Tamo
36281a653f
write all the simple tests
2021-10-21 12:40:11 +02:00
Tamo
661bc21af5
Fix the filter parser
...
And add a bunch of tests on the filter::from_array
2021-10-21 11:45:03 +02:00
bors[bot]
b6af84eb77
Merge #394
...
394: Added search_geo benchmark in cron job r=irevoire a=fumblehool
fixes : #392
`search_geo` cron will run every friday at 18:30
Co-authored-by: Damanpreet Singh <daman.4880@gmail.com >
2021-10-18 14:33:32 +00:00
bors[bot]
7906461c14
Merge #396
...
396: Fix indexing benchmark GH actions upload filename r=irevoire a=fumblehool
fixes : #393
Co-authored-by: Damanpreet Singh <daman.4880@gmail.com >
2021-10-18 13:34:10 +00:00
Damanpreet Singh
2e4604b0b9
fixed filename for search_* crons
2021-10-18 18:48:38 +05:30
Damanpreet Singh
4c34164d2e
fixed filename for search_geo cron
2021-10-18 18:43:36 +05:30
bors[bot]
9df4f3aaad
Merge #397
...
397: Fix typo in repo r=curquiza a=saintmalik
Fix the single typo found in this repo
Co-authored-by: SaintMalik <37118134+saintmalik@users.noreply.github.com >
2021-10-18 11:59:48 +00:00
bors[bot]
513d3178c6
Merge #398
...
398: Update version for the next release (v0.18.2) r=irevoire a=curquiza
Breaking because of https://github.com/meilisearch/milli/pull/358
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com >
2021-10-18 11:47:26 +00:00
Clémentine Urquizar
2209acbfe2
Update version for the next release (v0.18.2)
2021-10-18 13:45:48 +02:00
SaintMalik
70121e3c6b
fix typo in repo
2021-10-18 04:00:19 +01:00
bors[bot]
59cc59e93e
Merge #358
...
358: Replacing pest with nom r=Kerollmops a=CNLHC
Co-authored-by: 刘瀚骋 <cn_lhc@qq.com >
2021-10-16 20:44:38 +00:00
Damanpreet Singh
493d9b98f5
fix indexing benchmark GH actions upload filename
2021-10-16 21:52:36 +05:30
Damanpreet Singh
efaef4f748
Added search_geo benchmark in cron job
2021-10-16 21:41:45 +05:30
刘瀚骋
7666e4f34a
follow the suggestions
2021-10-14 21:37:59 +08:00
刘瀚骋
2ea2f7570c
use nightly cargo to format the code
2021-10-14 16:46:13 +08:00
刘瀚骋
e750465e15
check logic for geolocation.
2021-10-14 16:12:00 +08:00
bors[bot]
aa5e099718
Merge #390
...
390: Add helper methods on the settings r=Kerollmops a=irevoire
This would be a good addition to look at the content of a setting without consuming it.
It’s useful for analytics.
Co-authored-by: Irevoire <tamo@meilisearch.com >
2021-10-13 20:36:30 +00:00
bors[bot]
c7db4176f3
Merge #384
...
384: Replace memmap with memmap2 r=Kerollmops a=palfrey
[memmap is unmaintained](https://rustsec.org/advisories/RUSTSEC-2020-0077.html ) and needs replacing. memmap2 is a drop-in replacement fork that's well maintained. Note that the version numbers got reset on fork, hence the lower values.
Co-authored-by: Tom Parker-Shemilt <palfrey@tevp.net >
2021-10-13 13:47:23 +00:00
Irevoire
a3e7c468cd
add helper methods on the settings
2021-10-13 13:05:07 +02:00
刘瀚骋
cd359cd96e
WIP: extract the error trait bound to new trait.
2021-10-13 18:04:15 +08:00
刘瀚骋
5de5dd80a3
WIP: remove '_nom' suffix/redundant error enum/...
2021-10-13 11:06:15 +08:00
刘瀚骋
2c65781d91
format
2021-10-12 22:20:22 +08:00
bors[bot]
6e3b869e6a
Merge #388
...
388: fix primary key inference r=MarinPostma a=MarinPostma
The primary key is was infered from a hashtable index of the field. For this reason the order in which the fields were interated upon was not deterministic, and the primary key was chosed ffrom the first field containing "id".
This fix sorts the the index by field_id when infering the primary key.
Co-authored-by: mpostma <postma.marin@protonmail.com >
2021-10-12 09:25:16 +00:00
mpostma
86ead92ed5
infer primary key on sorted fields
2021-10-12 11:15:11 +02:00
mpostma
9a266a531b
test correct primary key inference
2021-10-12 11:08:53 +02:00
bors[bot]
3f7f24b90e
Merge #368
...
368: Remove limit of 1000 position per attribute r=irevoire a=ManyTheFish
Instead of using an arbitrary limit we encode the absolute position in a u32
using one strong u16 for the field id and a weak u16 for the relative position in the attribute.
- [x] check database size difference
below is the database size difference for each dataset:
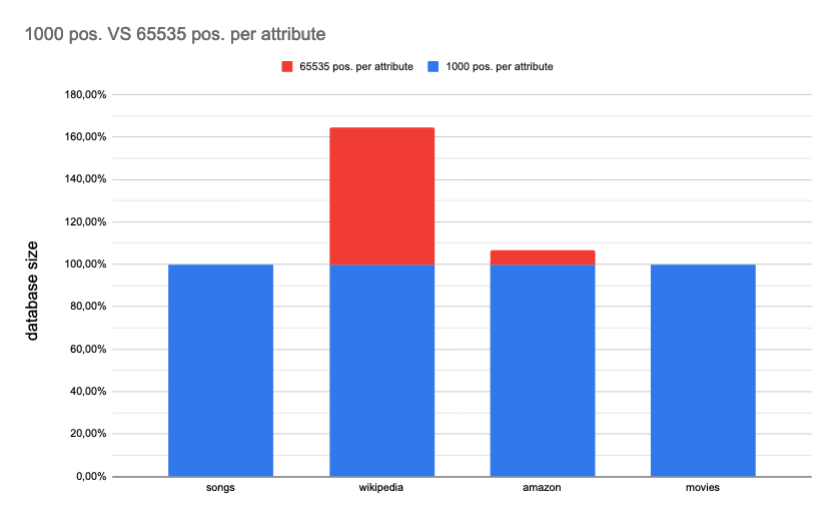
- [ ] check search time on big dataset
Related to [product#202](https://github.com/meilisearch/product/issues/202 )
Co-authored-by: many <maxime@meilisearch.com >
2021-10-12 08:30:33 +00:00
many
c5a6075484
Make max_position_per_attributes changable
2021-10-12 10:10:50 +02:00
many
360c5ff3df
Remove limit of 1000 position per attribute
...
Instead of using an arbitrary limit we encode the absolute position in a u32
using one strong u16 for the field id and a weak u16 for the relative position in the attribute.
2021-10-12 10:10:50 +02:00
刘瀚骋
d323e35001
add a test case
2021-10-12 13:30:40 +08:00
刘瀚骋
70f576d5d3
error handling
2021-10-12 13:30:40 +08:00
刘瀚骋
28f9be8d7c
support syntax
2021-10-12 13:30:40 +08:00
刘瀚骋
469d92c569
tweak error handling
2021-10-12 13:30:40 +08:00
刘瀚骋
7a90a101ee
reorganize parser logic
2021-10-12 13:30:40 +08:00
刘瀚骋
f7796edc7e
remove everything about pest
2021-10-12 13:30:40 +08:00
刘瀚骋
ac1df9d9d7
fix typo and remove pest
2021-10-12 13:30:40 +08:00
刘瀚骋
50ad750ec1
enhance error handling
2021-10-12 13:30:40 +08:00
刘瀚骋
8748df2ca4
draft without error handling
2021-10-12 13:30:40 +08:00
bors[bot]
8f6b6c9042
Merge #385
...
385: Fix the wiki indexing benchmark r=ManyTheFish a=irevoire
Co-authored-by: Tamo <tamo@meilisearch.com >
2021-10-11 15:12:24 +00:00
bors[bot]
07fb6d64e5
Merge #386
...
386: fix obkv document r=curquiza a=MarinPostma
When serializing a document, the serializer resolved the field_id of the current field and immediately added it to the obkv document under construction. The issue with that is that obkv expects the fields to be inserted in order, and when a document with out of order fields was added, obkv failed to insert the field.
The current fix first resolves each field_id, and adds all the fields to a temporary `BTreeMap`, until `end` is called on the map serializer, where all the fields are added to the obkv at once, and in order.
Co-authored-by: mpostma <postma.marin@protonmail.com >
2021-10-11 13:45:04 +00:00
bors[bot]
e45c846af5
Merge #387
...
387: Update version for the next release (v0.17.2) r=Kerollmops a=curquiza
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com >
2021-10-11 13:21:47 +00:00
Clémentine Urquizar
dd56e82dba
Update version for the next release (v0.17.2)
2021-10-11 15:20:35 +02:00
mpostma
99889a0ed0
add obkv document serialization test
2021-10-11 15:13:17 +02:00
mpostma
799f3d43c8
fix serialization to obkv format
2021-10-11 15:04:47 +02:00
Tamo
ed7fd855af
fix the wiki indexing benchmark
2021-10-11 14:26:36 +02:00
Tom Parker-Shemilt
2dfe24f067
memmap -> memmap2
2021-10-10 22:47:12 +01:00
bors[bot]
a2743baaa3
Merge #383
...
383: Add check on latitude and longitude r=irevoire a=irevoire
Latitudes are not supposed to go beyond 90 degrees or below -90.
The same goes for longitudes with 180 or -180.
This was badly implemented in the filters, and was not implemented for the `AscDesc` rules.
Co-authored-by: Tamo <tamo@meilisearch.com >
Co-authored-by: Irevoire <tamo@meilisearch.com >
2021-10-08 10:15:25 +00:00
Irevoire
b65aa7b5ac
Apply suggestions from code review
...
Co-authored-by: Clément Renault <clement@meilisearch.com >
2021-10-07 17:51:52 +02:00
Tamo
11dfe38761
Update the check on the latitude and longitude
...
Latitude are not supposed to go beyound 90 degrees or below -90.
The same goes for longitude with 180 or -180.
This was badly implemented in the filters, and was not implemented for the AscDesc rules.
2021-10-07 16:10:43 +02:00
bors[bot]
dde1da1c0e
Merge #382
...
382: Refactor attribute criterion r=Kerollmops a=ManyTheFish
### Re-implement set based algorithm for attribute criterion
#### Levels
Instead of doing level iteration and digging in the interesting level, we only iterate over the lowest level.
#### crossword iteration VS minimal position iteration
Instead of crossing word position in order to iterate strictly over the position that gives the best rank in good order; we iterate word by word starting with the word that increases the rank the little as possible.
This new method is a bit less precise but way simpler.
### Simplify word-level-position database
We don't use levels anymore in the attribute criterion, and so we removed the level complexity of the database making a word-position-docids database.
### Benchmarks on search on big datasets
#### songs main VS refactor-attribute-criterion
```diff
group search_songsmain_31c18f09 search_songsrefactor-attribute-criterion_1bd15d84
----- ------------------------- -------------------------------------------------
- smol-songs.csv: basic filter: <=/Notstandskomitee 1.00 84.8±0.58µs ? ?/sec 1.09 92.2±8.98µs ? ?/sec
+ smol-songs.csv: basic filter: TO/Notstandskomitee 1.18 98.0±6.30µs ? ?/sec 1.00 83.2±0.97µs ? ?/sec
+ smol-songs.csv: basic with quote/"david" "bowie" 114.68 76.0±0.20ms ? ?/sec 1.00 662.5±5.03µs ? ?/sec
- smol-songs.csv: basic with quote/"john" 1.00 197.4±1.06µs ? ?/sec 1.05 208.1±1.53µs ? ?/sec
+ smol-songs.csv: basic with quote/"michael" "jackson" 2.75 2.0±0.01ms ? ?/sec 1.00 738.9±3.91µs ? ?/sec
+ smol-songs.csv: basic without quote/david bowie 297.42 1499.3±0.86ms ? ?/sec 1.00 5.0±0.02ms ? ?/sec
+ smol-songs.csv: basic without quote/michael jackson 2.55 8.9±0.02ms ? ?/sec 1.00 3.5±0.01ms ? ?/sec
+ smol-songs.csv: big filter/john 1.08 473.6±2.25µs ? ?/sec 1.00 438.1±2.59µs ? ?/sec
- smol-songs.csv: prefix search/a 1.00 446.9±1.81µs ? ?/sec 1.79 800.5±4.45µs ? ?/sec
- smol-songs.csv: prefix search/b 1.00 398.5±2.74µs ? ?/sec 1.81 723.1±5.46µs ? ?/sec
- smol-songs.csv: prefix search/i 1.00 486.3±1.99µs ? ?/sec 1.69 823.6±9.42µs ? ?/sec
- smol-songs.csv: prefix search/s 1.00 229.6±3.29µs ? ?/sec 2.59 594.4±2.22µs ? ?/sec
- smol-songs.csv: prefix search/x 1.00 150.2±0.76µs ? ?/sec 1.11 166.0±0.87µs ? ?/sec
```
On songs, the new algorithm gives a big improvement on slow queries, and is slower on one char prefix search (fast queries <1ms).
#### wiki main VS refactor-attribute-criterion
```diff
group search_wikimain_31c18f09 search_wikirefactor-attribute-criterion_1bd15d84
----- ------------------------ ------------------------------------------------
- smol-wiki-articles.csv: basic with quote/"rock" "and" "roll" 1.00 3.2±0.01ms ? ?/sec 1.15 3.7±0.01ms ? ?/sec
- smol-wiki-articles.csv: basic without quote/film 1.00 351.5±2.47µs ? ?/sec 1.13 396.8±1.63µs ? ?/sec
+ smol-wiki-articles.csv: basic without quote/rock and roll 1.10 9.4±0.02ms ? ?/sec 1.00 8.6±0.04ms ? ?/sec
- smol-wiki-articles.csv: basic without quote/spain 1.00 446.0±3.23µs ? ?/sec 1.11 496.6±7.75µs ? ?/sec
- smol-wiki-articles.csv: prefix search/c 1.00 115.6±0.61µs ? ?/sec 2.22 256.7±1.24µs ? ?/sec
- smol-wiki-articles.csv: prefix search/g 1.00 189.7±2.03µs ? ?/sec 1.57 297.0±1.35µs ? ?/sec
- smol-wiki-articles.csv: prefix search/j 1.00 209.2±1.11µs ? ?/sec 1.40 293.0±2.09µs ? ?/sec
- smol-wiki-articles.csv: prefix search/q 1.00 79.0±0.44µs ? ?/sec 1.10 87.2±0.69µs ? ?/sec
- smol-wiki-articles.csv: prefix search/t 1.00 270.1±1.15µs ? ?/sec 1.55 419.9±5.16µs ? ?/sec
- smol-wiki-articles.csv: prefix search/x 1.00 244.9±1.33µs ? ?/sec 1.07 260.9±1.95µs ? ?/sec
- smol-wiki-articles.csv: words/Abraham machin 1.00 8.1±0.03ms ? ?/sec 1.17 9.4±0.02ms ? ?/sec
- smol-wiki-articles.csv: words/Idaho Bellevue pizza 1.00 19.3±0.07ms ? ?/sec 1.07 20.6±0.05ms ? ?/sec
```
On wiki we have some regressions `+17%` and `+15%` on request `>1ms`.
Co-authored-by: many <maxime@meilisearch.com >
2021-10-06 09:19:33 +00:00
many
085bc6440c
Apply PR comments
2021-10-06 11:12:26 +02:00
{kind=link}