1>
<ul>
<li>Add <code>Error::is_library()</code> method to check if the originated inside <code>h2</code>.</li>
<li>Add <code>max_pending_accept_reset_streams(usize)</code> option to client and server
builders.</li>
<li>Fix theoretical memory growth when receiving too many HEADERS and then
RST_STREAM frames faster than an application can accept them off the queue.
(CVE-2023-26964)</li>
</ul>
<h1>0.3.16 (February 27, 2023)</h1>
<ul>
<li>Set <code>Protocol</code> extension on requests when received Extended CONNECT requests.</li>
<li>Remove <code>B: Unpin + 'static</code> bound requiremented of bufs</li>
<li>Fix releasing of frames when stream is finished, reducing memory usage.</li>
<li>Fix panic when trying to send data and connection window is available, but stream window is not.</li>
<li>Fix spurious wakeups when stream capacity is not available.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="af4bcacf6d"><code>af4bcac</code></a> v0.3.17</li>
<li><a href="d3f37e9fba"><code>d3f37e9</code></a> feat: add <code>max_pending_accept_reset_streams(n)</code> options</li>
<li><a href="5bc8e72e5f"><code>5bc8e72</code></a> fix: limit the amount of pending-accept reset streams</li>
<li><a href="8088ca658d"><code>8088ca6</code></a> feat: add Error::is_library method</li>
<li><a href="481c31d528"><code>481c31d</code></a> chore: Use Cargo metadata for the MSRV build job</li>
<li><a href="d3d50ef812"><code>d3d50ef</code></a> chore: Replace unmaintained/outdated GitHub Actions</li>
<li><a href="45b9bccdfc"><code>45b9bcc</code></a> chore: set rust-version in Cargo.toml (<a href="https://redirect.github.com/hyperium/h2/issues/664">#664</a>)</li>
<li><a href="b9dcd39915"><code>b9dcd39</code></a> v0.3.16</li>
<li><a href="96caf4fca3"><code>96caf4f</code></a> Add a message for EOF-related broken pipe errors (<a href="https://redirect.github.com/hyperium/h2/issues/615">#615</a>)</li>
<li><a href="732319039f"><code>7323190</code></a> Avoid spurious wakeups when stream capacity is not available (<a href="https://redirect.github.com/hyperium/h2/issues/661">#661</a>)</li>
<li>Additional commits viewable in <a href="https://github.com/hyperium/h2/compare/v0.3.15...v0.3.17">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/meilisearch/meilisearch/network/alerts).
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
3673: Handle the task queue being full r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes a remaining issue with #3659 where it was not always possible to send tasks back even after deleting some tasks when prompted.
## Tests
- see integration test
- also manually tested with a 1MiB task queue. Was not possible to become unblocked before this PR, is now possible.
## What does this PR do?
- Use the `non_free_pages_size` method to compute the space occupied by the task db instead of the `real_disk_size` which is not always affected by task deletion.
- Expand the test so that it adds a task after the deletion. The test now fails before this PR and succeeds after this PR.
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
3672: Update version for the next release (v1.1.1) in Cargo.toml r=dureuill a=meili-bot
⚠️ This PR is automatically generated. Check the new version is the expected one and Cargo.lock has been updated before merging.
Co-authored-by: dureuill <dureuill@users.noreply.github.com>
3659: stops receiving tasks once the task queue is full r=Kerollmops a=irevoire
Give 20GiB to the task queue + once 50% of the task queue is used, it blocks itself and only receives task deletion requests to ensure we never get in a state where we can’t do anything.
Also, create a new error message when we reach this case:
```
Meilisearch cannot receive write operations because the size limit of the tasks database has been reached. Please delete tasks to continue performing write operations.
```
Co-authored-by: Tamo <tamo@meilisearch.com>
3666: Update README to reference new docs website r=curquiza a=guimachiavelli
With the launch of the new website, we need to update the README so it references the correct URLs.
Two minor details:
- we have removed the contact page from the documentation (it had the same links present in this readme and on the community section of the landing page)
- we have recently separated filtering and faceted search into two separate articles
Co-authored-by: gui machiavelli <hey@guimachiavelli.com>
3667: Disable autobatching of additions and deletions r=irevoire a=dureuill
# Pull Request
## Related issue
Fixes#3664
## What does this PR do?
- Modifies the autobatcher to not batch document additions and deletions, as a workaround to the DB corruption in #3664
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
With the launch of the new website, we need to update the README so it references the correct URLs.
Two minor details:
- we have removed the contact page from the documentation (it had the same links present in this readme and on the community section of the landing page)
- we have recently separated filtering and faceted search into two separate articles
3647: Improve the health route by ensuring lmdb is not down r=irevoire a=irevoire
Fixes#3644
In this PR, I try to make a small read on the `AuthController` and `IndexScheduler` databases.
The idea is not to validate that everything works but just to avoid the bug we had last time when lmdb was stuck forever.
In order to get access to the `AuthController` without going through the extractor, I need to wrap it in the `Data` type from `actix-web`.
And to do that, I had to patch our extractor so it works with the `Data` type as well.
Co-authored-by: Tamo <tamo@meilisearch.com>
3638: filter errors - `geo(x,y,z)` and `geoDistance(x,y,z)` r=irevoire a=cymruu
# Pull Request
## Related issue
Fixes#3006
## What does this PR do?
- fixes the display function of `ParseError::ReservedGeo`. The previous display string was missing back ticks around available filters.
- makes the filter-parser parse `_geo(x,y,z)` and `geoDistance(x,y,z)` filters. Both parsing functions will throw an error if the filter was used.
- removes `FilterError::ReservedGeo` and `FilterError::Reserved` error variants since they are now thrown by the filter-parser.
I ran `cargo test --package milli -- --test-threads 1` and the tests passed.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Filip Bachul <filipbachul@gmail.com>
Co-authored-by: filip <filipbachul@gmail.com>
3631: sort errors - `_geo(x,y)` and `_geoDistance(x,y)` return `ReservedKeyword` r=irevoire a=cymruu
# Pull Request
## Related issue
Fix part of #3006 (sort errors)
## What does this PR do?
- made meilisearch return `ReservedKeyword` when sorting by `_geo(x,y)` or `_geoDistance(x,y)`
Screenshot:
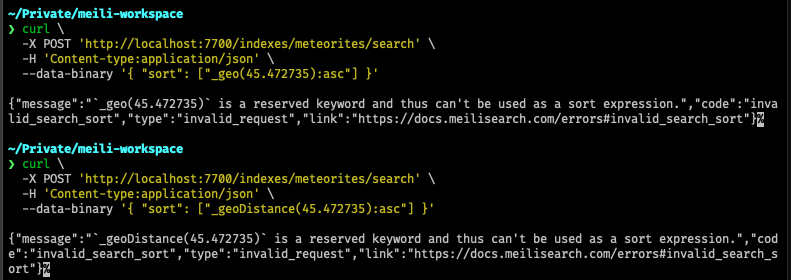
I ran `cargo test --package milli -- --test-threads 1` and the tests passed.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Filip Bachul <filipbachul@gmail.com>
3636: Add a newline after the meilisearch version in the issue template r=curquiza a=bidoubiwa
# Pull Request
## What does this PR do?
Just a small change that makes it easier to remove the version example and adds consistency with the other examples in its positioning.
Co-authored-by: cvermand <33010418+bidoubiwa@users.noreply.github.com>
3633: Bump Swatinem/rust-cache from 2.2.0 to 2.2.1 r=curquiza a=dependabot[bot]
Bumps [Swatinem/rust-cache](https://github.com/Swatinem/rust-cache) from 2.2.0 to 2.2.1.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/releases">Swatinem/rust-cache's releases</a>.</em></p>
<blockquote>
<h2>v2.2.1</h2>
<ul>
<li>Update <code>`@actions/cache</code>` dependency to fix usage of <code>zstd</code> compression.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/blob/master/CHANGELOG.md">Swatinem/rust-cache's changelog</a>.</em></p>
<blockquote>
<h2>2.2.1</h2>
<ul>
<li>Update <code>`@actions/cache</code>` dependency to fix usage of <code>zstd</code> compression.</li>
</ul>
<h2>2.2.0</h2>
<ul>
<li>Add new <code>save-if</code> option to always restore, but only conditionally save the cache.</li>
</ul>
<h2>2.1.0</h2>
<ul>
<li>Only hash <code>Cargo.{lock,toml}</code> files in the configured workspace directories.</li>
</ul>
<h2>2.0.2</h2>
<ul>
<li>Avoid calling <code>cargo metadata</code> on pre-cleanup.</li>
<li>Added <code>prefix-key</code>, <code>cache-directories</code> and <code>cache-targets</code> options.</li>
</ul>
<h2>2.0.1</h2>
<ul>
<li>Primarily just updating dependencies to fix GitHub deprecation notices.</li>
</ul>
<h2>2.0.0</h2>
<ul>
<li>The action code was refactored to allow for caching multiple workspaces and
different <code>target</code> directory layouts.</li>
<li>The <code>working-directory</code> and <code>target-dir</code> input options were replaced by a
single <code>workspaces</code> option that has the form of <code>$workspace -> $target</code>.</li>
<li>Support for considering <code>env-vars</code> as part of the cache key.</li>
<li>The <code>sharedKey</code> input option was renamed to <code>shared-key</code> for consistency.</li>
</ul>
<h2>1.4.0</h2>
<ul>
<li>Clean both <code>debug</code> and <code>release</code> target directories.</li>
</ul>
<h2>1.3.0</h2>
<ul>
<li>Use Rust toolchain file as additional cache key.</li>
<li>Allow for a configurable target-dir.</li>
</ul>
<h2>1.2.0</h2>
<ul>
<li>Cache <code>~/.cargo/bin</code>.</li>
<li>Support for custom <code>$CARGO_HOME</code>.</li>
<li>Add a <code>cache-hit</code> output.</li>
<li>Add a new <code>sharedKey</code> option that overrides the automatic job-name based key.</li>
</ul>
<h2>1.1.0</h2>
<ul>
<li>Add a new <code>working-directory</code> input.</li>
<li>Support caching git dependencies.</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="6fd3edff69"><code>6fd3edf</code></a> 2.2.1</li>
<li><a href="a1c019f71a"><code>a1c019f</code></a> update dependencies and rebuild</li>
<li><a href="664ce0090f"><code>664ce00</code></a> chore: Create check-dist.yml (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/96">#96</a>)</li>
<li>See full diff in <a href="https://github.com/Swatinem/rust-cache/compare/v2.2.0...v2.2.1">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
3623: Update mini-dashboard to version v0.2.7 r=curquiza a=bidoubiwa
## Changes
* Retrieve the API Key from the url parameters (#416) `@qdequele`
## 🐛 Bug Fixes
* Fix show more button not displaying all fields (#419) `@bidoubiwa`
Thanks again to `@bidoubiwa,` and `@qdequele!` 🎉
Co-authored-by: Charlotte Vermandel <charlottevermandel@gmail.com>
3624: Reduce the time to import a dump r=irevoire a=irevoire
When importing a dump, this PR does multiple things;
- Stops committing the changes between each task import
- Stop deserializing + serializing every bitmap for every task
Pros:
Importing 1M tasks in a dump went from 3m36 on my computer to 6s
Cons: We use slightly more memory, but since we’re using roaring bitmaps, that really shouldn’t be noticeable.
Fixes#3620
Co-authored-by: Tamo <tamo@meilisearch.com>
3621: Fix facet normalization r=Kerollmops a=ManyTheFish
# Pull Request
Make sure the facet normalization is the same between indexing and search.
## Related issue
Fixes#3599
Co-authored-by: ManyTheFish <many@meilisearch.com>
3608: In a settings update, check to see if the primary key actually changes before erroring out r=irevoire a=GregoryConrad
Previously, if the primary key was set and a Settings update contained a primary key, an error would be returned.
However, this error is not needed if the new PK == the current PK. This PR just checks to see if the PK actually changes before raising an error.
I came across this slight hiccup in https://github.com/GregoryConrad/mimir/issues/156#issuecomment-1484128654
Co-authored-by: Gregory Conrad <gregorysconrad@gmail.com>
3617: update the geoBoundingBox feature r=dureuill a=irevoire
Closing #3616
Implementing this change in the spec: 38a715c072
Now instead of using the (top_left, bottom_right) corners of the bounding box, it’s using the (top_right, bottom_left) corners.
Co-authored-by: Tamo <tamo@meilisearch.com>
Previously, if the primary key was set and a Settings update contained
a primary key, an error would be returned.
However, this error is not needed if the new PK == the current PK.
This commit just checks to see if the PK actually changes
before raising an error.
3597: ensure that the task queue is correctly imported r=irevoire a=irevoire
## Related issue
Fixes#3596
I updated all the dump's integration tests to ensure that we're effectively able to query the tasks
Co-authored-by: Tamo <tamo@meilisearch.com>
3576: Add boolean support for csv documents r=irevoire a=irevoire
Fixes https://github.com/meilisearch/meilisearch/issues/3572
## What does this PR do?
Add support for the boolean types in csv documents.
The type definition is `boolean` and the possible values are
- `true` for true
- `false` for false
- ` ` for null
Here is an example:
```csv
#id,cute:boolean
0,true
1,false
2,
```
Co-authored-by: Tamo <tamo@meilisearch.com>
3587: Enable cache again in test suite CI r=curquiza a=curquiza
Following the change in this PR introduced in v1.1: https://github.com/meilisearch/meilisearch/pull/3422
The cache was removed due to failures (lack of space). Now the binary is smaller (from 250Mb to 50Mb) we want to try to enable the cache again.
Indeed, without the cache step, the CIs are wayyyy slower (45min instead of 20-30min).
For later: Rust 1.68 introduced a new way to fetch crates. Updating the rust version might also help in the future!
Co-authored-by: curquiza <clementine@meilisearch.com>
3568: CI: Fix `publish-aarch64` job that still uses ubuntu-18.04 r=Kerollmops a=curquiza
Fixes#3563
Main change
- add the usage of the `ubuntu-18.04` container instead of the native `ubuntu-18.04` of GitHub actions: I had to install docker in the container.
Small additional changes
- remove useless `fail-fast` and unused/irrelevant matrix inputs (`build`, `linker`, `os`, `use-cross`...)
- Remove useless step in job
Proof of work with this CI triggered on this current branch: https://github.com/meilisearch/meilisearch/actions/runs/4366233882
3569: Enhance Japanese language detection r=dureuill a=ManyTheFish
# Pull Request
This PR is a prototype and can be tested by downloading [the dedicated docker image](https://hub.docker.com/layers/getmeili/meilisearch/prototype-better-language-detection-0/images/sha256-a12847de00e21a71ab797879fd09777dadcb0881f65b5f810e7d1ed434d116ef?context=explore):
```bash
$ docker pull getmeili/meilisearch:prototype-better-language-detection-0
```
## Context
Some Languages are harder to detect than others, this miss-detection leads to bad tokenization making some words or even documents completely unsearchable. Japanese is the main Language affected and can be detected as Chinese which has a completely different way of tokenization.
A [first iteration has been implemented for v1.1.0](https://github.com/meilisearch/meilisearch/pull/3347) but is an insufficient enhancement to make Japanese work. This first implementation was detecting the Language during the indexing to avoid bad detections during the search.
Unfortunately, some documents (shorter ones) can be wrongly detected as Chinese running bad tokenization for these documents and making possible the detection of Chinese during the search because it has been detected during the indexing.
For instance, a Japanese document `{"id": 1, "name": "東京スカパラダイスオーケストラ"}` is detected as Japanese during indexing, during the search the query `東京` will be detected as Japanese because only Japanese documents have been detected during indexing despite the fact that v1.0.2 would detect it as Chinese.
However if in the dataset there is at least one document containing a field with only Kanjis like:
_A document with only 1 field containing only Kanjis:_
```json
{
"id":4,
"name": "東京特許許可局"
}
```
_A document with 1 field containing only Kanjis and 1 field containing several Japanese characters:_
```json
{
"id":105,
"name": "東京特許許可局",
"desc": "日経平均株価は26日 に約8カ月ぶりに2万4000円の心理的な節目を上回った。株高を支える材料のひとつは、自民党総裁選で3選を決めた安倍晋三首相の経済政策への期待だ。恩恵が見込まれるとされる人材サービスや建設株の一角が買われている。ただ思惑が先行して資金が集まっている面 は否めない。実際に政策効果を取り込む企業はどこか、なお未知数だ。"
}
```
Then, in both cases, the field `name` will be detected as Chinese during indexing allowing the search to detect Chinese in queries. Therefore, the query `東京` will be detected as Chinese and only the two last documents will be retrieved by Meilisearch.
## Technical Approach
The current PR partially fixes these issues by:
1) Adding a check over potential miss-detections and rerunning the extraction of the document forcing the tokenization over the main Languages detected in it.
> 1) run a first extraction allowing the tokenizer to detect any Language in any Script
> 2) generate a distribution of tokens by Script and Languages (`script_language`)
> 3) if for a Script we have a token distribution of one of the Language that is under the threshold, then we rerun the extraction forbidding the tokenizer to detect the marginal Languages
> 4) the tokenizer will fall back on the other available Languages to tokenize the text. For example, if the Chinese were marginally detected compared to the Japanese on the CJ script, then the second extraction will force Japanese tokenization for CJ text in the document. however, the text on another script like Latin will not be impacted by this restriction.
2) Adding a filtering threshold during the search over Languages that have been marginally detected in documents
## Limits
This PR introduces 2 arbitrary thresholds:
1) during the indexing, a Language is considered miss-detected if the number of detected tokens of this Language is under 10% of the tokens detected in the same Script (Japanese and Chinese are 2 different Languages sharing the "same" script "CJK").
2) during the search, a Language is considered marginal if less than 5% of documents are detected as this Language.
This PR only partially fixes these issues:
- ✅ the query `東京` now find Japanese documents if less than 5% of documents are detected as Chinese.
- ✅ the document with the id `105` containing the Japanese field `desc` but the miss-detected field `name` is now completely detected and tokenized as Japanese and is found with the query `東京`.
- ❌ the document with the id `4` no longer breaks the search Language detection but continues to be detected as a Chinese document and can't be found during the search.
## Related issue
Fixes#3565
## Possible future enhancements
- Change or contribute to the Library used to detect the Language
- the related issue on Whatlang: https://github.com/greyblake/whatlang-rs/issues/122
Co-authored-by: curquiza <clementine@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Many the fish <many@meilisearch.com>
3577: Avoid fetching an LMDB value with an empty string r=ManyTheFish a=Kerollmops
# Pull Request
## Related issue
Fixes#3574
## What does this PR do?
This PR fixes a bug where an empty key fetches an entry in the database. LMDB throws an error if an empty or too-long key is used to fetch an entry. This empty string seems to have been generated by the Charabia tokenizer.
Co-authored-by: Clément Renault <clement@meilisearch.com>
3567: Clean CI file names r=curquiza a=curquiza
Make the CI names more consistent to ease the Gillian's onboarding 😇
No impact for the users or the developers of the team
Co-authored-by: curquiza <clementine@meilisearch.com>
Add a new job to the Rust workflow to run 'cargo build' and 'cargo
test' (on the cron schedule only) with the '--all-features' flag.
This will execute across all three environments: Linux, macOS,
Windows.
Autoformat the Rust workflow file via the Red Hat YAML extension for
Visual Studio Code:
https://marketplace.visualstudio.com/items?itemName=redhat.vscode-yaml
This straightens out whitespace and string quoting for safer parsing.
Fixes#3506.
about: ⚠️ Should only be used by the internal Meili team ⚠️
title: ''
labels: 'impacts docs, impacts integrations'
assignees: ''
---
Related product team resources: [PRD]() (_internal only_)
## Usage
<!---Link to the public part of the PRD, or to the related product discussion for experimental features-->
TBD
## TODO
<!---If necessary, create a list with technical/product steps-->
### Are you modifying a database?
- [ ] If not, add the `no db change` label to your PR, and you're good to merge.
- [ ] If yes, add the `db change` label to your PR. You'll receive a message explaining you what to do.
### Reminders when modifying the API
- [ ] Update the openAPI file with utoipa:
- [ ] If a new module has been introduced, create a new structure deriving [the OpenAPI proc-macro](https://docs.rs/utoipa/latest/utoipa/derive.OpenApi.html) and nest it in the main [openAPI structure](https://github.com/meilisearch/meilisearch/blob/f2185438eed60fa32d25b15480c5ee064f6fba4a/crates/meilisearch/src/routes/mod.rs#L64-L78).
- [ ] If a new route has been introduced, add the [path decorator](https://docs.rs/utoipa/latest/utoipa/attr.path.html) to it and add the route at the top of the file in its openAPI structure.
- [ ] If a structure which is deserialized or serialized in the API has been introduced or modified, it must derive the [`schema`](https://docs.rs/utoipa/latest/utoipa/macro.schema.html) or the [`IntoParams`](https://docs.rs/utoipa/latest/utoipa/derive.IntoParams.html) proc-macro.
If it's a **new** structure you must also add it to the big list of structures [in the main `OpenApi` structure](https://github.com/meilisearch/meilisearch/blob/f2185438eed60fa32d25b15480c5ee064f6fba4a/crates/meilisearch/src/routes/mod.rs#L88).
- [ ] Once everything is done, start Meilisearch with the swagger flag: `cargo run --features swagger`, open `http://localhost:7700/scalar` on your browser, and ensure everything works as expected.
- For more info, refer to [this presentation](https://pitch.com/v/generating-the-openapi-file-jrn3nh).
### Reminders when modifying the Setting API
<!--- Special steps to remind when adding a new index setting -->
- [ ] Ensure the new setting route is at least tested by the [`test_setting_routes` macro](https://github.com/meilisearch/meilisearch/blob/5204c0b60b384cbc79621b6b2176fca086069e8e/meilisearch/tests/settings/get_settings.rs#L276)
- [ ] Ensure Analytics are fully implemented
- [ ]`/settings/my-new-setting` configurated in the [`make_setting_routes` macro](https://github.com/meilisearch/meilisearch/blob/5204c0b60b384cbc79621b6b2176fca086069e8e/meilisearch/src/routes/indexes/settings.rs#L141-L165)
- [ ] global `/settings` route configurated in the [`update_all` function](https://github.com/meilisearch/meilisearch/blob/5204c0b60b384cbc79621b6b2176fca086069e8e/meilisearch/src/routes/indexes/settings.rs#L655-L751)
- [ ] Ensure the dump serializing is consistent with the `/settings` route serializing, e.g., enums case can be different (`camelCase` in route and `PascalCase` in the dump)
#### Special cases when adding a setting for an experimental feature
- [ ] ⚠️ API stability: The setting does not appear on the main settings route when the feature has never been enabled (e.g. mark it `Unset` when returned from the index in this situation. See [an example](https://github.com/meilisearch/meilisearch/blob/7a89abd2a025606a42f8b219e539117eb2eb029f/meilisearch-types/src/settings.rs#L608))
- [ ] The setting cannot be set when the feature is disabled, either by the main settings route or the subroute (see [`validate_settings` function](https://github.com/meilisearch/meilisearch/blob/7a89abd2a025606a42f8b219e539117eb2eb029f/meilisearch/src/routes/indexes/settings.rs#L811))
- [ ] If possible, the setting is reset when the feature is disabled (hard if it requires reindexing)
## Impacted teams
<!---Ping the related teams. Ask on Slack if any hesitation-->
<!---@meilisearch/docs-team and @meilisearch/integration-team when there is any API change, e.g. settings addition-->
⚠️ Ensure the following requirements before merging ⚠️
- [ ] Automated tests have been added.
- [ ] If some tests cannot be automated, manual rigorous tests should be applied.
- [ ] ⚠️ If there is any change in the DB:
- [ ] Test that any impacted DB still works as expected after using `--experimental-dumpless-upgrade` on a DB created with the last released Meilisearch
- [ ] Test that during the upgrade, **search is still available** (artificially make the upgrade longer if needed)
- [ ] Set the `db change` label.
- [ ] If necessary, the feature have been tested in the Cloud production environment (with [prototypes](./documentation/prototypes.md)) and the Cloud UI is ready.
- [ ] If necessary, the [documentation](https://github.com/meilisearch/documentation) related to the implemented feature in the PR is ready.
- [ ] If necessary, the [integrations](https://github.com/meilisearch/integration-guides) related to the implemented feature in the PR are ready.
This issue is about updating Meilisearch dependencies:
- [ ] Update Meilisearch dependencies with the help of `cargo +nightly udeps --all-targets` (remove unused dependencies) and `cargo upgrade` (upgrade dependencies versions) - ⚠️ Some repositories may contain subdirectories (like heed, charabia, or deserr). Take care of updating these in the main crate as well. This won't be done automatically by `cargo upgrade`.
- [ ] If new Rust versions have been released, update the minimal Rust version in use at Meilisearch:
- [ ] in this [GitHub Action file](https://github.com/meilisearch/meilisearch/blob/main/.github/workflows/test-suite.yml), by changing the `toolchain` field of the `rustfmt` job to the latest available nightly (of the day before or the current day).
- [ ] in every [GitHub Action files](https://github.com/meilisearch/meilisearch/blob/main/.github/workflows), by changing all the `dtolnay/rust-toolchain@` references to use the latest stable version.
- [ ] in this [`rust-toolchain.toml`](https://github.com/meilisearch/meilisearch/blob/main/rust-toolchain.toml), by changing the `channel` field to the latest stable version.
- [ ] in the [Dockerfile](https://github.com/meilisearch/meilisearch/blob/main/Dockerfile), by changing the base image to `rust:<target_rust_version>-alpine<alpine_version>`. Check that the image exists on [Dockerhub](https://hub.docker.com/_/rust/tags?page=1&name=alpine). Also, build and run the image to check everything still works!
⚠️ This issue should be prioritized to avoid any deprecation and vulnerability issues.
The GitHub action dependencies are managed by [Dependabot](https://github.com/meilisearch/meilisearch/blob/main/.github/dependabot.yml), so no need to update them when solving this issue.
You are receiving this message because you declared that this PR make changes to the Meilisearch database.
Depending on the nature of the change, additional actions might be required on your part. The following sections detail the additional actions depending on the nature of the change, please copy the relevant section in the description of your PR, and make sure to perform the required actions.
Thank you for contributing to Meilisearch :heart:
## This PR makes forward-compatible changes
*Forward-compatible changes are changes to the database such that databases created in an older version of Meilisearch are still valid in the new version of Meilisearch. They usually represent additive changes, like adding a new optional attribute or setting.*
- [ ] Detail the change to the DB format and why they are forward compatible
- [ ] Forward-compatibility: A database created before this PR and using the features touched by this PR was able to be opened by a Meilisearch produced by the code of this PR.
## This PR makes breaking changes
*Breaking changes are changes to the database such that databases created in an older version of Meilisearch need changes to remain valid in the new version of Meilisearch. This typically happens when the way to store the data changed (change of database, new required key, etc). This can also happen due to breaking changes in the API of an experimental feature. ⚠️ This kind of changes are more difficult to achieve safely, so proceed with caution and test dumpless upgrade right before merging the PR.*
- [ ] Detail the changes to the DB format,
- [ ] which are compatible, and why
- [ ] which are not compatible, why, and how they will be fixed up in the upgrade
- [ ] /!\ Ensure all the read operations still work!
- If the change happened in milli, you may need to check the version of the database before doing any read operation
- If the change happened in the index-scheduler, make sure the new code can immediately read the old database
- If the change happened in the meilisearch-auth database, reach out to the team; we don't know yet how to handle these changes
- [ ] Write the code to go from the old database to the new one
- If the change happened in milli, the upgrade function should be written and called [here](https://github.com/meilisearch/meilisearch/blob/3fd86e8d76d7d468b0095d679adb09211ca3b6c0/crates/milli/src/update/upgrade/mod.rs#L24-L47)
- If the change happened in the index-scheduler, we've never done it yet, but the right place to do it should be [here](https://github.com/meilisearch/meilisearch/blob/3fd86e8d76d7d468b0095d679adb09211ca3b6c0/crates/index-scheduler/src/scheduler/process_upgrade/mod.rs#L13)
- [ ] Write an integration test [here](https://github.com/meilisearch/meilisearch/blob/main/crates/meilisearch/tests/upgrade/mod.rs) ensuring you can read the old database, upgrade to the new database, and read the new database as expected
Currently this repository hosts two kinds of benchmarks:
1. The older "milli benchmarks", that use [criterion](https://github.com/bheisler/criterion.rs) and live in the "benchmarks" directory.
2. The newer "bench" that are workload-based and so split between the [`workloads`](./workloads/) directory and the [`xtask::bench`](./xtask/src/bench/) module.
This document describes the newer "bench" benchmarks. For more details on the "milli benchmarks", see [benchmarks/README.md](./benchmarks/README.md).
## Design philosophy for the benchmarks
The newer "bench" benchmarks are **integration** benchmarks, in the sense that they spawn an actual Meilisearch server and measure its performance end-to-end, including HTTP request overhead.
Since this is prone to fluctuating, the benchmarks regain a bit of precision by measuring the runtime of the individual spans using the [logging machinery](./CONTRIBUTING.md#logging) of Meilisearch.
A span roughly translates to a function call. The benchmark runner collects all the spans by name using the [logs route](https://github.com/orgs/meilisearch/discussions/721) and sums their runtime. The processed results are then sent to the [benchmark dashboard](https://bench.meilisearch.dev), which is in charge of storing and presenting the data.
## Running the benchmarks
Benchmarks can run locally or in CI.
### Locally
#### With a local benchmark dashboard
The benchmarks dashboard lives in its [own repository](https://github.com/meilisearch/benchboard). We provide binaries for Ubuntu/Debian, but you can build from source for other platforms (MacOS should work as it was developed under that platform).
Run the `benchboard` binary to create a fresh database of results. By default it will serve the results and the API to gather results on `http://localhost:9001`.
From the Meilisearch repository, you can then run benchmarks with:
For processing the results, look at [Looking at benchmark results/Without dashboard](#without-dashboard).
#### Sending a workload by hand
Sometimes you want to visualize the metrics of a worlkoad that comes from a custom report.
It is not quite easy to trick the benchboard in thinking that your report is legitimate but here are the commands you can run to upload your firefox report on a running benchboard.
```bash
# Name this hostname whatever you want
echo'{ "hostname": "the-best-place" }'| xh PUT 'http://127.0.0.1:9001/api/v1/machine'
# You'll receive an UUID from this command that we will call $invocation_uuid
# And now use your $workload_uuid and the content of your firefox report
# but don't forget to convert your firefox report from JSONLines into an object
echo'{ "workload_uuid": "$workload_uuid", "data": $REPORT_JSON_DATA }'| xh PUT 'http://127.0.0.1:9001/api/v1/run'
```
### In CI
We have dedicated runners to run workloads on CI. Currently, there are three ways of running the CI:
1. Automatically, on every push to `main`.
2. Manually, by clicking the [`Run workflow`](https://github.com/meilisearch/meilisearch/actions/workflows/bench-manual.yml) button and specifying the target reference (tag, commit or branch) as well as one or multiple workloads to run. The workloads must exist in the Meilisearch repository (conventionally, in the [`workloads`](./workloads/) directory) on the target reference. Globbing (e.g., `workloads/*.json`) works.
3. Manually on a PR, by posting a comment containing a `/bench` command, followed by one or multiple workloads to run. Globbing works. The workloads must exist in the Meilisearch repository in the branch of the PR.
```
/bench workloads/movies*.json /hackernews_1M.json
```
## Looking at benchmark results
### On the dashboard
Results are available on the global dashboard used by CI at <https://bench.meilisearch.dev> or on your [local dashboard](#with-a-local-benchmark-dashboard).
The dashboard homepage presents three sections:
1. The latest invocations (a call to `cargo xtask bench`, either local or by CI) with their reason (generally set to some helpful link in CI) and their status.
2. The latest workloads ran on `main`.
3. The latest workloads ran on other references.
By default, the workload shows the total runtime delta with the latest applicable commit on `main`. The latest applicable commit is the latest commit for workload invocations that do not originate on `main`, and the latest previous commit for workload invocations that originate on `main`.
You can explicitly request a detailed comparison by span with the `main` branch, the branch or origin, or any previous commit, by clicking the links at the bottom of the workload invocation.
In the detailed comparison view, the spans are sorted by improvements, regressions, stable (no statistically significant change) and unstable (the span runtime is comparable to its standard deviation).
You can click on the name of any span to get a box plot comparing the target commit with multiple commits of the selected branch.
### Without dashboard
After the workloads are done running, the reports will live in the Meilisearch repository, in the `bench/reports` directory (by default).
You can then convert these reports into other formats.
- To [Firefox profiler](https://profiler.firefox.com) format. Run:
```sh
cd bench/reports
cargo run --release --bin trace-to-firefox -- my_workload_1-0-trace.json
```
You can then upload the resulting `firefox-my_workload_1-0-trace.json` file to the online profiler.
## Designing benchmark workloads
Benchmark workloads conventionally live in the `workloads` directory of the Meilisearch repository.
They are JSON files with the following structure (comments are not actually supported, to make your own, remove them or copy some existing workload file):
```jsonc
{
// Name of the workload. Must be unique to the workload, as it will be used to group results on the dashboard.
"name": "hackernews.ndjson_1M,no-threads",
// Number of consecutive runs of the commands that should be performed.
// Each run uses a fresh instance of Meilisearch and a fresh database.
// Each run produces its own report file.
"run_count": 3,
// List of arguments to add to the Meilisearch command line.
"extra_cli_args": ["--max-indexing-threads=1"],
// An expression that can be parsed as a comma-separated list of targets and levels
// as described in [tracing_subscriber's documentation](https://docs.rs/tracing-subscriber/latest/tracing_subscriber/filter/targets/struct.Targets.html#examples).
// The expression is used to filter the spans that are measured for profiling purposes.
// Optional, defaults to "indexing::=trace" (for indexing workloads), common other values is
// "search::=trace"
"target": "indexing::=trace",
// List of named assets that can be used in the commands.
"assets": {
// name of the asset.
// Must be unique at the workload level.
// For better results, the same asset (same sha256) should have the same name accross workloads.
// Having multiple assets with the same name and distinct hashes is supported accross workloads,
// but will lead to superfluous downloads.
//
// Assets are stored in the `bench/assets/` directory by default.
"hackernews-100_000.ndjson": {
// If the assets exists in the local filesystem (Meilisearch repository or for your local workloads)
// Its file path can be specified here.
// `null` if the asset should be downloaded from a remote location.
"local_location": null,
// URL of the remote location where the asset can be downloaded.
// Use the `--assets-key` of the runner to pass an API key in the `Authorization: Bearer` header of the download requests.
// `null` if the asset should be imported from a local location.
// if both local and remote locations are specified, then the local one is tried first, then the remote one
// if the file is locally missing or its hash differs.
// Optional: A precommand is a request to the Meilisearch instance that is executed before the profiling runs.
"precommands": [
{
// Meilisearch route to call. `http://localhost:7700/` will be prepended.
"route": "indexes/movies/settings",
// HTTP method to call.
"method": "PATCH",
// If applicable, body of the request.
// Optional, if missing, the body will be empty.
"body": {
// One of "empty", "inline" or "asset".
// If using "empty", you can skip the entire "body" key.
"inline": {
// when "inline" is used, the body is the JSON object that is the value of the `"inline"` key.
"displayedAttributes": [
"title",
"by",
"score",
"time"
],
"searchableAttributes": [
"title"
],
"filterableAttributes": [
"by"
],
"sortableAttributes": [
"score",
"time"
]
}
},
// Whether to wait before running the next request.
// One of:
// - DontWait: run the next command without waiting the response to this one.
// - WaitForResponse: run the next command as soon as the response from the server is received.
// - WaitForTask: run the next command once **all** the Meilisearch tasks created up to now have finished processing.
"synchronous": "WaitForTask"
}
],
// A command is a request to the Meilisearch instance that is executed while the profiling runs.
"commands": [
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
// When using "asset", use the name of an asset as value to use the content of that asset as body.
// the content type is derived of the format of the asset:
// "NdJson" => "application/x-ndjson"
// "Json" => "application/json"
// "Raw" => "application/octet-stream"
// See [AssetFormat::to_content_type](https://github.com/meilisearch/meilisearch/blob/7b670a4afadb132ac4a01b6403108700501a391d/xtask/src/bench/assets.rs#L30)
// for details and up-to-date list.
"asset": "hackernews-100_000.ndjson"
},
"synchronous": "WaitForTask"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-200_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-300_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-400_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-500_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-600_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-700_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-800_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-900_000.ndjson"
},
"synchronous": "WaitForResponse"
},
{
"route": "indexes/movies/documents",
"method": "POST",
"body": {
"asset": "hackernews-1_000_000.ndjson"
},
"synchronous": "WaitForTask"
}
]
}
```
### Adding new assets
Assets reside in our DigitalOcean S3 space. Assuming you have team access to the DigitalOcean S3 space:
1. go to <https://cloud.digitalocean.com/spaces/milli-benchmarks?i=d1c552&path=bench%2Fdatasets%2F>
2. upload your dataset:
1. if your dataset is a single file, upload that single file using the "upload" button,
2. otherwise, create a folder using the "create folder" button, then inside that folder upload your individual files.
## Upgrading `https://bench.meilisearch.dev`
The URL of the server is in our password manager (look for "benchboard").
1. Make the needed modifications on the [benchboard repository](https://github.com/meilisearch/benchboard) and merge them to main.
2. Publish a new release to produce the Ubuntu/Debian binary.
3. Download the binary locally, send it to the server:
@@ -4,7 +4,7 @@ First, thank you for contributing to Meilisearch! The goal of this document is t
Remember that there are many ways to contribute other than writing code: writing [tutorials or blog posts](https://github.com/meilisearch/awesome-meilisearch), improving [the documentation](https://github.com/meilisearch/documentation), submitting [bug reports](https://github.com/meilisearch/meilisearch/issues/new?assignees=&labels=&template=bug_report.md&title=) and [feature requests](https://github.com/meilisearch/product/discussions/categories/feedback-feature-proposal)...
The code in this repository is only concerned with managing multiple indexes, handling the update store, and exposing an HTTP API. Search and indexation are the domain of our core engine, [`milli`](https://github.com/meilisearch/milli), while tokenization is handled by [our `charabia` library](https://github.com/meilisearch/charabia/).
Meilisearch can manage multiple indexes, handle the update store, and expose an HTTP API. Search and indexation are the domain of our core engine, [`milli`](https://github.com/meilisearch/meilisearch/tree/main/milli), while tokenization is handled by [our `charabia` library](https://github.com/meilisearch/charabia/).
If Meilisearch does not offer optimized support for your language, please consider contributing to `charabia` by following the [CONTRIBUTING.md file](https://github.com/meilisearch/charabia/blob/main/CONTRIBUTING.md) and integrating your intended normalizer/segmenter.
@@ -18,9 +18,9 @@ If Meilisearch does not offer optimized support for your language, please consid
## Assumptions
1.**You're familiar with [GitHub](https://github.com) and the [Pull Requests](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)(PR) workflow.**
2.**You've read the Meilisearch [documentation](https://docs.meilisearch.com).**
3. **You know about the [Meilisearch community](https://docs.meilisearch.com/learn/what_is_meilisearch/contact.html).
1.**You're familiar with [GitHub](https://github.com) and the [Pull Requests (PR)](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests) workflow.**
2.**You've read the Meilisearch [documentation](https://www.meilisearch.com/docs).**
3. **You know about the [Meilisearch community on Discord](https://discord.meilisearch.com).
Please use this for help.**
## How to Contribute
@@ -52,6 +52,28 @@ cargo test
This command will be triggered to each PR as a requirement for merging it.
#### Faster build
You can set the `LINDERA_CACHE` environment variable to speed up your successive builds by up to 2 minutes.
It'll store some built artifacts in the directory of your choice.
We recommend using the `$HOME/.cache/meili/lindera` directory:
```sh
exportLINDERA_CACHE=$HOME/.cache/meili/lindera
```
You can set the `MILLI_BENCH_DATASETS_PATH` environment variable to further speed up your builds.
It'll store some big files used for the benchmarks in the directory of your choice.
We recommend using the `$HOME/.cache/meili/benches` directory:
Furthermore, you can improve incremental compilation by setting the `MEILI_NO_VERGEN` environment variable.
Setting this variable will prevent the Meilisearch binary from being rebuilt each time the directory that hosts the Meilisearch repository changes.
Do not enable this environment variable for production builds (as it will break the `version` route, among other things).
#### Snapshot-based tests
We are using [insta](https://insta.rs) to perform snapshot-based testing.
@@ -63,7 +85,7 @@ Furthermore, we provide some macros on top of insta, notably a way to use snapsh
To effectively debug snapshot-based hashes, we recommend you export the `MEILI_TEST_FULL_SNAPS` environment variable so that snapshot are fully created locally:
```
```sh
exportMEILI_TEST_FULL_SNAPS=true# add this to your .bashrc, .zshrc, ...
```
@@ -75,6 +97,53 @@ If you get a "Too many open files" error you might want to increase the open fil
ulimit -Sn 3000
```
#### Build tools
Meilisearch follows the [cargo xtask](https://github.com/matklad/cargo-xtask) workflow to provide some build tools.
Run `cargo xtask --help` from the root of the repository to find out what is available.
#### Update the openAPI file if the APIchanged
To update the openAPI file in the code, see [sprint_issue.md](https://github.com/meilisearch/meilisearch/blob/main/.github/ISSUE_TEMPLATE/sprint_issue.md#reminders-when-modifying-the-api).
If you want to generate OpenAPI file manually:
With swagger:
- Starts Meilisearch with the `swagger` feature flag: `cargo run --features swagger`
- On a browser, open the following URL: http://localhost:7700/scalar
- Click the « Download openAPI file »
With the internal crate:
```bash
cd crates/openapi-generator
cargo run --release -- --pretty --output meilisearch.json
```
### Logging
Meilisearch uses [`tracing`](https://lib.rs/crates/tracing) for logging purposes. Tracing logs are structured and can be displayed as JSON to the end user, so prefer passing arguments as fields rather than interpolating them in the message.
Refer to the [documentation](https://docs.rs/tracing/0.1.40/tracing/index.html#using-the-macros) for the syntax of the spans and events.
Logging spans are used for 3 distinct purposes:
1. Regular logging
2. Profiling
3. Benchmarking
As a result, the spans should follow some rules:
- They should not be put on functions that are called too often. That is because opening and closing a span causes some overhead. For regular logging, avoid putting spans on functions that are taking less than a few hundred nanoseconds. For profiling or benchmarking, avoid putting spans on functions that are taking less than a few microseconds.
- For profiling and benchmarking, use the `TRACE` level.
- For profiling and benchmarking, use the following `target` prefixes:
-`indexing::` for spans meant when profiling the indexing operations.
-`search::` for spans meant when profiling the search operations.
### Benchmarking
See [BENCHMARKS.md](./BENCHMARKS.md)
## Git Guidelines
### Git Branches
@@ -101,48 +170,39 @@ Some notes on GitHub PRs:
- The PR title should be accurate and descriptive of the changes.
- [Convert your PR as a draft](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/changing-the-stage-of-a-pull-request) if your changes are a work in progress: no one will review it until you pass your PR as ready for review.<br>
The draft PRs are recommended when you want to show that you are working on something and make your work visible.
- The branch related to the PR must be **up-to-date with `main`** before merging. Fortunately, this project uses [Bors](https://github.com/bors-ng/bors-ng) to automatically enforce this requirement without the PR author having to rebase manually.
- The branch related to the PR must be **up-to-date with `main`** before merging. Fortunately, this project uses [GitHub Merge Queues](https://github.blog/news-insights/product-news/github-merge-queue-is-generally-available/) to automatically enforce this requirement without the PR author having to rebase manually.
## Release Process (for internal team only)
## Merging PRs
This project uses GitHub Merge Queues that helps us manage pull requests merging.
Before merging a PR, the maintainer should ensure the following requirements are met
- Automated tests have been added.
- If some tests cannot be automated, manual rigorous tests should be applied.
- ⚠️ If there is an change in the DB: it's mandatory to manually test the `--experimental-dumpless-upgrade` on a DB of the previous Meilisearch minor version (e.g. v1.13 for the v1.14 release).
- If necessary, the feature have been tested in the Cloud production environment (with [prototypes](./documentation/prototypes.md)) and the Cloud UI is ready.
- If necessary, the [documentation](https://github.com/meilisearch/documentation) related to the implemented feature in the PR is ready.
- If necessary, the [integrations](https://github.com/meilisearch/integration-guides) related to the implemented feature in the PR are ready.
## Publish Process (for internal team only)
Meilisearch tools follow the [Semantic Versioning Convention](https://semver.org/).
### Automation to rebase and Merge the PRs
### How to publish a new release
This project integrates a bot that helps us manage pull requests merging.<br>
_[Read more about this](https://github.com/meilisearch/integration-guides/blob/main/resources/bors.md)._
### How to Publish a new Release
The full Meilisearch release process is described in [this guide](https://github.com/meilisearch/engine-team/blob/main/resources/meilisearch-release.md). Please follow it carefully before doing any release.
The full Meilisearch release process is described in [this guide](./documentation/release.md).
### How to publish a prototype
Depending on the developed feature, you might need to provide a prototyped version of Meilisearch to make it easier to test by the users.
The prototype name must follow this convention: `prototype-X-Y` where
-`X` is the feature name formatted in `kebab-case`. It should not end with a single number.
-`Y` is the version of the prototype, starting from `0`.
This happens in two steps:
-[Release the prototype](./documentation/prototypes.md#how-to-publish-a-prototype)
-[Communicate about it](./documentation/prototypes.md#communication)
✅ Example: `prototype-auto-resize-0`. </br>
❌ Bad example: `auto-resize-0`: lacks the `prototype` prefix. </br>
❌ Bad example: `prototype-auto-resize`: lacks the version suffix. </br>
❌ Bad example: `prototype-auto-resize-0-0`: feature name ends with a single number.
### How to implement and publish an experimental feature
Steps to create a prototype:
1. In your terminal, go to the last commit of your branch (the one you want to provide as a prototype).
2. Create a tag following the convention: `git tag prototype-X-Y`
3. Run Meilisearch and check that its launch summary features a line: `Prototype: prototype-X-Y` (you may need to switch branches and back after tagging for this to work).
3. Push the tag: `git push origin prototype-X-Y`
4. Check the [Docker CI](https://github.com/meilisearch/meilisearch/actions/workflows/publish-docker-images.yml) is now running.
🐳 Once the CI has finished to run (~1h30), a Docker image named `prototype-X-Y` will be available on [DockerHub](https://hub.docker.com/repository/docker/getmeili/meilisearch/general). People can use it with the following command: `docker run -p 7700:7700 -v $(pwd)/meili_data:/meili_data getmeili/meilisearch:prototype-X-Y`. <br>
More information about [how to run Meilisearch with Docker](https://docs.meilisearch.com/learn/cookbooks/docker.html#download-meilisearch-with-docker).
⚙️ However, no binaries will be created. If the users do not use Docker, they can go to the `prototype-X-Y` tag in the Meilisearch repository and compile from the source code.
⚠️ When sharing a prototype with users, remind them to not use it in production. Prototypes are solely for test purposes.
Here is our [guidelines and process](./documentation/experimental-features.md) to implement and publish an experimental feature.
Search engine technologies are complex pieces of software that require thorough profiling tools. We chose to use [Puffin](https://github.com/EmbarkStudios/puffin), which the Rust gaming industry uses extensively. You can export and import the profiling reports using the top bar's _File_ menu options [in Puffin Viewer](https://github.com/embarkstudios/puffin#ui).

## Profiling the Indexing Process
When you enable [the `exportPuffinReports` experimental feature](https://www.meilisearch.com/docs/learn/experimental/overview) of Meilisearch, Puffin reports with the `.puffin` extension will be automatically exported to disk. When this option is enabled, the engine will automatically create a "frame" whenever it executes the `IndexScheduler::tick` method.
[Puffin Viewer](https://github.com/EmbarkStudios/puffin/tree/main/puffin_viewer) is used to analyze the reports. Those reports show areas where Meilisearch spent time during indexing.
Another piece of advice on the Puffin viewer UI interface is to consider the _Merge children with same ID_ option. It can hide the exact actual timings at which events were sent. Please turn it off when you see strange gaps on the Flamegraph. It can help.
## Profiling the Search Process
We still need to take the time to profile the search side of the engine with Puffin. It would require time to profile the filtering phase, query parsing, creation, and execution. We could even profile the Actix HTTP server.
The only issue we see is the framing system. Puffin requires a global frame-based profiling phase, which collides with Meilisearch's ability to accept and answer multiple requests on different threads simultaneously.
<palign="center">⚡ A lightning-fast search engine that fits effortlessly into your apps, websites, and workflow 🔍</p>
Meilisearch helps you shape a delightful search experience in a snap, offering features that work out-of-the-box to speed up your workflow.
[Meilisearch](https://www.meilisearch.com?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=intro) helps you shape a delightful search experience in a snap, offering features that work outofthebox to speed up your workflow.
- [**Movies**](https://where2watch.meilisearch.com/?utm_campaign=oss&utm_source=github&utm_medium=organization) — An application to help you find streaming platforms to watch movies using [hybrid search](https://www.meilisearch.com/solutions/hybrid-search?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=demos).
- [**Ecommerce**](https://ecommerce.meilisearch.com/?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=demos) — Ecommerce website using disjunctive [facets](https://www.meilisearch.com/docs/learn/fine_tuning_results/faceted_search?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=demos), range and rating filtering, and pagination.
- [**Songs**](https://music.meilisearch.com/?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=demos) — Search through 47 million of songs.
- [**SaaS**](https://saas.meilisearch.com/?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=demos) — Search for contacts, deals, and companies in this [multi-tenant](https://www.meilisearch.com/docs/learn/security/multitenancy_tenant_tokens?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=demos) CRM application.
See the list of all our example apps in our [demos repository](https://github.com/meilisearch/demos).
## ✨ Features
- **Search-as-you-type:** find search results in less than 50 milliseconds
- **[Typo tolerance](https://docs.meilisearch.com/learn/getting_started/customizing_relevancy.html#typo-tolerance):** get relevant matches even when queries contain typos and misspellings
- **[Filtering and faceted search](https://docs.meilisearch.com/learn/advanced/filtering_and_faceted_search.html):** enhance your user's search experience with custom filters and build a faceted search interface in a few lines of code
- **[Sorting](https://docs.meilisearch.com/learn/advanced/sorting.html):** sort results based on price, date, or pretty much anything else your users need
- **[Synonym support](https://docs.meilisearch.com/learn/getting_started/customizing_relevancy.html#synonyms):** configure synonyms to include more relevant content in your search results
- **[Geosearch](https://docs.meilisearch.com/learn/advanced/geosearch.html):** filter and sort documents based on geographic data
- **[Extensive language support](https://docs.meilisearch.com/learn/what_is_meilisearch/language.html):** search datasets in any language, with optimized support for Chinese, Japanese, Hebrew, and languages using the Latin alphabet
- **[Security management](https://docs.meilisearch.com/learn/security/master_api_keys.html):** control which users can access what data with API keys that allow fine-grained permissions handling
- **[Multi-Tenancy](https://docs.meilisearch.com/learn/security/tenant_tokens.html):** personalize search results for any number of application tenants
- **Hybrid search:** Combine the best of both [semantic](https://www.meilisearch.com/docs/learn/experimental/vector_search?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features) & full-text search to get the most relevant results
- **Search-as-you-type:** Find & display results in less than 50 milliseconds to provide an intuitive experience
- **[Typo tolerance](https://www.meilisearch.com/docs/learn/relevancy/typo_tolerance_settings?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** get relevant matches even when queries contain typos and misspellings
- **[Filtering](https://www.meilisearch.com/docs/learn/fine_tuning_results/filtering?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features) and [faceted search](https://www.meilisearch.com/docs/learn/fine_tuning_results/faceted_search?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** enhance your users' search experience with custom filters and build a faceted search interface in a few lines of code
- **[Sorting](https://www.meilisearch.com/docs/learn/fine_tuning_results/sorting?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** sort results based on price, date, or pretty much anything else your users need
- **[Synonym support](https://www.meilisearch.com/docs/learn/relevancy/synonyms?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** configure synonyms to include more relevant content in your search results
- **[Geosearch](https://www.meilisearch.com/docs/learn/fine_tuning_results/geosearch?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** filter and sort documents based on geographic data
- **[Extensive language support](https://www.meilisearch.com/docs/learn/what_is_meilisearch/language?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** search datasets in any language, with optimized support for Chinese, Japanese, Hebrew, and languages using the Latin alphabet
- **[Security management](https://www.meilisearch.com/docs/learn/security/master_api_keys?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** control which users can access what data with API keys that allow fine-grained permissions handling
- **[Multi-Tenancy](https://www.meilisearch.com/docs/learn/security/multitenancy_tenant_tokens?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** personalize search results for any number of application tenants
- **Highly Customizable:** customize Meilisearch to your specific needs or use our out-of-the-box and hassle-free presets
- **[RESTful API](https://docs.meilisearch.com/reference/api/overview.html):** integrate Meilisearch in your technical stack with our plugins and SDKs
- **[RESTful API](https://www.meilisearch.com/docs/reference/api/overview?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=features):** integrate Meilisearch in your technical stack with our plugins and SDKs
- **AI-ready:** works out of the box with [langchain](https://www.meilisearch.com/with/langchain) and the [model context protocol](https://github.com/meilisearch/meilisearch-mcp)
- **Easy to install, deploy, and maintain**
## 📖 Documentation
You can consult Meilisearch's documentation at [https://docs.meilisearch.com](https://docs.meilisearch.com/).
You can consult Meilisearch's documentation at [meilisearch.com/docs](https://www.meilisearch.com/docs/?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=docs).
## 🚀 Getting started
For basic instructions on how to set up Meilisearch, add documents to an index, and search for documents, take a look at our [Quick Start](https://docs.meilisearch.com/learn/getting_started/quick_start.html) guide.
For basic instructions on how to set up Meilisearch, add documents to an index, and search for documents, take a look at our [documentation](https://www.meilisearch.com/docs?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=get-started) guide.
You may also want to check out [Meilisearch 101](https://docs.meilisearch.com/learn/getting_started/filtering_and_sorting.html) for an introduction to some of Meilisearch's most popular features.
## 🌍 Supercharge your Meilisearch experience
## ☁️ Meilisearch cloud
Let us manage your infrastructure so you can focus on integrating a great search experience. Try [Meilisearch Cloud](https://meilisearch.com/pricing) today.
Say goodbye to server deployment and manual updates with [Meilisearch Cloud](https://www.meilisearch.com/cloud?utm_campaign=oss&utm_source=github&utm_medium=meilisearch). Additional features include analytics & monitoring in many regions around the world. No credit card is required.
## 🧰 SDKs & integration tools
Install one of our SDKs in your project for seamless integration between Meilisearch and your favorite language or framework!
Take a look at the complete [Meilisearch integration list](https://docs.meilisearch.com/learn/what_is_meilisearch/sdks.html).
Take a look at the complete [Meilisearch integration list](https://www.meilisearch.com/docs/learn/what_is_meilisearch/sdks?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=sdks-link).
[](https://docs.meilisearch.com/learn/what_is_meilisearch/sdks.html)
[](https://www.meilisearch.com/docs/learn/what_is_meilisearch/sdks?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=sdks-logos)
## ⚙️ Advanced usage
Experienced users will want to keep our [API Reference](https://docs.meilisearch.com/reference/api) close at hand.
Experienced users will want to keep our [API Reference](https://www.meilisearch.com/docs/reference/api/overview?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced) close at hand.
We also offer a wide range of dedicated guides to all Meilisearch features, such as [filtering](https://docs.meilisearch.com/learn/advanced/filtering_and_faceted_search.html), [sorting](https://docs.meilisearch.com/learn/advanced/sorting.html), [geosearch](https://docs.meilisearch.com/learn/advanced/geosearch.html), [API keys](https://docs.meilisearch.com/learn/security/master_api_keys.html), and [tenant tokens](https://docs.meilisearch.com/learn/security/tenant_tokens.html).
We also offer a wide range of dedicated guides to all Meilisearch features, such as [filtering](https://www.meilisearch.com/docs/learn/fine_tuning_results/filtering?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced), [sorting](https://www.meilisearch.com/docs/learn/fine_tuning_results/sorting?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced), [geosearch](https://www.meilisearch.com/docs/learn/fine_tuning_results/geosearch?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced), [API keys](https://www.meilisearch.com/docs/learn/security/master_api_keys?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced), and [tenant tokens](https://www.meilisearch.com/docs/learn/security/tenant_tokens?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced).
Finally, for more in-depth information, refer to our articles explaining fundamental Meilisearch concepts such as [documents](https://docs.meilisearch.com/learn/core_concepts/documents.html) and [indexes](https://docs.meilisearch.com/learn/core_concepts/indexes.html).
Finally, for more in-depth information, refer to our articles explaining fundamental Meilisearch concepts such as [documents](https://www.meilisearch.com/docs/learn/core_concepts/documents?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced) and [indexes](https://www.meilisearch.com/docs/learn/core_concepts/indexes?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=advanced).
## 📊 Telemetry
Meilisearch collects **anonymized**data from users to help us improve our product. You can [deactivate this](https://docs.meilisearch.com/learn/what_is_meilisearch/telemetry.html#how-to-disable-data-collection) whenever you want.
Meilisearch collects **anonymized**user data to help us improve our product. You can [deactivate this](https://www.meilisearch.com/docs/learn/what_is_meilisearch/telemetry?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=telemetry#how-to-disable-data-collection) whenever you want.
To request deletion of collected data, please write to us at[privacy@meilisearch.com](mailto:privacy@meilisearch.com). Don't forget to include your `Instance UID` in the message, as this helps us quickly find and delete your data.
To request deletion of collected data, please write to us at[privacy@meilisearch.com](mailto:privacy@meilisearch.com). Remember to include your `Instance UID` in the message, as this helps us quickly find and delete your data.
If you want to know more about the kind of data we collect and what we use it for, check the [telemetry section](https://docs.meilisearch.com/learn/what_is_meilisearch/telemetry.html) of our documentation.
If you want to know more about the kind of data we collect and what we use it for, check the [telemetry section](https://www.meilisearch.com/docs/learn/what_is_meilisearch/telemetry?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=telemetry#how-to-disable-data-collection) of our documentation.
## 📫 Get in touch!
Meilisearch is a search engine created by [Meili](https://www.welcometothejungle.com/en/companies/meilisearch), a software development company based in France and with team members all over the world. Want to know more about us? [Check out our blog!](https://blog.meilisearch.com/)
Meilisearch is a search engine created by [Meili](https://www.meilisearch.com/careers), a software development company headquartered in France and with team members all over the world. Want to know more about us? [Check out our blog!](https://blog.meilisearch.com/?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=contact)
🗞 [Subscribe to our newsletter](https://meilisearch.us2.list-manage.com/subscribe?u=27870f7b71c908a8b359599fb&id=79582d828e) if you don't want to miss any updates! We promise we won't clutter your mailbox: we only send one edition every two months.
@@ -96,19 +107,18 @@ Meilisearch is a search engine created by [Meili](https://www.welcometothejungle
- For feature requests, please visit our [product repository](https://github.com/meilisearch/product/discussions)
- Found a bug? Open an [issue](https://github.com/meilisearch/meilisearch/issues)!
- Want to be part of our Discord community? [Join us!](https://discord.gg/meilisearch)
- For everything else, please check [this page listing some of the other places where you can find us](https://docs.meilisearch.com/learn/what_is_meilisearch/contact.html)
- Want to be part of our Discord community? [Join us!](https://discord.meilisearch.com/?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=contact)
Thank you for your support!
## 👩💻 Contributing
Meilisearch is, and will always be, open-source! If you want to contribute to the project, please take a look at [our contribution guidelines](CONTRIBUTING.md).
Meilisearch is, and will always be, open-source! If you want to contribute to the project, please look at [our contribution guidelines](CONTRIBUTING.md).
## 📦 Versioning
Meilisearch releases and their associated binaries are available [in this GitHub page](https://github.com/meilisearch/meilisearch/releases).
Meilisearch releases and their associated binaries are available on the project's [releases page](https://github.com/meilisearch/meilisearch/releases).
The binaries are versioned following [SemVer conventions](https://semver.org/). To know more, read our [versioning policy](https://github.com/meilisearch/engine-team/blob/main/resources/versioning-policy.md).
The binaries are versioned following [SemVer conventions](https://semver.org/). To know more, read our [versioning policy](./documentation/versioning-policy.md).
Differently from the binaries, crates in this repository are not currently available on [crates.io](https://crates.io/) and do not follow [SemVer conventions](https://semver.org).
text: r#"He used to do the door sounds in "StarTrek" with his mouth, phssst, phssst. The MD-11 passenger and cargo doors also tend to behave like electromagnetic apertures, because the doors do not have continuous electrical contact with the door frames around the door perimeter. But Theodor said that the doors don't work."#,
assert!(update_files[0].is_none());// the dump creation
assert!(update_files[1].is_some());// the enqueued document addition
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}