mirror of
https://github.com/meilisearch/meilisearch.git
synced 2025-11-29 09:15:38 +00:00
Compare commits
76 Commits
prototype-
...
prototype-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
a3f7bacf9b | ||
|
|
09bc2bb8a2 | ||
|
|
03c4bc7bbc | ||
|
|
6dea7e5a32 | ||
|
|
00caf25ea9 | ||
|
|
dc2546af21 | ||
|
|
077797b50a | ||
|
|
cde36923c5 | ||
|
|
01bacf500e | ||
|
|
ec0ecb5515 | ||
|
|
5cfb066b0a | ||
|
|
a5f44a5ceb | ||
|
|
bc25f378e8 | ||
|
|
6a068fe36a | ||
|
|
8d826e478f | ||
|
|
4d308d5237 | ||
|
|
b4c01581cd | ||
|
|
67fd3b08ef | ||
|
|
1690aec7f1 | ||
|
|
f267bed352 | ||
|
|
597d57bf1d | ||
|
|
01ac8344ad | ||
|
|
3508ba2f20 | ||
|
|
1e6fe71a67 | ||
|
|
0fba08cd72 | ||
|
|
189d4c3b70 | ||
|
|
2fff6f7f23 | ||
|
|
fddfb37f1f | ||
|
|
52b4090286 | ||
|
|
3cabfb448b | ||
|
|
77cf5b3787 | ||
|
|
3acc5bbb15 | ||
|
|
114436926f | ||
|
|
0f7904fb38 | ||
|
|
590b1d8fb7 | ||
|
|
be9741eb8a | ||
|
|
0177d66149 | ||
|
|
1861c69964 | ||
|
|
cb2b5eb38e | ||
|
|
53aa0a1b54 | ||
|
|
950f73b8bb | ||
|
|
e7153e0a97 | ||
|
|
37a24a4a05 | ||
|
|
6592746337 | ||
|
|
efea1e5837 | ||
|
|
b744f33530 | ||
|
|
d4f54fc55e | ||
|
|
a50b058557 | ||
|
|
514b60f8c8 | ||
|
|
a2b151e877 | ||
|
|
fb1260ee88 | ||
|
|
48a51e5cd6 | ||
|
|
2f8eb4f54a | ||
|
|
dea101e3d9 | ||
|
|
175e8a8495 | ||
|
|
6da54d0cb6 | ||
|
|
667bb87e35 | ||
|
|
dff2715ef3 | ||
|
|
5deea631ea | ||
|
|
b4b859ec8c | ||
|
|
b99ef3d336 | ||
|
|
7e2fd82e41 | ||
|
|
24c0775c67 | ||
|
|
3092cf0448 | ||
|
|
37d4551e8e | ||
|
|
da48506f15 | ||
|
|
2f5b9fbbd8 | ||
|
|
7faa9a22f6 | ||
|
|
370d88f626 | ||
|
|
d34faa8f9c | ||
|
|
e5d0bef6d8 | ||
|
|
76288fad72 | ||
|
|
076a3d371c | ||
|
|
3bbf760542 | ||
|
|
fd5c48941a | ||
|
|
e704728ee7 |
{kind=link}
3
.github/ISSUE_TEMPLATE/bug_report.md
vendored
3
.github/ISSUE_TEMPLATE/bug_report.md
vendored
@@ -23,7 +23,8 @@ A clear and concise description of what you expected to happen.
|
||||
**Screenshots**
|
||||
If applicable, add screenshots to help explain your problem.
|
||||
|
||||
**Meilisearch version:** [e.g. v0.20.0]
|
||||
**Meilisearch version:**
|
||||
[e.g. v0.20.0]
|
||||
|
||||
**Additional context**
|
||||
Additional information that may be relevant to the issue.
|
||||
|
||||
34
.github/ISSUE_TEMPLATE/sprint_issue.md
vendored
Normal file
34
.github/ISSUE_TEMPLATE/sprint_issue.md
vendored
Normal file
@@ -0,0 +1,34 @@
|
||||
---
|
||||
name: New sprint issue
|
||||
about: ⚠️ Should only be used by the engine team ⚠️
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
Related product team resources: [roadmap card]() (_internal only_) and [PRD]() (_internal only_)
|
||||
Related product discussion:
|
||||
Related spec: WIP
|
||||
|
||||
## Motivation
|
||||
|
||||
<!---Copy/paste the information in the roadmap resources or briefly detail the product motivation. Ask product team if any hesitation.-->
|
||||
|
||||
## Usage
|
||||
|
||||
<!---Write a quick description of the usage if the usage has already been defined-->
|
||||
|
||||
Refer to the final spec to know the details and the final decisions about the usage.
|
||||
|
||||
## TODO
|
||||
|
||||
<!---Feel free to adapt this list with more technical/product steps-->
|
||||
|
||||
- [ ] Release a prototype
|
||||
- [ ] If prototype validated, merge changes into `main`
|
||||
- [ ] Update the spec
|
||||
|
||||
## Impacted teams
|
||||
|
||||
<!---Ping the related teams. Ask for the engine manager if any hesitation-->
|
||||
40
.github/workflows/publish-binaries.yml
vendored
40
.github/workflows/publish-binaries.yml
vendored
@@ -96,14 +96,12 @@ jobs:
|
||||
|
||||
publish-macos-apple-silicon:
|
||||
name: Publish binary for macOS silicon
|
||||
runs-on: ${{ matrix.os }}
|
||||
runs-on: macos-12
|
||||
needs: check-version
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
include:
|
||||
- os: macos-12
|
||||
target: aarch64-apple-darwin
|
||||
- target: aarch64-apple-darwin
|
||||
asset_name: meilisearch-macos-apple-silicon
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
@@ -132,21 +130,29 @@ jobs:
|
||||
|
||||
publish-aarch64:
|
||||
name: Publish binary for aarch64
|
||||
runs-on: ${{ matrix.os }}
|
||||
runs-on: ubuntu-latest
|
||||
needs: check-version
|
||||
container:
|
||||
# Use ubuntu-18.04 to compile with glibc 2.27
|
||||
image: ubuntu:18.04
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
include:
|
||||
- build: aarch64
|
||||
os: ubuntu-18.04
|
||||
target: aarch64-unknown-linux-gnu
|
||||
linker: gcc-aarch64-linux-gnu
|
||||
use-cross: true
|
||||
- target: aarch64-unknown-linux-gnu
|
||||
asset_name: meilisearch-linux-aarch64
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v3
|
||||
- name: Install needed dependencies
|
||||
run: |
|
||||
apt-get update -y && apt upgrade -y
|
||||
apt-get install -y curl build-essential gcc-aarch64-linux-gnu
|
||||
- name: Set up Docker for cross compilation
|
||||
run: |
|
||||
apt-get install -y curl apt-transport-https ca-certificates software-properties-common
|
||||
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
|
||||
add-apt-repository "deb [arch=$(dpkg --print-architecture)] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
|
||||
apt-get update -y && apt-get install -y docker-ce
|
||||
- name: Installing Rust toolchain
|
||||
uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
@@ -154,15 +160,7 @@ jobs:
|
||||
profile: minimal
|
||||
target: ${{ matrix.target }}
|
||||
override: true
|
||||
- name: APT update
|
||||
run: |
|
||||
sudo apt update
|
||||
- name: Install target specific tools
|
||||
if: matrix.use-cross
|
||||
run: |
|
||||
sudo apt-get install -y ${{ matrix.linker }}
|
||||
- name: Configure target aarch64 GNU
|
||||
if: matrix.target == 'aarch64-unknown-linux-gnu'
|
||||
## Environment variable is not passed using env:
|
||||
## LD gold won't work with MUSL
|
||||
# env:
|
||||
@@ -176,8 +174,10 @@ jobs:
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
use-cross: ${{ matrix.use-cross }}
|
||||
use-cross: true
|
||||
args: --release --target ${{ matrix.target }}
|
||||
env:
|
||||
CROSS_DOCKER_IN_DOCKER: true
|
||||
- name: List target output files
|
||||
run: ls -lR ./target
|
||||
- name: Upload the binary to release
|
||||
|
||||
10
.github/workflows/test-suite.yml
vendored
10
.github/workflows/test-suite.yml
vendored
@@ -43,7 +43,7 @@ jobs:
|
||||
toolchain: nightly
|
||||
override: true
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.0
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo check without any default features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
@@ -65,7 +65,7 @@ jobs:
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.0
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo check without any default features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
@@ -123,7 +123,7 @@ jobs:
|
||||
toolchain: stable
|
||||
override: true
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.0
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run tests in debug
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
@@ -142,7 +142,7 @@ jobs:
|
||||
override: true
|
||||
components: clippy
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.0
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo clippy
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
@@ -162,7 +162,7 @@ jobs:
|
||||
override: true
|
||||
components: rustfmt
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.0
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo fmt
|
||||
# Since we never ran the `build.rs` script in the benchmark directory we are missing one auto-generated import file.
|
||||
# Since we want to trigger (and fail) this action as fast as possible, instead of building the benchmark crate
|
||||
|
||||
@@ -120,29 +120,9 @@ The full Meilisearch release process is described in [this guide](https://github
|
||||
|
||||
Depending on the developed feature, you might need to provide a prototyped version of Meilisearch to make it easier to test by the users.
|
||||
|
||||
The prototype name must follow this convention: `prototype-X-Y` where
|
||||
- `X` is the feature name formatted in `kebab-case`. It should not end with a single number.
|
||||
- `Y` is the version of the prototype, starting from `0`.
|
||||
|
||||
✅ Example: `prototype-auto-resize-0`. </br>
|
||||
❌ Bad example: `auto-resize-0`: lacks the `prototype` prefix. </br>
|
||||
❌ Bad example: `prototype-auto-resize`: lacks the version suffix. </br>
|
||||
❌ Bad example: `prototype-auto-resize-0-0`: feature name ends with a single number.
|
||||
|
||||
Steps to create a prototype:
|
||||
|
||||
1. In your terminal, go to the last commit of your branch (the one you want to provide as a prototype).
|
||||
2. Create a tag following the convention: `git tag prototype-X-Y`
|
||||
3. Run Meilisearch and check that its launch summary features a line: `Prototype: prototype-X-Y` (you may need to switch branches and back after tagging for this to work).
|
||||
3. Push the tag: `git push origin prototype-X-Y`
|
||||
4. Check the [Docker CI](https://github.com/meilisearch/meilisearch/actions/workflows/publish-docker-images.yml) is now running.
|
||||
|
||||
🐳 Once the CI has finished to run (~1h30), a Docker image named `prototype-X-Y` will be available on [DockerHub](https://hub.docker.com/repository/docker/getmeili/meilisearch/general). People can use it with the following command: `docker run -p 7700:7700 -v $(pwd)/meili_data:/meili_data getmeili/meilisearch:prototype-X-Y`. <br>
|
||||
More information about [how to run Meilisearch with Docker](https://docs.meilisearch.com/learn/cookbooks/docker.html#download-meilisearch-with-docker).
|
||||
|
||||
⚙️ However, no binaries will be created. If the users do not use Docker, they can go to the `prototype-X-Y` tag in the Meilisearch repository and compile from the source code.
|
||||
|
||||
⚠️ When sharing a prototype with users, remind them to not use it in production. Prototypes are solely for test purposes.
|
||||
This happens in two steps:
|
||||
- [Release the prototype](https://github.com/meilisearch/engine-team/blob/main/resources/prototypes.md#how-to-publish-a-prototype)
|
||||
- [Communicate about it](https://github.com/meilisearch/engine-team/blob/main/resources/prototypes.md#communication)
|
||||
|
||||
### Release assets
|
||||
|
||||
|
||||
43
README.md
43
README.md
@@ -7,8 +7,8 @@
|
||||
<a href="https://www.meilisearch.com">Website</a> |
|
||||
<a href="https://roadmap.meilisearch.com/tabs/1-under-consideration">Roadmap</a> |
|
||||
<a href="https://blog.meilisearch.com">Blog</a> |
|
||||
<a href="https://docs.meilisearch.com">Documentation</a> |
|
||||
<a href="https://docs.meilisearch.com/faq/">FAQ</a> |
|
||||
<a href="https://meilisearch.com/docs">Documentation</a> |
|
||||
<a href="https://meilisearch.com/docs/faq">FAQ</a> |
|
||||
<a href="https://discord.meilisearch.com">Discord</a>
|
||||
</h4>
|
||||
|
||||
@@ -36,27 +36,27 @@ Meilisearch helps you shape a delightful search experience in a snap, offering f
|
||||
## ✨ Features
|
||||
|
||||
- **Search-as-you-type:** find search results in less than 50 milliseconds
|
||||
- **[Typo tolerance](https://docs.meilisearch.com/learn/getting_started/customizing_relevancy.html#typo-tolerance):** get relevant matches even when queries contain typos and misspellings
|
||||
- **[Filtering and faceted search](https://docs.meilisearch.com/learn/advanced/filtering_and_faceted_search.html):** enhance your user's search experience with custom filters and build a faceted search interface in a few lines of code
|
||||
- **[Sorting](https://docs.meilisearch.com/learn/advanced/sorting.html):** sort results based on price, date, or pretty much anything else your users need
|
||||
- **[Synonym support](https://docs.meilisearch.com/learn/getting_started/customizing_relevancy.html#synonyms):** configure synonyms to include more relevant content in your search results
|
||||
- **[Geosearch](https://docs.meilisearch.com/learn/advanced/geosearch.html):** filter and sort documents based on geographic data
|
||||
- **[Extensive language support](https://docs.meilisearch.com/learn/what_is_meilisearch/language.html):** search datasets in any language, with optimized support for Chinese, Japanese, Hebrew, and languages using the Latin alphabet
|
||||
- **[Security management](https://docs.meilisearch.com/learn/security/master_api_keys.html):** control which users can access what data with API keys that allow fine-grained permissions handling
|
||||
- **[Multi-Tenancy](https://docs.meilisearch.com/learn/security/tenant_tokens.html):** personalize search results for any number of application tenants
|
||||
- **[Typo tolerance](https://meilisearch.com/docs/learn/getting_started/customizing_relevancy#typo-tolerance):** get relevant matches even when queries contain typos and misspellings
|
||||
- **[Filtering](https://meilisearch.com/docs/learn/advanced/filtering) and [faceted search](https://meilisearch.com/docs/learn/advanced/faceted_search):** enhance your user's search experience with custom filters and build a faceted search interface in a few lines of code
|
||||
- **[Sorting](https://meilisearch.com/docs/learn/advanced/sorting):** sort results based on price, date, or pretty much anything else your users need
|
||||
- **[Synonym support](https://meilisearch.com/docs/learn/getting_started/customizing_relevancy#synonyms):** configure synonyms to include more relevant content in your search results
|
||||
- **[Geosearch](https://meilisearch.com/docs/learn/advanced/geosearch):** filter and sort documents based on geographic data
|
||||
- **[Extensive language support](https://meilisearch.com/docs/learn/what_is_meilisearch/language):** search datasets in any language, with optimized support for Chinese, Japanese, Hebrew, and languages using the Latin alphabet
|
||||
- **[Security management](https://meilisearch.com/docs/learn/security/master_api_keys):** control which users can access what data with API keys that allow fine-grained permissions handling
|
||||
- **[Multi-Tenancy](https://meilisearch.com/docs/learn/security/tenant_tokens):** personalize search results for any number of application tenants
|
||||
- **Highly Customizable:** customize Meilisearch to your specific needs or use our out-of-the-box and hassle-free presets
|
||||
- **[RESTful API](https://docs.meilisearch.com/reference/api/overview.html):** integrate Meilisearch in your technical stack with our plugins and SDKs
|
||||
- **[RESTful API](https://meilisearch.com/docs/reference/api/overview):** integrate Meilisearch in your technical stack with our plugins and SDKs
|
||||
- **Easy to install, deploy, and maintain**
|
||||
|
||||
## 📖 Documentation
|
||||
|
||||
You can consult Meilisearch's documentation at [https://docs.meilisearch.com](https://docs.meilisearch.com/).
|
||||
You can consult Meilisearch's documentation at [https://meilisearch.com/docs](https://meilisearch.com/docs/).
|
||||
|
||||
## 🚀 Getting started
|
||||
|
||||
For basic instructions on how to set up Meilisearch, add documents to an index, and search for documents, take a look at our [Quick Start](https://docs.meilisearch.com/learn/getting_started/quick_start.html) guide.
|
||||
For basic instructions on how to set up Meilisearch, add documents to an index, and search for documents, take a look at our [Quick Start](https://meilisearch.com/docs/learn/getting_started/quick_start) guide.
|
||||
|
||||
You may also want to check out [Meilisearch 101](https://docs.meilisearch.com/learn/getting_started/filtering_and_sorting.html) for an introduction to some of Meilisearch's most popular features.
|
||||
You may also want to check out [Meilisearch 101](https://meilisearch.com/docs/learn/getting_started/filtering_and_sorting) for an introduction to some of Meilisearch's most popular features.
|
||||
|
||||
## ☁️ Meilisearch cloud
|
||||
|
||||
@@ -66,25 +66,25 @@ Let us manage your infrastructure so you can focus on integrating a great search
|
||||
|
||||
Install one of our SDKs in your project for seamless integration between Meilisearch and your favorite language or framework!
|
||||
|
||||
Take a look at the complete [Meilisearch integration list](https://docs.meilisearch.com/learn/what_is_meilisearch/sdks.html).
|
||||
Take a look at the complete [Meilisearch integration list](https://meilisearch.com/docs/learn/what_is_meilisearch/sdks).
|
||||
|
||||
[](https://docs.meilisearch.com/learn/what_is_meilisearch/sdks.html)
|
||||
[](https://meilisearch.com/docs/learn/what_is_meilisearch/sdks.html)
|
||||
|
||||
## ⚙️ Advanced usage
|
||||
|
||||
Experienced users will want to keep our [API Reference](https://docs.meilisearch.com/reference/api) close at hand.
|
||||
Experienced users will want to keep our [API Reference](https://meilisearch.com/docs/reference/api) close at hand.
|
||||
|
||||
We also offer a wide range of dedicated guides to all Meilisearch features, such as [filtering](https://docs.meilisearch.com/learn/advanced/filtering_and_faceted_search.html), [sorting](https://docs.meilisearch.com/learn/advanced/sorting.html), [geosearch](https://docs.meilisearch.com/learn/advanced/geosearch.html), [API keys](https://docs.meilisearch.com/learn/security/master_api_keys.html), and [tenant tokens](https://docs.meilisearch.com/learn/security/tenant_tokens.html).
|
||||
We also offer a wide range of dedicated guides to all Meilisearch features, such as [filtering](https://meilisearch.com/docs/learn/advanced/filtering), [sorting](https://meilisearch.com/docs/learn/advanced/sorting), [geosearch](https://meilisearch.com/docs/learn/advanced/geosearch), [API keys](https://meilisearch.com/docs/learn/security/master_api_keys), and [tenant tokens](https://meilisearch.com/docs/learn/security/tenant_tokens).
|
||||
|
||||
Finally, for more in-depth information, refer to our articles explaining fundamental Meilisearch concepts such as [documents](https://docs.meilisearch.com/learn/core_concepts/documents.html) and [indexes](https://docs.meilisearch.com/learn/core_concepts/indexes.html).
|
||||
Finally, for more in-depth information, refer to our articles explaining fundamental Meilisearch concepts such as [documents](https://meilisearch.com/docs/learn/core_concepts/documents) and [indexes](https://meilisearch.com/docs/learn/core_concepts/indexes).
|
||||
|
||||
## 📊 Telemetry
|
||||
|
||||
Meilisearch collects **anonymized** data from users to help us improve our product. You can [deactivate this](https://docs.meilisearch.com/learn/what_is_meilisearch/telemetry.html#how-to-disable-data-collection) whenever you want.
|
||||
Meilisearch collects **anonymized** data from users to help us improve our product. You can [deactivate this](https://meilisearch.com/docs/learn/what_is_meilisearch/telemetry#how-to-disable-data-collection) whenever you want.
|
||||
|
||||
To request deletion of collected data, please write to us at [privacy@meilisearch.com](mailto:privacy@meilisearch.com). Don't forget to include your `Instance UID` in the message, as this helps us quickly find and delete your data.
|
||||
|
||||
If you want to know more about the kind of data we collect and what we use it for, check the [telemetry section](https://docs.meilisearch.com/learn/what_is_meilisearch/telemetry.html) of our documentation.
|
||||
If you want to know more about the kind of data we collect and what we use it for, check the [telemetry section](https://meilisearch.com/docs/learn/what_is_meilisearch/telemetry) of our documentation.
|
||||
|
||||
## 📫 Get in touch!
|
||||
|
||||
@@ -97,7 +97,6 @@ Meilisearch is a search engine created by [Meili](https://www.welcometothejungle
|
||||
- For feature requests, please visit our [product repository](https://github.com/meilisearch/product/discussions)
|
||||
- Found a bug? Open an [issue](https://github.com/meilisearch/meilisearch/issues)!
|
||||
- Want to be part of our Discord community? [Join us!](https://discord.gg/meilisearch)
|
||||
- For everything else, please check [this page listing some of the other places where you can find us](https://docs.meilisearch.com/learn/what_is_meilisearch/contact.html)
|
||||
|
||||
Thank you for your support!
|
||||
|
||||
|
||||
@@ -159,7 +159,7 @@ impl<'a> Display for Error<'a> {
|
||||
writeln!(f, "The `_geoBoundingBox` filter expects two pairs of arguments: `_geoBoundingBox([latitude, longitude], [latitude, longitude])`.")?
|
||||
}
|
||||
ErrorKind::ReservedGeo(name) => {
|
||||
writeln!(f, "`{}` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance), or _geoBoundingBox([latitude, longitude], [latitude, longitude]) built-in rules to filter on `_geo` coordinates.", name.escape_debug())?
|
||||
writeln!(f, "`{}` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.", name.escape_debug())?
|
||||
}
|
||||
ErrorKind::MisusedGeoRadius => {
|
||||
writeln!(f, "The `_geoRadius` filter is an operation and can't be used as a value.")?
|
||||
|
||||
@@ -141,7 +141,7 @@ pub enum FilterCondition<'a> {
|
||||
Or(Vec<Self>),
|
||||
And(Vec<Self>),
|
||||
GeoLowerThan { point: [Token<'a>; 2], radius: Token<'a> },
|
||||
GeoBoundingBox { top_left_point: [Token<'a>; 2], bottom_right_point: [Token<'a>; 2] },
|
||||
GeoBoundingBox { top_right_point: [Token<'a>; 2], bottom_left_point: [Token<'a>; 2] },
|
||||
}
|
||||
|
||||
impl<'a> FilterCondition<'a> {
|
||||
@@ -362,8 +362,8 @@ fn parse_geo_bounding_box(input: Span) -> IResult<FilterCondition> {
|
||||
}
|
||||
|
||||
let res = FilterCondition::GeoBoundingBox {
|
||||
top_left_point: [args[0][0].into(), args[0][1].into()],
|
||||
bottom_right_point: [args[1][0].into(), args[1][1].into()],
|
||||
top_right_point: [args[0][0].into(), args[0][1].into()],
|
||||
bottom_left_point: [args[1][0].into(), args[1][1].into()],
|
||||
};
|
||||
Ok((input, res))
|
||||
}
|
||||
@@ -382,6 +382,34 @@ fn parse_geo_point(input: Span) -> IResult<FilterCondition> {
|
||||
Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::ReservedGeo("_geoPoint"))))
|
||||
}
|
||||
|
||||
/// geoPoint = WS* "_geoDistance(float WS* "," WS* float WS* "," WS* float)
|
||||
fn parse_geo_distance(input: Span) -> IResult<FilterCondition> {
|
||||
// we want to forbid space BEFORE the _geoDistance but not after
|
||||
tuple((
|
||||
multispace0,
|
||||
tag("_geoDistance"),
|
||||
// if we were able to parse `_geoDistance` we are going to return a Failure whatever happens next.
|
||||
cut(delimited(char('('), separated_list1(tag(","), ws(recognize_float)), char(')'))),
|
||||
))(input)
|
||||
.map_err(|e| e.map(|_| Error::new_from_kind(input, ErrorKind::ReservedGeo("_geoDistance"))))?;
|
||||
// if we succeeded we still return a `Failure` because `geoDistance` filters are not allowed
|
||||
Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::ReservedGeo("_geoDistance"))))
|
||||
}
|
||||
|
||||
/// geo = WS* "_geo(float WS* "," WS* float WS* "," WS* float)
|
||||
fn parse_geo(input: Span) -> IResult<FilterCondition> {
|
||||
// we want to forbid space BEFORE the _geo but not after
|
||||
tuple((
|
||||
multispace0,
|
||||
word_exact("_geo"),
|
||||
// if we were able to parse `_geo` we are going to return a Failure whatever happens next.
|
||||
cut(delimited(char('('), separated_list1(tag(","), ws(recognize_float)), char(')'))),
|
||||
))(input)
|
||||
.map_err(|e| e.map(|_| Error::new_from_kind(input, ErrorKind::ReservedGeo("_geo"))))?;
|
||||
// if we succeeded we still return a `Failure` because `_geo` filter is not allowed
|
||||
Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::ReservedGeo("_geo"))))
|
||||
}
|
||||
|
||||
fn parse_error_reserved_keyword(input: Span) -> IResult<FilterCondition> {
|
||||
match parse_condition(input) {
|
||||
Ok(result) => Ok(result),
|
||||
@@ -418,6 +446,8 @@ fn parse_primary(input: Span, depth: usize) -> IResult<FilterCondition> {
|
||||
parse_not_exists,
|
||||
parse_to,
|
||||
// the next lines are only for error handling and are written at the end to have the less possible performance impact
|
||||
parse_geo,
|
||||
parse_geo_distance,
|
||||
parse_geo_point,
|
||||
parse_error_reserved_keyword,
|
||||
))(input)
|
||||
@@ -621,15 +651,35 @@ pub mod tests {
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("_geoPoint(12, 13, 14)"), @r###"
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance), or _geoBoundingBox([latitude, longitude], [latitude, longitude]) built-in rules to filter on `_geo` coordinates.
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
1:22 _geoPoint(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geoPoint(12, 13, 14)"), @r###"
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance), or _geoBoundingBox([latitude, longitude], [latitude, longitude]) built-in rules to filter on `_geo` coordinates.
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
13:34 position <= _geoPoint(12, 13, 14)
|
||||
"###);
|
||||
|
||||
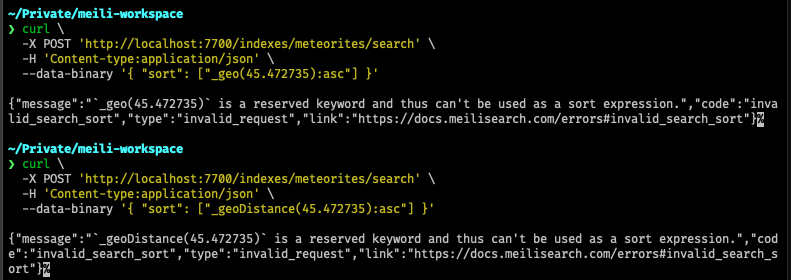
insta::assert_display_snapshot!(p("_geoDistance(12, 13, 14)"), @r###"
|
||||
`_geoDistance` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
1:25 _geoDistance(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geoDistance(12, 13, 14)"), @r###"
|
||||
`_geoDistance` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
13:37 position <= _geoDistance(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("_geo(12, 13, 14)"), @r###"
|
||||
`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
1:17 _geo(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geo(12, 13, 14)"), @r###"
|
||||
`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
13:29 position <= _geo(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geoRadius(12, 13, 14)"), @r###"
|
||||
The `_geoRadius` filter is an operation and can't be used as a value.
|
||||
13:35 position <= _geoRadius(12, 13, 14)
|
||||
@@ -780,7 +830,10 @@ impl<'a> std::fmt::Display for FilterCondition<'a> {
|
||||
FilterCondition::GeoLowerThan { point, radius } => {
|
||||
write!(f, "_geoRadius({}, {}, {})", point[0], point[1], radius)
|
||||
}
|
||||
FilterCondition::GeoBoundingBox { top_left_point, bottom_right_point } => {
|
||||
FilterCondition::GeoBoundingBox {
|
||||
top_right_point: top_left_point,
|
||||
bottom_left_point: bottom_right_point,
|
||||
} => {
|
||||
write!(
|
||||
f,
|
||||
"_geoBoundingBox([{}, {}], [{}, {}])",
|
||||
|
||||
@@ -7,8 +7,8 @@ use nom::{InputIter, InputLength, InputTake, Slice};
|
||||
|
||||
use crate::error::{ExpectedValueKind, NomErrorExt};
|
||||
use crate::{
|
||||
parse_geo_bounding_box, parse_geo_point, parse_geo_radius, Error, ErrorKind, IResult, Span,
|
||||
Token,
|
||||
parse_geo, parse_geo_bounding_box, parse_geo_distance, parse_geo_point, parse_geo_radius,
|
||||
Error, ErrorKind, IResult, Span, Token,
|
||||
};
|
||||
|
||||
/// This function goes through all characters in the [Span] if it finds any escaped character (`\`).
|
||||
@@ -88,11 +88,16 @@ pub fn parse_value(input: Span) -> IResult<Token> {
|
||||
// then, we want to check if the user is misusing a geo expression
|
||||
// This expression can’t finish without error.
|
||||
// We want to return an error in case of failure.
|
||||
if let Err(err) = parse_geo_point(input) {
|
||||
if err.is_failure() {
|
||||
return Err(err);
|
||||
let geo_reserved_parse_functions = [parse_geo_point, parse_geo_distance, parse_geo];
|
||||
|
||||
for parser in geo_reserved_parse_functions {
|
||||
if let Err(err) = parser(input) {
|
||||
if err.is_failure() {
|
||||
return Err(err);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
match parse_geo_radius(input) {
|
||||
Ok(_) => {
|
||||
return Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::MisusedGeoRadius)))
|
||||
|
||||
@@ -675,9 +675,6 @@ impl IndexScheduler {
|
||||
}
|
||||
|
||||
// 3. Snapshot every indexes
|
||||
// TODO we are opening all of the indexes it can be too much we should unload all
|
||||
// of the indexes we are trying to open. It would be even better to only unload
|
||||
// the ones that were opened by us. Or maybe use a LRU in the index mapper.
|
||||
for result in self.index_mapper.index_mapping.iter(&rtxn)? {
|
||||
let (name, uuid) = result?;
|
||||
let index = self.index_mapper.index(&rtxn, name)?;
|
||||
@@ -714,6 +711,14 @@ impl IndexScheduler {
|
||||
// 5.3 Change the permission to make the snapshot readonly
|
||||
let mut permissions = file.metadata()?.permissions();
|
||||
permissions.set_readonly(true);
|
||||
#[cfg(unix)]
|
||||
{
|
||||
use std::os::unix::fs::PermissionsExt;
|
||||
#[allow(clippy::non_octal_unix_permissions)]
|
||||
// rwxrwxrwx
|
||||
permissions.set_mode(0b100100100);
|
||||
}
|
||||
|
||||
file.set_permissions(permissions)?;
|
||||
|
||||
for task in &mut tasks {
|
||||
@@ -828,20 +833,38 @@ impl IndexScheduler {
|
||||
Ok(vec![task])
|
||||
}
|
||||
Batch::IndexOperation { op, must_create_index } => {
|
||||
let index_uid = op.index_uid();
|
||||
let index_uid = op.index_uid().to_string();
|
||||
let index = if must_create_index {
|
||||
// create the index if it doesn't already exist
|
||||
let wtxn = self.env.write_txn()?;
|
||||
self.index_mapper.create_index(wtxn, index_uid, None)?
|
||||
self.index_mapper.create_index(wtxn, &index_uid, None)?
|
||||
} else {
|
||||
let rtxn = self.env.read_txn()?;
|
||||
self.index_mapper.index(&rtxn, index_uid)?
|
||||
self.index_mapper.index(&rtxn, &index_uid)?
|
||||
};
|
||||
|
||||
let mut index_wtxn = index.write_txn()?;
|
||||
let tasks = self.apply_index_operation(&mut index_wtxn, &index, op)?;
|
||||
index_wtxn.commit()?;
|
||||
|
||||
// if the update processed successfully, we're going to store the new
|
||||
// stats of the index. Since the tasks have already been processed and
|
||||
// this is a non-critical operation. If it fails, we should not fail
|
||||
// the entire batch.
|
||||
let res = || -> Result<()> {
|
||||
let index_rtxn = index.read_txn()?;
|
||||
let stats = crate::index_mapper::IndexStats::new(&index, &index_rtxn)?;
|
||||
let mut wtxn = self.env.write_txn()?;
|
||||
self.index_mapper.store_stats_of(&mut wtxn, &index_uid, &stats)?;
|
||||
wtxn.commit()?;
|
||||
Ok(())
|
||||
}();
|
||||
|
||||
match res {
|
||||
Ok(_) => (),
|
||||
Err(e) => error!("Could not write the stats of the index {}", e),
|
||||
}
|
||||
|
||||
Ok(tasks)
|
||||
}
|
||||
Batch::IndexCreation { index_uid, primary_key, task } => {
|
||||
@@ -872,9 +895,31 @@ impl IndexScheduler {
|
||||
)?;
|
||||
index_wtxn.commit()?;
|
||||
}
|
||||
|
||||
// drop rtxn before starting a new wtxn on the same db
|
||||
rtxn.commit()?;
|
||||
|
||||
task.status = Status::Succeeded;
|
||||
task.details = Some(Details::IndexInfo { primary_key });
|
||||
|
||||
// if the update processed successfully, we're going to store the new
|
||||
// stats of the index. Since the tasks have already been processed and
|
||||
// this is a non-critical operation. If it fails, we should not fail
|
||||
// the entire batch.
|
||||
let res = || -> Result<()> {
|
||||
let mut wtxn = self.env.write_txn()?;
|
||||
let index_rtxn = index.read_txn()?;
|
||||
let stats = crate::index_mapper::IndexStats::new(&index, &index_rtxn)?;
|
||||
self.index_mapper.store_stats_of(&mut wtxn, &index_uid, &stats)?;
|
||||
wtxn.commit()?;
|
||||
Ok(())
|
||||
}();
|
||||
|
||||
match res {
|
||||
Ok(_) => (),
|
||||
Err(e) => error!("Could not write the stats of the index {}", e),
|
||||
}
|
||||
|
||||
Ok(vec![task])
|
||||
}
|
||||
Batch::IndexDeletion { index_uid, index_has_been_created, mut tasks } => {
|
||||
|
||||
@@ -4,10 +4,11 @@ use std::time::Duration;
|
||||
use std::{fs, thread};
|
||||
|
||||
use log::error;
|
||||
use meilisearch_types::heed::types::Str;
|
||||
use meilisearch_types::heed::types::{SerdeJson, Str};
|
||||
use meilisearch_types::heed::{Database, Env, RoTxn, RwTxn};
|
||||
use meilisearch_types::milli::update::IndexerConfig;
|
||||
use meilisearch_types::milli::Index;
|
||||
use meilisearch_types::milli::{FieldDistribution, Index};
|
||||
use serde::{Deserialize, Serialize};
|
||||
use time::OffsetDateTime;
|
||||
use uuid::Uuid;
|
||||
|
||||
@@ -19,6 +20,7 @@ use crate::{Error, Result};
|
||||
mod index_map;
|
||||
|
||||
const INDEX_MAPPING: &str = "index-mapping";
|
||||
const INDEX_STATS: &str = "index-stats";
|
||||
|
||||
/// Structure managing meilisearch's indexes.
|
||||
///
|
||||
@@ -52,6 +54,11 @@ pub struct IndexMapper {
|
||||
|
||||
/// Map an index name with an index uuid currently available on disk.
|
||||
pub(crate) index_mapping: Database<Str, UuidCodec>,
|
||||
/// Map an index UUID with the cached stats associated to the index.
|
||||
///
|
||||
/// Using an UUID forces to use the index_mapping table to recover the index behind a name, ensuring
|
||||
/// consistency wrt index swapping.
|
||||
pub(crate) index_stats: Database<UuidCodec, SerdeJson<IndexStats>>,
|
||||
|
||||
/// Path to the folder where the LMDB environments of each index are.
|
||||
base_path: PathBuf,
|
||||
@@ -76,6 +83,39 @@ pub enum IndexStatus {
|
||||
Available(Index),
|
||||
}
|
||||
|
||||
/// The statistics that can be computed from an `Index` object.
|
||||
#[derive(Serialize, Deserialize, Debug)]
|
||||
pub struct IndexStats {
|
||||
/// Number of documents in the index.
|
||||
pub number_of_documents: u64,
|
||||
/// Size of the index' DB, in bytes.
|
||||
pub database_size: u64,
|
||||
/// Association of every field name with the number of times it occurs in the documents.
|
||||
pub field_distribution: FieldDistribution,
|
||||
/// Creation date of the index.
|
||||
pub created_at: OffsetDateTime,
|
||||
/// Date of the last update of the index.
|
||||
pub updated_at: OffsetDateTime,
|
||||
}
|
||||
|
||||
impl IndexStats {
|
||||
/// Compute the stats of an index
|
||||
///
|
||||
/// # Parameters
|
||||
///
|
||||
/// - rtxn: a RO transaction for the index, obtained from `Index::read_txn()`.
|
||||
pub fn new(index: &Index, rtxn: &RoTxn) -> Result<Self> {
|
||||
let database_size = index.on_disk_size()?;
|
||||
Ok(IndexStats {
|
||||
number_of_documents: index.number_of_documents(rtxn)?,
|
||||
database_size,
|
||||
field_distribution: index.field_distribution(rtxn)?,
|
||||
created_at: index.created_at(rtxn)?,
|
||||
updated_at: index.updated_at(rtxn)?,
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
impl IndexMapper {
|
||||
pub fn new(
|
||||
env: &Env,
|
||||
@@ -88,6 +128,7 @@ impl IndexMapper {
|
||||
Ok(Self {
|
||||
index_map: Arc::new(RwLock::new(IndexMap::new(index_count))),
|
||||
index_mapping: env.create_database(Some(INDEX_MAPPING))?,
|
||||
index_stats: env.create_database(Some(INDEX_STATS))?,
|
||||
base_path,
|
||||
index_base_map_size,
|
||||
index_growth_amount,
|
||||
@@ -140,6 +181,9 @@ impl IndexMapper {
|
||||
.get(&wtxn, name)?
|
||||
.ok_or_else(|| Error::IndexNotFound(name.to_string()))?;
|
||||
|
||||
// Not an error if the index had no stats in cache.
|
||||
self.index_stats.delete(&mut wtxn, &uuid)?;
|
||||
|
||||
// Once we retrieved the UUID of the index we remove it from the mapping table.
|
||||
assert!(self.index_mapping.delete(&mut wtxn, name)?);
|
||||
|
||||
@@ -360,6 +404,45 @@ impl IndexMapper {
|
||||
Ok(())
|
||||
}
|
||||
|
||||
/// The stats of an index.
|
||||
///
|
||||
/// If available in the cache, they are directly returned.
|
||||
/// Otherwise, the `Index` is opened to compute the stats on the fly (the result is not cached).
|
||||
/// The stats for an index are cached after each `Index` update.
|
||||
pub fn stats_of(&self, rtxn: &RoTxn, index_uid: &str) -> Result<IndexStats> {
|
||||
let uuid = self
|
||||
.index_mapping
|
||||
.get(rtxn, index_uid)?
|
||||
.ok_or_else(|| Error::IndexNotFound(index_uid.to_string()))?;
|
||||
|
||||
match self.index_stats.get(rtxn, &uuid)? {
|
||||
Some(stats) => Ok(stats),
|
||||
None => {
|
||||
let index = self.index(rtxn, index_uid)?;
|
||||
let index_rtxn = index.read_txn()?;
|
||||
IndexStats::new(&index, &index_rtxn)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/// Stores the new stats for an index.
|
||||
///
|
||||
/// Expected usage is to compute the stats the index using `IndexStats::new`, the pass it to this function.
|
||||
pub fn store_stats_of(
|
||||
&self,
|
||||
wtxn: &mut RwTxn,
|
||||
index_uid: &str,
|
||||
stats: &IndexStats,
|
||||
) -> Result<()> {
|
||||
let uuid = self
|
||||
.index_mapping
|
||||
.get(wtxn, index_uid)?
|
||||
.ok_or_else(|| Error::IndexNotFound(index_uid.to_string()))?;
|
||||
|
||||
self.index_stats.put(wtxn, &uuid, stats)?;
|
||||
Ok(())
|
||||
}
|
||||
|
||||
pub fn index_exists(&self, rtxn: &RoTxn, name: &str) -> Result<bool> {
|
||||
Ok(self.index_mapping.get(rtxn, name)?.is_some())
|
||||
}
|
||||
|
||||
@@ -254,6 +254,16 @@ pub fn snapshot_canceled_by(
|
||||
snap
|
||||
}
|
||||
pub fn snapshot_index_mapper(rtxn: &RoTxn, mapper: &IndexMapper) -> String {
|
||||
let mut s = String::new();
|
||||
let names = mapper.index_names(rtxn).unwrap();
|
||||
format!("{names:?}")
|
||||
|
||||
for name in names {
|
||||
let stats = mapper.stats_of(rtxn, &name).unwrap();
|
||||
s.push_str(&format!(
|
||||
"{name}: {{ number_of_documents: {}, field_distribution: {:?} }}\n",
|
||||
stats.number_of_documents, stats.field_distribution
|
||||
));
|
||||
}
|
||||
|
||||
s
|
||||
}
|
||||
|
||||
@@ -45,10 +45,9 @@ use file_store::FileStore;
|
||||
use meilisearch_types::error::ResponseError;
|
||||
use meilisearch_types::heed::types::{OwnedType, SerdeBincode, SerdeJson, Str};
|
||||
use meilisearch_types::heed::{self, Database, Env, RoTxn, RwTxn};
|
||||
use meilisearch_types::milli;
|
||||
use meilisearch_types::milli::documents::DocumentsBatchBuilder;
|
||||
use meilisearch_types::milli::update::IndexerConfig;
|
||||
use meilisearch_types::milli::{CboRoaringBitmapCodec, Index, RoaringBitmapCodec, BEU32};
|
||||
use meilisearch_types::milli::{self, CboRoaringBitmapCodec, Index, RoaringBitmapCodec, BEU32};
|
||||
use meilisearch_types::tasks::{Kind, KindWithContent, Status, Task};
|
||||
use roaring::RoaringBitmap;
|
||||
use synchronoise::SignalEvent;
|
||||
@@ -430,6 +429,13 @@ impl IndexScheduler {
|
||||
Ok(this)
|
||||
}
|
||||
|
||||
/// Return `Ok(())` if the index scheduler is able to access one of its database.
|
||||
pub fn health(&self) -> Result<()> {
|
||||
let rtxn = self.env.read_txn()?;
|
||||
self.all_tasks.first(&rtxn)?;
|
||||
Ok(())
|
||||
}
|
||||
|
||||
fn index_budget(
|
||||
tasks_path: &Path,
|
||||
base_map_size: usize,
|
||||
@@ -567,7 +573,7 @@ impl IndexScheduler {
|
||||
}
|
||||
|
||||
/// Return the name of all indexes without opening them.
|
||||
pub fn index_names(self) -> Result<Vec<String>> {
|
||||
pub fn index_names(&self) -> Result<Vec<String>> {
|
||||
let rtxn = self.env.read_txn()?;
|
||||
self.index_mapper.index_names(&rtxn)
|
||||
}
|
||||
@@ -1080,6 +1086,14 @@ impl IndexScheduler {
|
||||
Ok(TickOutcome::TickAgain(processed_tasks))
|
||||
}
|
||||
|
||||
pub fn index_stats(&self, index_uid: &str) -> Result<IndexStats> {
|
||||
let is_indexing = self.is_index_processing(index_uid)?;
|
||||
let rtxn = self.read_txn()?;
|
||||
let index_stats = self.index_mapper.stats_of(&rtxn, index_uid)?;
|
||||
|
||||
Ok(IndexStats { is_indexing, inner_stats: index_stats })
|
||||
}
|
||||
|
||||
pub(crate) fn delete_persisted_task_data(&self, task: &Task) -> Result<()> {
|
||||
match task.content_uuid() {
|
||||
Some(content_file) => self.delete_update_file(content_file),
|
||||
@@ -1237,6 +1251,34 @@ impl<'a> Dump<'a> {
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
utils::insert_task_datetime(
|
||||
&mut self.wtxn,
|
||||
self.index_scheduler.enqueued_at,
|
||||
task.enqueued_at,
|
||||
task.uid,
|
||||
)?;
|
||||
|
||||
// we can't override the started_at & finished_at, so we must only set it if the tasks is finished and won't change
|
||||
if matches!(task.status, Status::Succeeded | Status::Failed | Status::Canceled) {
|
||||
if let Some(started_at) = task.started_at {
|
||||
utils::insert_task_datetime(
|
||||
&mut self.wtxn,
|
||||
self.index_scheduler.started_at,
|
||||
started_at,
|
||||
task.uid,
|
||||
)?;
|
||||
}
|
||||
if let Some(finished_at) = task.finished_at {
|
||||
utils::insert_task_datetime(
|
||||
&mut self.wtxn,
|
||||
self.index_scheduler.finished_at,
|
||||
finished_at,
|
||||
task.uid,
|
||||
)?;
|
||||
}
|
||||
}
|
||||
|
||||
self.statuses.entry(task.status).or_insert(RoaringBitmap::new()).insert(task.uid);
|
||||
self.kinds.entry(task.kind.as_kind()).or_insert(RoaringBitmap::new()).insert(task.uid);
|
||||
|
||||
@@ -1282,6 +1324,17 @@ struct IndexBudget {
|
||||
task_db_size: usize,
|
||||
}
|
||||
|
||||
/// The statistics that can be computed from an `Index` object and the scheduler.
|
||||
///
|
||||
/// Compared with `index_mapper::IndexStats`, it adds the scheduling status.
|
||||
#[derive(Debug)]
|
||||
pub struct IndexStats {
|
||||
/// Whether this index is currently performing indexation, according to the scheduler.
|
||||
pub is_indexing: bool,
|
||||
/// Internal stats computed from the index.
|
||||
pub inner_stats: index_mapper::IndexStats,
|
||||
}
|
||||
|
||||
#[cfg(test)]
|
||||
mod tests {
|
||||
use std::io::{BufWriter, Seek, Write};
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
---
|
||||
source: index-scheduler/src/lib.rs
|
||||
assertion_line: 1755
|
||||
---
|
||||
### Autobatching Enabled = true
|
||||
### Processing Tasks:
|
||||
@@ -23,7 +22,7 @@ canceled [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
1 [0,]
|
||||
|
||||
@@ -20,7 +20,7 @@ enqueued [0,1,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,9 @@ catto [0,]
|
||||
wolfo [2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["beavero", "catto"]
|
||||
beavero: { number_of_documents: 0, field_distribution: {} }
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
---
|
||||
source: index-scheduler/src/lib.rs
|
||||
assertion_line: 1859
|
||||
---
|
||||
### Autobatching Enabled = true
|
||||
### Processing Tasks:
|
||||
@@ -27,7 +26,9 @@ catto [0,]
|
||||
wolfo [2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["beavero", "catto"]
|
||||
beavero: { number_of_documents: 0, field_distribution: {} }
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
3 [1,2,]
|
||||
|
||||
@@ -23,7 +23,8 @@ catto [0,]
|
||||
wolfo [2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,8 @@ catto [0,]
|
||||
wolfo [2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,8 @@ enqueued [0,1,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -1,6 +1,5 @@
|
||||
---
|
||||
source: index-scheduler/src/lib.rs
|
||||
assertion_line: 1818
|
||||
---
|
||||
### Autobatching Enabled = true
|
||||
### Processing Tasks:
|
||||
@@ -23,7 +22,8 @@ canceled [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
1 [0,]
|
||||
|
||||
@@ -20,7 +20,7 @@ enqueued [0,1,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -21,7 +21,8 @@ succeeded [0,1,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
1 []
|
||||
|
||||
@@ -19,7 +19,8 @@ succeeded [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -27,7 +27,10 @@ doggos [0,3,]
|
||||
girafos [2,5,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["cattos", "doggos", "girafos"]
|
||||
cattos: { number_of_documents: 0, field_distribution: {} }
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
girafos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -19,7 +19,8 @@ succeeded [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 1, field_distribution: {"doggo": 1, "id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -21,7 +21,8 @@ succeeded [0,1,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 1, field_distribution: {"doggo": 1, "id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ enqueued [0,1,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ succeeded [0,]
|
||||
doggos [0,1,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,7 @@ succeeded [0,1,2,]
|
||||
doggos [0,1,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ enqueued [0,1,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ enqueued [0,1,2,]
|
||||
doggos [0,1,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ enqueued [0,1,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -21,7 +21,7 @@ succeeded [0,1,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -21,7 +21,7 @@ failed [0,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,8 @@ failed [0,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 3, field_distribution: {"catto": 1, "doggo": 2, "id": 3} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ enqueued [0,1,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -19,7 +19,7 @@ failed [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -19,7 +19,7 @@ failed [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,8 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 1, field_distribution: {"doggo": 1, "id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,8 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 1, field_distribution: {"doggo": 1, "id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -19,7 +19,8 @@ succeeded [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 1, field_distribution: {"doggo": 1, "id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
index_a [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
index_a [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ index_a [0,]
|
||||
index_b [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ index_a [0,2,]
|
||||
index_b [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -19,7 +19,7 @@ failed [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
catto [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ cattos [1,]
|
||||
doggos [0,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,9 @@ cattos [1,]
|
||||
doggos [0,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["cattos", "doggos"]
|
||||
cattos: { number_of_documents: 0, field_distribution: {} }
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ cattos [1,]
|
||||
doggos [0,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["cattos"]
|
||||
cattos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ cattos [1,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ cattos [1,]
|
||||
doggos [0,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ succeeded [0,]
|
||||
doggos [0,1,2,3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ succeeded [0,1,2,3,]
|
||||
doggos [0,1,2,3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggos [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ enqueued [0,1,2,3,]
|
||||
doggos [0,1,2,3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ enqueued [0,1,]
|
||||
doggos [0,1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -21,7 +21,7 @@ enqueued [0,1,2,]
|
||||
doggos [0,1,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ succeeded [0,1,]
|
||||
doggos [0,1,2,3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ succeeded [0,1,2,]
|
||||
doggos [0,1,2,3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["doggos"]
|
||||
doggos: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -26,7 +26,8 @@ catto [0,2,]
|
||||
doggo [1,2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
3 [1,2,]
|
||||
|
||||
@@ -23,7 +23,10 @@ doggo [0,]
|
||||
whalo [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto", "doggo", "whalo"]
|
||||
catto: { number_of_documents: 0, field_distribution: {} }
|
||||
doggo: { number_of_documents: 0, field_distribution: {} }
|
||||
whalo: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -18,7 +18,7 @@ enqueued [0,]
|
||||
doggo [0,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ doggo [0,]
|
||||
whalo [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ doggo [0,]
|
||||
whalo [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -24,7 +24,9 @@ doggo [1,]
|
||||
whalo [2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto", "doggo"]
|
||||
catto: { number_of_documents: 0, field_distribution: {} }
|
||||
doggo: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ doggo [1,]
|
||||
whalo [2,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -24,7 +24,7 @@ doggo [1,2,]
|
||||
whalo [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,7 @@ catto [0,1,2,]
|
||||
doggo [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,8 @@ c [2,]
|
||||
d [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,9 @@ c [2,]
|
||||
d [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,10 @@ c [2,]
|
||||
d [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,11 @@ c [2,]
|
||||
d [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -28,7 +28,11 @@ c [3,4,5,]
|
||||
d [2,4,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -27,7 +27,11 @@ c [2,4,]
|
||||
d [3,4,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -28,7 +28,11 @@ c [1,4,5,]
|
||||
d [2,4,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -29,7 +29,11 @@ c [1,4,5,]
|
||||
d [2,4,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -28,7 +28,11 @@ c [2,4,5,]
|
||||
d [3,4,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,11 @@ c [2,]
|
||||
d [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -30,7 +30,11 @@ e [4,]
|
||||
f [4,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -25,7 +25,11 @@ c [2,]
|
||||
d [3,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["a", "b", "c", "d"]
|
||||
a: { number_of_documents: 0, field_distribution: {} }
|
||||
b: { number_of_documents: 0, field_distribution: {} }
|
||||
c: { number_of_documents: 0, field_distribution: {} }
|
||||
d: { number_of_documents: 0, field_distribution: {} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -20,7 +20,7 @@ catto [0,]
|
||||
doggo [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
[]
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -21,7 +21,8 @@ catto [0,]
|
||||
doggo [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -22,7 +22,8 @@ succeeded [2,3,]
|
||||
doggo [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
@@ -23,7 +23,8 @@ catto [0,]
|
||||
doggo [1,]
|
||||
----------------------------------------------------------------------
|
||||
### Index Mapper:
|
||||
["catto"]
|
||||
catto: { number_of_documents: 1, field_distribution: {"id": 1} }
|
||||
|
||||
----------------------------------------------------------------------
|
||||
### Canceled By:
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user