mirror of
https://github.com/meilisearch/meilisearch.git
synced 2025-07-20 13:30:38 +00:00
Compare commits
48 Commits
release-v1
...
prototype-
| Author | SHA1 | Date | |
|---|---|---|---|
| 728742e2b8 | |||
| b4c01581cd | |||
| 67fd3b08ef | |||
| 1690aec7f1 | |||
| f267bed352 | |||
| 597d57bf1d | |||
| 01ac8344ad | |||
| 3508ba2f20 | |||
| 1e6fe71a67 | |||
| 0fba08cd72 | |||
| 189d4c3b70 | |||
| 2fff6f7f23 | |||
| fddfb37f1f | |||
| 52b4090286 | |||
| 3cabfb448b | |||
| 77cf5b3787 | |||
| 3acc5bbb15 | |||
| 114436926f | |||
| 0f7904fb38 | |||
| 590b1d8fb7 | |||
| be9741eb8a | |||
| 0177d66149 | |||
| 1861c69964 | |||
| cb2b5eb38e | |||
| 53aa0a1b54 | |||
| 7871d12025 | |||
| 3fb67f94f7 | |||
| cf5145b542 | |||
| 31bb61ba99 | |||
| e7994cdeb3 | |||
| 70c906d4b4 | |||
| 0f33a65468 | |||
| 7c9a8b1e1b | |||
| f45daf8031 | |||
| 7935bef4cd | |||
| eddefb0e0f | |||
| c5f22be6e1 | |||
| febc8d1b52 | |||
| df3986cd83 | |||
| 34ed6518ae | |||
| 22219fd88f | |||
| a9e17ab8c6 | |||
| 2dd948a4a1 | |||
| 76cf1bff87 | |||
| c0d8eb295d | |||
| bcd3f6054a | |||
| 3a0314f9de | |||
| fa4d8b8348 |
{kind=link}
3
.github/ISSUE_TEMPLATE/bug_report.md
vendored
3
.github/ISSUE_TEMPLATE/bug_report.md
vendored
@ -23,7 +23,8 @@ A clear and concise description of what you expected to happen.
|
||||
**Screenshots**
|
||||
If applicable, add screenshots to help explain your problem.
|
||||
|
||||
**Meilisearch version:** [e.g. v0.20.0]
|
||||
**Meilisearch version:**
|
||||
[e.g. v0.20.0]
|
||||
|
||||
**Additional context**
|
||||
Additional information that may be relevant to the issue.
|
||||
|
||||
34
.github/ISSUE_TEMPLATE/sprint_issue.md
vendored
Normal file
34
.github/ISSUE_TEMPLATE/sprint_issue.md
vendored
Normal file
@ -0,0 +1,34 @@
|
||||
---
|
||||
name: New sprint issue
|
||||
about: ⚠️ Should only be used by the engine team ⚠️
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
Related product team resources: [roadmap card]() (_internal only_) and [PRD]() (_internal only_)
|
||||
Related product discussion:
|
||||
Related spec: WIP
|
||||
|
||||
## Motivation
|
||||
|
||||
<!---Copy/paste the information in the roadmap resources or briefly detail the product motivation. Ask product team if any hesitation.-->
|
||||
|
||||
## Usage
|
||||
|
||||
<!---Write a quick description of the usage if the usage has already been defined-->
|
||||
|
||||
Refer to the final spec to know the details and the final decisions about the usage.
|
||||
|
||||
## TODO
|
||||
|
||||
<!---Feel free to adapt this list with more technical/product steps-->
|
||||
|
||||
- [ ] Release a prototype
|
||||
- [ ] If prototype validated, merge changes into `main`
|
||||
- [ ] Update the spec
|
||||
|
||||
## Impacted teams
|
||||
|
||||
<!---Ping the related teams. Ask for the engine manager if any hesitation-->
|
||||
@ -1,4 +1,4 @@
|
||||
name: Benchmarks
|
||||
name: Benchmarks (manual)
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
@ -1,4 +1,4 @@
|
||||
name: Benchmarks indexing (push)
|
||||
name: Benchmarks of indexing (push)
|
||||
|
||||
on:
|
||||
push:
|
||||
@ -1,4 +1,4 @@
|
||||
name: Benchmarks search geo (push)
|
||||
name: Benchmarks of search for geo (push)
|
||||
|
||||
on:
|
||||
push:
|
||||
@ -1,4 +1,4 @@
|
||||
name: Benchmarks search songs (push)
|
||||
name: Benchmarks of search for songs (push)
|
||||
|
||||
on:
|
||||
push:
|
||||
@ -1,4 +1,4 @@
|
||||
name: Benchmarks search wikipedia articles (push)
|
||||
name: Benchmarks of search for Wikipedia articles (push)
|
||||
|
||||
on:
|
||||
push:
|
||||
28
.github/workflows/create-issue-dependencies.yml
vendored
28
.github/workflows/create-issue-dependencies.yml
vendored
@ -1,28 +0,0 @@
|
||||
name: Create issue to upgrade dependencies
|
||||
on:
|
||||
schedule:
|
||||
# Run the first of the month, every 3 month
|
||||
- cron: '0 0 1 */3 *'
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
create-issue:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Create an issue
|
||||
uses: actions-ecosystem/action-create-issue@v1
|
||||
with:
|
||||
github_token: ${{ secrets.MEILI_BOT_GH_PAT }}
|
||||
title: Upgrade dependencies
|
||||
body: |
|
||||
This issue is about updating Meilisearch dependencies:
|
||||
- [ ] Cargo toml dependencies of Meilisearch; but also the main engine-team repositories that Meilisearch depends on (charabia, heed...)
|
||||
- [ ] If new Rust versions have been released, update the Rust version in the Clippy job of this [GitHub Action file](./.github/workflows/rust.yml)
|
||||
|
||||
⚠️ To avoid last minute bugs, this issue should only be done at the beginning of the sprint!
|
||||
|
||||
The GitHub action dependencies are managed by [Dependabot](./.github/dependabot.yml)
|
||||
labels: |
|
||||
dependencies
|
||||
maintenance
|
||||
24
.github/workflows/dependency-issue.yml
vendored
Normal file
24
.github/workflows/dependency-issue.yml
vendored
Normal file
@ -0,0 +1,24 @@
|
||||
name: Create issue to upgrade dependencies
|
||||
|
||||
on:
|
||||
schedule:
|
||||
# Run the first of the month, every 3 month
|
||||
- cron: '0 0 1 */3 *'
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
create-issue:
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
ISSUE_TEMPLATE: issue-template.md
|
||||
GH_TOKEN: ${{ secrets.MEILI_BOT_GH_PAT }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Download the issue template
|
||||
run: curl -s https://raw.githubusercontent.com/meilisearch/engine-team/main/issue-templates/dependency-issue.md > $ISSUE_TEMPLATE
|
||||
- name: Create issue
|
||||
run: |
|
||||
gh issue create \
|
||||
--title 'Upgrade dependencies' \
|
||||
--label 'dependencies,maintenance' \
|
||||
--body-file $ISSUE_TEMPLATE
|
||||
@ -1,4 +1,4 @@
|
||||
name: Publish to APT repository & Homebrew
|
||||
name: Publish to APT & Homebrew
|
||||
|
||||
on:
|
||||
release:
|
||||
@ -35,7 +35,7 @@ jobs:
|
||||
- name: Build deb package
|
||||
run: cargo deb -p meilisearch -o target/debian/meilisearch.deb
|
||||
- name: Upload debian pkg to release
|
||||
uses: svenstaro/upload-release-action@2.4.0
|
||||
uses: svenstaro/upload-release-action@2.5.0
|
||||
with:
|
||||
repo_token: ${{ secrets.MEILI_BOT_GH_PAT }}
|
||||
file: target/debian/meilisearch.deb
|
||||
12
.github/workflows/publish-binaries.yml
vendored
12
.github/workflows/publish-binaries.yml
vendored
@ -1,3 +1,5 @@
|
||||
name: Publish binaries to GitHub release
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
@ -5,8 +7,6 @@ on:
|
||||
release:
|
||||
types: [published]
|
||||
|
||||
name: Publish binaries to release
|
||||
|
||||
jobs:
|
||||
check-version:
|
||||
name: Check the version validity
|
||||
@ -54,7 +54,7 @@ jobs:
|
||||
# No need to upload binaries for dry run (cron)
|
||||
- name: Upload binaries to release
|
||||
if: github.event_name == 'release'
|
||||
uses: svenstaro/upload-release-action@2.4.0
|
||||
uses: svenstaro/upload-release-action@2.5.0
|
||||
with:
|
||||
repo_token: ${{ secrets.MEILI_BOT_GH_PAT }}
|
||||
file: target/release/meilisearch
|
||||
@ -87,7 +87,7 @@ jobs:
|
||||
# No need to upload binaries for dry run (cron)
|
||||
- name: Upload binaries to release
|
||||
if: github.event_name == 'release'
|
||||
uses: svenstaro/upload-release-action@2.4.0
|
||||
uses: svenstaro/upload-release-action@2.5.0
|
||||
with:
|
||||
repo_token: ${{ secrets.MEILI_BOT_GH_PAT }}
|
||||
file: target/release/${{ matrix.artifact_name }}
|
||||
@ -121,7 +121,7 @@ jobs:
|
||||
- name: Upload the binary to release
|
||||
# No need to upload binaries for dry run (cron)
|
||||
if: github.event_name == 'release'
|
||||
uses: svenstaro/upload-release-action@2.4.0
|
||||
uses: svenstaro/upload-release-action@2.5.0
|
||||
with:
|
||||
repo_token: ${{ secrets.MEILI_BOT_GH_PAT }}
|
||||
file: target/${{ matrix.target }}/release/meilisearch
|
||||
@ -183,7 +183,7 @@ jobs:
|
||||
- name: Upload the binary to release
|
||||
# No need to upload binaries for dry run (cron)
|
||||
if: github.event_name == 'release'
|
||||
uses: svenstaro/upload-release-action@2.4.0
|
||||
uses: svenstaro/upload-release-action@2.5.0
|
||||
with:
|
||||
repo_token: ${{ secrets.MEILI_BOT_GH_PAT }}
|
||||
file: target/${{ matrix.target }}/release/meilisearch
|
||||
|
||||
5
.github/workflows/publish-docker-images.yml
vendored
5
.github/workflows/publish-docker-images.yml
vendored
@ -1,4 +1,5 @@
|
||||
---
|
||||
name: Publish images to Docker Hub
|
||||
|
||||
on:
|
||||
push:
|
||||
# Will run for every tag pushed except `latest`
|
||||
@ -12,8 +13,6 @@ on:
|
||||
- cron: '0 23 * * *' # Every day at 11:00pm
|
||||
workflow_dispatch:
|
||||
|
||||
name: Publish tagged images to Docker Hub
|
||||
|
||||
jobs:
|
||||
docker:
|
||||
runs-on: docker
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
name: Rust
|
||||
name: Test suite
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
@ -25,36 +25,35 @@ jobs:
|
||||
# Use ubuntu-18.04 to compile with glibc 2.27, which are the production expectations
|
||||
image: ubuntu:18.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Install needed dependencies
|
||||
run: |
|
||||
apt-get update && apt-get install -y curl
|
||||
apt-get install build-essential -y
|
||||
- name: Run test with Rust stable
|
||||
if: github.event_name != 'schedule'
|
||||
uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
toolchain: stable
|
||||
override: true
|
||||
- name: Run test with Rust nightly
|
||||
if: github.event_name == 'schedule'
|
||||
uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
toolchain: nightly
|
||||
override: true
|
||||
# Disable cache due to disk space issues with Windows workers in CI
|
||||
# - name: Cache dependencies
|
||||
# uses: Swatinem/rust-cache@v2.2.0
|
||||
- name: Run cargo check without any default features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --locked --release --no-default-features --all
|
||||
- name: Run cargo test
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --locked --release --all
|
||||
- uses: actions/checkout@v3
|
||||
- name: Install needed dependencies
|
||||
run: |
|
||||
apt-get update && apt-get install -y curl
|
||||
apt-get install build-essential -y
|
||||
- name: Run test with Rust stable
|
||||
if: github.event_name != 'schedule'
|
||||
uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
toolchain: stable
|
||||
override: true
|
||||
- name: Run test with Rust nightly
|
||||
if: github.event_name == 'schedule'
|
||||
uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
toolchain: nightly
|
||||
override: true
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo check without any default features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --locked --release --no-default-features --all
|
||||
- name: Run cargo test
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --locked --release --all
|
||||
|
||||
test-others:
|
||||
name: Tests on ${{ matrix.os }}
|
||||
@ -64,19 +63,47 @@ jobs:
|
||||
matrix:
|
||||
os: [macos-12, windows-2022]
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
# - name: Cache dependencies
|
||||
# uses: Swatinem/rust-cache@v2.2.0
|
||||
- name: Run cargo check without any default features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --locked --release --no-default-features --all
|
||||
- name: Run cargo test
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --locked --release --all
|
||||
- uses: actions/checkout@v3
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo check without any default features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --locked --release --no-default-features --all
|
||||
- name: Run cargo test
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --locked --release --all
|
||||
|
||||
test-all-features:
|
||||
name: Tests all features on cron schedule only
|
||||
runs-on: ubuntu-latest
|
||||
container:
|
||||
# Use ubuntu-18.04 to compile with glibc 2.27, which are the production expectations
|
||||
image: ubuntu:18.04
|
||||
if: github.event_name == 'schedule'
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Install needed dependencies
|
||||
run: |
|
||||
apt-get update
|
||||
apt-get install --assume-yes build-essential curl
|
||||
- uses: actions-rs/toolchain@v1
|
||||
with:
|
||||
toolchain: stable
|
||||
override: true
|
||||
- name: Run cargo build with all features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: build
|
||||
args: --workspace --locked --release --all-features
|
||||
- name: Run cargo test with all features
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
command: test
|
||||
args: --workspace --locked --release --all-features
|
||||
|
||||
# We run tests in debug also, to make sure that the debug_assertions are hit
|
||||
test-debug:
|
||||
@ -95,8 +122,8 @@ jobs:
|
||||
with:
|
||||
toolchain: stable
|
||||
override: true
|
||||
# - name: Cache dependencies
|
||||
# uses: Swatinem/rust-cache@v2.2.0
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run tests in debug
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
@ -114,8 +141,8 @@ jobs:
|
||||
toolchain: 1.67.0
|
||||
override: true
|
||||
components: clippy
|
||||
# - name: Cache dependencies
|
||||
# uses: Swatinem/rust-cache@v2.2.0
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo clippy
|
||||
uses: actions-rs/cargo@v1
|
||||
with:
|
||||
@ -134,8 +161,8 @@ jobs:
|
||||
toolchain: nightly
|
||||
override: true
|
||||
components: rustfmt
|
||||
# - name: Cache dependencies
|
||||
# uses: Swatinem/rust-cache@v2.2.0
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
- name: Run cargo fmt
|
||||
# Since we never ran the `build.rs` script in the benchmark directory we are missing one auto-generated import file.
|
||||
# Since we want to trigger (and fail) this action as fast as possible, instead of building the benchmark crate
|
||||
6
.github/workflows/uffizzi-build.yml
vendored
6
.github/workflows/uffizzi-build.yml
vendored
@ -23,7 +23,7 @@ jobs:
|
||||
target: x86_64-unknown-linux-musl
|
||||
|
||||
- name: Cache dependencies
|
||||
uses: Swatinem/rust-cache@v2.2.0
|
||||
uses: Swatinem/rust-cache@v2.2.1
|
||||
|
||||
- name: Run cargo check without any default features
|
||||
uses: actions-rs/cargo@v1
|
||||
@ -46,14 +46,14 @@ jobs:
|
||||
|
||||
- name: Docker metadata
|
||||
id: meta
|
||||
uses: docker/metadata-action@v3
|
||||
uses: docker/metadata-action@v4
|
||||
with:
|
||||
images: registry.uffizzi.com/${{ env.UUID_TAG }}
|
||||
tags: |
|
||||
type=raw,value=60d
|
||||
|
||||
- name: Build Image
|
||||
uses: docker/build-push-action@v3
|
||||
uses: docker/build-push-action@v4
|
||||
with:
|
||||
context: ./
|
||||
file: .github/uffizzi/Dockerfile
|
||||
|
||||
@ -159,7 +159,7 @@ impl<'a> Display for Error<'a> {
|
||||
writeln!(f, "The `_geoBoundingBox` filter expects two pairs of arguments: `_geoBoundingBox([latitude, longitude], [latitude, longitude])`.")?
|
||||
}
|
||||
ErrorKind::ReservedGeo(name) => {
|
||||
writeln!(f, "`{}` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance), or _geoBoundingBox([latitude, longitude], [latitude, longitude]) built-in rules to filter on `_geo` coordinates.", name.escape_debug())?
|
||||
writeln!(f, "`{}` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.", name.escape_debug())?
|
||||
}
|
||||
ErrorKind::MisusedGeoRadius => {
|
||||
writeln!(f, "The `_geoRadius` filter is an operation and can't be used as a value.")?
|
||||
|
||||
@ -382,6 +382,34 @@ fn parse_geo_point(input: Span) -> IResult<FilterCondition> {
|
||||
Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::ReservedGeo("_geoPoint"))))
|
||||
}
|
||||
|
||||
/// geoPoint = WS* "_geoDistance(float WS* "," WS* float WS* "," WS* float)
|
||||
fn parse_geo_distance(input: Span) -> IResult<FilterCondition> {
|
||||
// we want to forbid space BEFORE the _geoDistance but not after
|
||||
tuple((
|
||||
multispace0,
|
||||
tag("_geoDistance"),
|
||||
// if we were able to parse `_geoDistance` we are going to return a Failure whatever happens next.
|
||||
cut(delimited(char('('), separated_list1(tag(","), ws(recognize_float)), char(')'))),
|
||||
))(input)
|
||||
.map_err(|e| e.map(|_| Error::new_from_kind(input, ErrorKind::ReservedGeo("_geoDistance"))))?;
|
||||
// if we succeeded we still return a `Failure` because `geoDistance` filters are not allowed
|
||||
Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::ReservedGeo("_geoDistance"))))
|
||||
}
|
||||
|
||||
/// geo = WS* "_geo(float WS* "," WS* float WS* "," WS* float)
|
||||
fn parse_geo(input: Span) -> IResult<FilterCondition> {
|
||||
// we want to forbid space BEFORE the _geo but not after
|
||||
tuple((
|
||||
multispace0,
|
||||
word_exact("_geo"),
|
||||
// if we were able to parse `_geo` we are going to return a Failure whatever happens next.
|
||||
cut(delimited(char('('), separated_list1(tag(","), ws(recognize_float)), char(')'))),
|
||||
))(input)
|
||||
.map_err(|e| e.map(|_| Error::new_from_kind(input, ErrorKind::ReservedGeo("_geo"))))?;
|
||||
// if we succeeded we still return a `Failure` because `_geo` filter is not allowed
|
||||
Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::ReservedGeo("_geo"))))
|
||||
}
|
||||
|
||||
fn parse_error_reserved_keyword(input: Span) -> IResult<FilterCondition> {
|
||||
match parse_condition(input) {
|
||||
Ok(result) => Ok(result),
|
||||
@ -418,6 +446,8 @@ fn parse_primary(input: Span, depth: usize) -> IResult<FilterCondition> {
|
||||
parse_not_exists,
|
||||
parse_to,
|
||||
// the next lines are only for error handling and are written at the end to have the less possible performance impact
|
||||
parse_geo,
|
||||
parse_geo_distance,
|
||||
parse_geo_point,
|
||||
parse_error_reserved_keyword,
|
||||
))(input)
|
||||
@ -621,15 +651,35 @@ pub mod tests {
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("_geoPoint(12, 13, 14)"), @r###"
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance), or _geoBoundingBox([latitude, longitude], [latitude, longitude]) built-in rules to filter on `_geo` coordinates.
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
1:22 _geoPoint(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geoPoint(12, 13, 14)"), @r###"
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance), or _geoBoundingBox([latitude, longitude], [latitude, longitude]) built-in rules to filter on `_geo` coordinates.
|
||||
`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
13:34 position <= _geoPoint(12, 13, 14)
|
||||
"###);
|
||||
|
||||
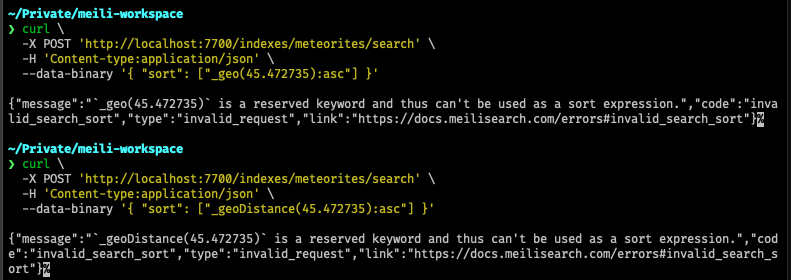
insta::assert_display_snapshot!(p("_geoDistance(12, 13, 14)"), @r###"
|
||||
`_geoDistance` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
1:25 _geoDistance(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geoDistance(12, 13, 14)"), @r###"
|
||||
`_geoDistance` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
13:37 position <= _geoDistance(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("_geo(12, 13, 14)"), @r###"
|
||||
`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
1:17 _geo(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geo(12, 13, 14)"), @r###"
|
||||
`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.
|
||||
13:29 position <= _geo(12, 13, 14)
|
||||
"###);
|
||||
|
||||
insta::assert_display_snapshot!(p("position <= _geoRadius(12, 13, 14)"), @r###"
|
||||
The `_geoRadius` filter is an operation and can't be used as a value.
|
||||
13:35 position <= _geoRadius(12, 13, 14)
|
||||
|
||||
@ -7,8 +7,8 @@ use nom::{InputIter, InputLength, InputTake, Slice};
|
||||
|
||||
use crate::error::{ExpectedValueKind, NomErrorExt};
|
||||
use crate::{
|
||||
parse_geo_bounding_box, parse_geo_point, parse_geo_radius, Error, ErrorKind, IResult, Span,
|
||||
Token,
|
||||
parse_geo, parse_geo_bounding_box, parse_geo_distance, parse_geo_point, parse_geo_radius,
|
||||
Error, ErrorKind, IResult, Span, Token,
|
||||
};
|
||||
|
||||
/// This function goes through all characters in the [Span] if it finds any escaped character (`\`).
|
||||
@ -88,11 +88,16 @@ pub fn parse_value(input: Span) -> IResult<Token> {
|
||||
// then, we want to check if the user is misusing a geo expression
|
||||
// This expression can’t finish without error.
|
||||
// We want to return an error in case of failure.
|
||||
if let Err(err) = parse_geo_point(input) {
|
||||
if err.is_failure() {
|
||||
return Err(err);
|
||||
let geo_reserved_parse_functions = [parse_geo_point, parse_geo_distance, parse_geo];
|
||||
|
||||
for parser in geo_reserved_parse_functions {
|
||||
if let Err(err) = parser(input) {
|
||||
if err.is_failure() {
|
||||
return Err(err);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
match parse_geo_radius(input) {
|
||||
Ok(_) => {
|
||||
return Err(nom::Err::Failure(Error::new_from_kind(input, ErrorKind::MisusedGeoRadius)))
|
||||
|
||||
@ -61,6 +61,8 @@ pub enum Error {
|
||||
SwapDuplicateIndexesFound(Vec<String>),
|
||||
#[error("Index `{0}` not found.")]
|
||||
SwapIndexNotFound(String),
|
||||
#[error("No space left in database. Free some space by deleting tasks.")]
|
||||
NoSpaceLeftInTaskQueue,
|
||||
#[error(
|
||||
"Indexes {} not found.",
|
||||
.0.iter().map(|s| format!("`{}`", s)).collect::<Vec<_>>().join(", ")
|
||||
@ -152,6 +154,8 @@ impl ErrorCode for Error {
|
||||
Error::TaskNotFound(_) => Code::TaskNotFound,
|
||||
Error::TaskDeletionWithEmptyQuery => Code::MissingTaskFilters,
|
||||
Error::TaskCancelationWithEmptyQuery => Code::MissingTaskFilters,
|
||||
// TODO: not sure of the Code to use
|
||||
Error::NoSpaceLeftInTaskQueue => Code::NoSpaceLeftOnDevice,
|
||||
Error::Dump(e) => e.error_code(),
|
||||
Error::Milli(e) => e.error_code(),
|
||||
Error::ProcessBatchPanicked => Code::Internal,
|
||||
|
||||
@ -31,6 +31,7 @@ mod uuid_codec;
|
||||
pub type Result<T> = std::result::Result<T, Error>;
|
||||
pub type TaskId = u32;
|
||||
|
||||
use std::collections::HashMap;
|
||||
use std::ops::{Bound, RangeBounds};
|
||||
use std::path::{Path, PathBuf};
|
||||
use std::sync::atomic::AtomicBool;
|
||||
@ -43,7 +44,7 @@ pub use error::Error;
|
||||
use file_store::FileStore;
|
||||
use meilisearch_types::error::ResponseError;
|
||||
use meilisearch_types::heed::types::{OwnedType, SerdeBincode, SerdeJson, Str};
|
||||
use meilisearch_types::heed::{self, Database, Env, RoTxn};
|
||||
use meilisearch_types::heed::{self, Database, Env, RoTxn, RwTxn};
|
||||
use meilisearch_types::milli::documents::DocumentsBatchBuilder;
|
||||
use meilisearch_types::milli::update::IndexerConfig;
|
||||
use meilisearch_types::milli::{self, CboRoaringBitmapCodec, Index, RoaringBitmapCodec, BEU32};
|
||||
@ -820,6 +821,13 @@ impl IndexScheduler {
|
||||
pub fn register(&self, kind: KindWithContent) -> Result<Task> {
|
||||
let mut wtxn = self.env.write_txn()?;
|
||||
|
||||
// if the task doesn't delete anything and 90% of the task queue is full, we must refuse to enqueue the incomming task
|
||||
if !matches!(&kind, KindWithContent::TaskDeletion { tasks, .. } if !tasks.is_empty())
|
||||
&& (self.env.real_disk_size()? * 100) / self.env.map_size()? as u64 > 90
|
||||
{
|
||||
return Err(Error::NoSpaceLeftInTaskQueue);
|
||||
}
|
||||
|
||||
let mut task = Task {
|
||||
uid: self.next_task_id(&wtxn)?,
|
||||
enqueued_at: OffsetDateTime::now_utc(),
|
||||
@ -882,127 +890,8 @@ impl IndexScheduler {
|
||||
|
||||
/// Register a new task coming from a dump in the scheduler.
|
||||
/// By taking a mutable ref we're pretty sure no one will ever import a dump while actix is running.
|
||||
pub fn register_dumped_task(
|
||||
&mut self,
|
||||
task: TaskDump,
|
||||
content_file: Option<Box<UpdateFile>>,
|
||||
) -> Result<Task> {
|
||||
// Currently we don't need to access the tasks queue while loading a dump thus I can block everything.
|
||||
let mut wtxn = self.env.write_txn()?;
|
||||
|
||||
let content_uuid = match content_file {
|
||||
Some(content_file) if task.status == Status::Enqueued => {
|
||||
let (uuid, mut file) = self.create_update_file()?;
|
||||
let mut builder = DocumentsBatchBuilder::new(file.as_file_mut());
|
||||
for doc in content_file {
|
||||
builder.append_json_object(&doc?)?;
|
||||
}
|
||||
builder.into_inner()?;
|
||||
file.persist()?;
|
||||
|
||||
Some(uuid)
|
||||
}
|
||||
// If the task isn't `Enqueued` then just generate a recognisable `Uuid`
|
||||
// in case we try to open it later.
|
||||
_ if task.status != Status::Enqueued => Some(Uuid::nil()),
|
||||
_ => None,
|
||||
};
|
||||
|
||||
let task = Task {
|
||||
uid: task.uid,
|
||||
enqueued_at: task.enqueued_at,
|
||||
started_at: task.started_at,
|
||||
finished_at: task.finished_at,
|
||||
error: task.error,
|
||||
canceled_by: task.canceled_by,
|
||||
details: task.details,
|
||||
status: task.status,
|
||||
kind: match task.kind {
|
||||
KindDump::DocumentImport {
|
||||
primary_key,
|
||||
method,
|
||||
documents_count,
|
||||
allow_index_creation,
|
||||
} => KindWithContent::DocumentAdditionOrUpdate {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
primary_key,
|
||||
method,
|
||||
content_file: content_uuid.ok_or(Error::CorruptedDump)?,
|
||||
documents_count,
|
||||
allow_index_creation,
|
||||
},
|
||||
KindDump::DocumentDeletion { documents_ids } => KindWithContent::DocumentDeletion {
|
||||
documents_ids,
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
},
|
||||
KindDump::DocumentClear => KindWithContent::DocumentClear {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
},
|
||||
KindDump::Settings { settings, is_deletion, allow_index_creation } => {
|
||||
KindWithContent::SettingsUpdate {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
new_settings: settings,
|
||||
is_deletion,
|
||||
allow_index_creation,
|
||||
}
|
||||
}
|
||||
KindDump::IndexDeletion => KindWithContent::IndexDeletion {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
},
|
||||
KindDump::IndexCreation { primary_key } => KindWithContent::IndexCreation {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
primary_key,
|
||||
},
|
||||
KindDump::IndexUpdate { primary_key } => KindWithContent::IndexUpdate {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
primary_key,
|
||||
},
|
||||
KindDump::IndexSwap { swaps } => KindWithContent::IndexSwap { swaps },
|
||||
KindDump::TaskCancelation { query, tasks } => {
|
||||
KindWithContent::TaskCancelation { query, tasks }
|
||||
}
|
||||
KindDump::TasksDeletion { query, tasks } => {
|
||||
KindWithContent::TaskDeletion { query, tasks }
|
||||
}
|
||||
KindDump::DumpCreation { keys, instance_uid } => {
|
||||
KindWithContent::DumpCreation { keys, instance_uid }
|
||||
}
|
||||
KindDump::SnapshotCreation => KindWithContent::SnapshotCreation,
|
||||
},
|
||||
};
|
||||
|
||||
self.all_tasks.put(&mut wtxn, &BEU32::new(task.uid), &task)?;
|
||||
|
||||
for index in task.indexes() {
|
||||
self.update_index(&mut wtxn, index, |bitmap| {
|
||||
bitmap.insert(task.uid);
|
||||
})?;
|
||||
}
|
||||
|
||||
self.update_status(&mut wtxn, task.status, |bitmap| {
|
||||
bitmap.insert(task.uid);
|
||||
})?;
|
||||
|
||||
self.update_kind(&mut wtxn, task.kind.as_kind(), |bitmap| {
|
||||
(bitmap.insert(task.uid));
|
||||
})?;
|
||||
|
||||
utils::insert_task_datetime(&mut wtxn, self.enqueued_at, task.enqueued_at, task.uid)?;
|
||||
|
||||
// we can't override the started_at & finished_at, so we must only set it if the tasks is finished and won't change
|
||||
if matches!(task.status, Status::Succeeded | Status::Failed | Status::Canceled) {
|
||||
if let Some(started_at) = task.started_at {
|
||||
utils::insert_task_datetime(&mut wtxn, self.started_at, started_at, task.uid)?;
|
||||
}
|
||||
if let Some(finished_at) = task.finished_at {
|
||||
utils::insert_task_datetime(&mut wtxn, self.finished_at, finished_at, task.uid)?;
|
||||
}
|
||||
}
|
||||
|
||||
wtxn.commit()?;
|
||||
self.wake_up.signal();
|
||||
|
||||
Ok(task)
|
||||
pub fn register_dumped_task(&mut self) -> Result<Dump> {
|
||||
Dump::new(self)
|
||||
}
|
||||
|
||||
/// Create a new index without any associated task.
|
||||
@ -1237,6 +1126,184 @@ impl IndexScheduler {
|
||||
}
|
||||
}
|
||||
|
||||
pub struct Dump<'a> {
|
||||
index_scheduler: &'a IndexScheduler,
|
||||
wtxn: RwTxn<'a, 'a>,
|
||||
|
||||
indexes: HashMap<String, RoaringBitmap>,
|
||||
statuses: HashMap<Status, RoaringBitmap>,
|
||||
kinds: HashMap<Kind, RoaringBitmap>,
|
||||
}
|
||||
|
||||
impl<'a> Dump<'a> {
|
||||
pub(crate) fn new(index_scheduler: &'a mut IndexScheduler) -> Result<Self> {
|
||||
// While loading a dump no one should be able to access the scheduler thus I can block everything.
|
||||
let wtxn = index_scheduler.env.write_txn()?;
|
||||
|
||||
Ok(Dump {
|
||||
index_scheduler,
|
||||
wtxn,
|
||||
indexes: HashMap::new(),
|
||||
statuses: HashMap::new(),
|
||||
kinds: HashMap::new(),
|
||||
})
|
||||
}
|
||||
|
||||
/// Register a new task coming from a dump in the scheduler.
|
||||
/// By taking a mutable ref we're pretty sure no one will ever import a dump while actix is running.
|
||||
pub fn register_dumped_task(
|
||||
&mut self,
|
||||
task: TaskDump,
|
||||
content_file: Option<Box<UpdateFile>>,
|
||||
) -> Result<Task> {
|
||||
let content_uuid = match content_file {
|
||||
Some(content_file) if task.status == Status::Enqueued => {
|
||||
let (uuid, mut file) = self.index_scheduler.create_update_file()?;
|
||||
let mut builder = DocumentsBatchBuilder::new(file.as_file_mut());
|
||||
for doc in content_file {
|
||||
builder.append_json_object(&doc?)?;
|
||||
}
|
||||
builder.into_inner()?;
|
||||
file.persist()?;
|
||||
|
||||
Some(uuid)
|
||||
}
|
||||
// If the task isn't `Enqueued` then just generate a recognisable `Uuid`
|
||||
// in case we try to open it later.
|
||||
_ if task.status != Status::Enqueued => Some(Uuid::nil()),
|
||||
_ => None,
|
||||
};
|
||||
|
||||
let task = Task {
|
||||
uid: task.uid,
|
||||
enqueued_at: task.enqueued_at,
|
||||
started_at: task.started_at,
|
||||
finished_at: task.finished_at,
|
||||
error: task.error,
|
||||
canceled_by: task.canceled_by,
|
||||
details: task.details,
|
||||
status: task.status,
|
||||
kind: match task.kind {
|
||||
KindDump::DocumentImport {
|
||||
primary_key,
|
||||
method,
|
||||
documents_count,
|
||||
allow_index_creation,
|
||||
} => KindWithContent::DocumentAdditionOrUpdate {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
primary_key,
|
||||
method,
|
||||
content_file: content_uuid.ok_or(Error::CorruptedDump)?,
|
||||
documents_count,
|
||||
allow_index_creation,
|
||||
},
|
||||
KindDump::DocumentDeletion { documents_ids } => KindWithContent::DocumentDeletion {
|
||||
documents_ids,
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
},
|
||||
KindDump::DocumentClear => KindWithContent::DocumentClear {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
},
|
||||
KindDump::Settings { settings, is_deletion, allow_index_creation } => {
|
||||
KindWithContent::SettingsUpdate {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
new_settings: settings,
|
||||
is_deletion,
|
||||
allow_index_creation,
|
||||
}
|
||||
}
|
||||
KindDump::IndexDeletion => KindWithContent::IndexDeletion {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
},
|
||||
KindDump::IndexCreation { primary_key } => KindWithContent::IndexCreation {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
primary_key,
|
||||
},
|
||||
KindDump::IndexUpdate { primary_key } => KindWithContent::IndexUpdate {
|
||||
index_uid: task.index_uid.ok_or(Error::CorruptedDump)?,
|
||||
primary_key,
|
||||
},
|
||||
KindDump::IndexSwap { swaps } => KindWithContent::IndexSwap { swaps },
|
||||
KindDump::TaskCancelation { query, tasks } => {
|
||||
KindWithContent::TaskCancelation { query, tasks }
|
||||
}
|
||||
KindDump::TasksDeletion { query, tasks } => {
|
||||
KindWithContent::TaskDeletion { query, tasks }
|
||||
}
|
||||
KindDump::DumpCreation { keys, instance_uid } => {
|
||||
KindWithContent::DumpCreation { keys, instance_uid }
|
||||
}
|
||||
KindDump::SnapshotCreation => KindWithContent::SnapshotCreation,
|
||||
},
|
||||
};
|
||||
|
||||
self.index_scheduler.all_tasks.put(&mut self.wtxn, &BEU32::new(task.uid), &task)?;
|
||||
|
||||
for index in task.indexes() {
|
||||
match self.indexes.get_mut(index) {
|
||||
Some(bitmap) => {
|
||||
bitmap.insert(task.uid);
|
||||
}
|
||||
None => {
|
||||
let mut bitmap = RoaringBitmap::new();
|
||||
bitmap.insert(task.uid);
|
||||
self.indexes.insert(index.to_string(), bitmap);
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
utils::insert_task_datetime(
|
||||
&mut self.wtxn,
|
||||
self.index_scheduler.enqueued_at,
|
||||
task.enqueued_at,
|
||||
task.uid,
|
||||
)?;
|
||||
|
||||
// we can't override the started_at & finished_at, so we must only set it if the tasks is finished and won't change
|
||||
if matches!(task.status, Status::Succeeded | Status::Failed | Status::Canceled) {
|
||||
if let Some(started_at) = task.started_at {
|
||||
utils::insert_task_datetime(
|
||||
&mut self.wtxn,
|
||||
self.index_scheduler.started_at,
|
||||
started_at,
|
||||
task.uid,
|
||||
)?;
|
||||
}
|
||||
if let Some(finished_at) = task.finished_at {
|
||||
utils::insert_task_datetime(
|
||||
&mut self.wtxn,
|
||||
self.index_scheduler.finished_at,
|
||||
finished_at,
|
||||
task.uid,
|
||||
)?;
|
||||
}
|
||||
}
|
||||
|
||||
self.statuses.entry(task.status).or_insert(RoaringBitmap::new()).insert(task.uid);
|
||||
self.kinds.entry(task.kind.as_kind()).or_insert(RoaringBitmap::new()).insert(task.uid);
|
||||
|
||||
Ok(task)
|
||||
}
|
||||
|
||||
/// Commit all the changes and exit the importing dump state
|
||||
pub fn finish(mut self) -> Result<()> {
|
||||
for (index, bitmap) in self.indexes {
|
||||
self.index_scheduler.index_tasks.put(&mut self.wtxn, &index, &bitmap)?;
|
||||
}
|
||||
for (status, bitmap) in self.statuses {
|
||||
self.index_scheduler.put_status(&mut self.wtxn, status, &bitmap)?;
|
||||
}
|
||||
for (kind, bitmap) in self.kinds {
|
||||
self.index_scheduler.put_kind(&mut self.wtxn, kind, &bitmap)?;
|
||||
}
|
||||
|
||||
self.wtxn.commit()?;
|
||||
self.index_scheduler.wake_up.signal();
|
||||
|
||||
Ok(())
|
||||
}
|
||||
}
|
||||
|
||||
/// The outcome of calling the [`IndexScheduler::tick`] function.
|
||||
pub enum TickOutcome {
|
||||
/// The scheduler should immediately attempt another `tick`.
|
||||
|
||||
@ -367,12 +367,14 @@ fn import_dump(
|
||||
log::info!("All documents successfully imported.");
|
||||
}
|
||||
|
||||
let mut index_scheduler_dump = index_scheduler.register_dumped_task()?;
|
||||
|
||||
// 4. Import the tasks.
|
||||
for ret in dump_reader.tasks()? {
|
||||
let (task, file) = ret?;
|
||||
index_scheduler.register_dumped_task(task, file)?;
|
||||
index_scheduler_dump.register_dumped_task(task, file)?;
|
||||
}
|
||||
Ok(())
|
||||
Ok(index_scheduler_dump.finish()?)
|
||||
}
|
||||
|
||||
pub fn configure_data(
|
||||
|
||||
@ -68,7 +68,7 @@ const DEFAULT_LOG_EVERY_N: usize = 100_000;
|
||||
// The actual size of the virtual address space is computed at startup to determine how many 2TiB indexes can be
|
||||
// opened simultaneously.
|
||||
pub const INDEX_SIZE: u64 = 2 * 1024 * 1024 * 1024 * 1024; // 2 TiB
|
||||
pub const TASK_DB_SIZE: u64 = 10 * 1024 * 1024 * 1024; // 10 GiB
|
||||
pub const TASK_DB_SIZE: u64 = 11 * 1024 * 1024 * 1024; // 11 GiB
|
||||
|
||||
#[derive(Debug, Default, Clone, Copy, Serialize, Deserialize)]
|
||||
#[serde(rename_all = "UPPERCASE")]
|
||||
|
||||
@ -279,6 +279,81 @@ async fn add_csv_document() {
|
||||
"###);
|
||||
}
|
||||
|
||||
#[actix_rt::test]
|
||||
async fn add_csv_document_with_types() {
|
||||
let server = Server::new().await;
|
||||
let index = server.index("pets");
|
||||
|
||||
let document = "#id:number,name:string,race:string,age:number,cute:boolean
|
||||
0,jean,bernese mountain,2.5,true
|
||||
1,,,,
|
||||
2,lilou,pug,-2,false";
|
||||
|
||||
let (response, code) = index.raw_update_documents(document, Some("text/csv"), "").await;
|
||||
snapshot!(code, @"202 Accepted");
|
||||
snapshot!(json_string!(response, { ".enqueuedAt" => "[date]" }), @r###"
|
||||
{
|
||||
"taskUid": 0,
|
||||
"indexUid": "pets",
|
||||
"status": "enqueued",
|
||||
"type": "documentAdditionOrUpdate",
|
||||
"enqueuedAt": "[date]"
|
||||
}
|
||||
"###);
|
||||
let response = index.wait_task(response["taskUid"].as_u64().unwrap()).await;
|
||||
snapshot!(json_string!(response, { ".enqueuedAt" => "[date]", ".startedAt" => "[date]", ".finishedAt" => "[date]", ".duration" => "[duration]" }), @r###"
|
||||
{
|
||||
"uid": 0,
|
||||
"indexUid": "pets",
|
||||
"status": "succeeded",
|
||||
"type": "documentAdditionOrUpdate",
|
||||
"canceledBy": null,
|
||||
"details": {
|
||||
"receivedDocuments": 3,
|
||||
"indexedDocuments": 3
|
||||
},
|
||||
"error": null,
|
||||
"duration": "[duration]",
|
||||
"enqueuedAt": "[date]",
|
||||
"startedAt": "[date]",
|
||||
"finishedAt": "[date]"
|
||||
}
|
||||
"###);
|
||||
|
||||
let (documents, code) = index.get_all_documents(GetAllDocumentsOptions::default()).await;
|
||||
snapshot!(code, @"200 OK");
|
||||
snapshot!(json_string!(documents), @r###"
|
||||
{
|
||||
"results": [
|
||||
{
|
||||
"#id": 0,
|
||||
"name": "jean",
|
||||
"race": "bernese mountain",
|
||||
"age": 2.5,
|
||||
"cute": true
|
||||
},
|
||||
{
|
||||
"#id": 1,
|
||||
"name": null,
|
||||
"race": null,
|
||||
"age": null,
|
||||
"cute": null
|
||||
},
|
||||
{
|
||||
"#id": 2,
|
||||
"name": "lilou",
|
||||
"race": "pug",
|
||||
"age": -2,
|
||||
"cute": false
|
||||
}
|
||||
],
|
||||
"offset": 0,
|
||||
"limit": 20,
|
||||
"total": 3
|
||||
}
|
||||
"###);
|
||||
}
|
||||
|
||||
#[actix_rt::test]
|
||||
async fn add_csv_document_with_custom_delimiter() {
|
||||
let server = Server::new().await;
|
||||
@ -343,6 +418,40 @@ async fn add_csv_document_with_custom_delimiter() {
|
||||
"###);
|
||||
}
|
||||
|
||||
#[actix_rt::test]
|
||||
async fn add_csv_document_with_types_error() {
|
||||
let server = Server::new().await;
|
||||
let index = server.index("pets");
|
||||
|
||||
let document = "#id:number,a:boolean,b:number
|
||||
0,doggo,1";
|
||||
|
||||
let (response, code) = index.raw_update_documents(document, Some("text/csv"), "").await;
|
||||
snapshot!(code, @"400 Bad Request");
|
||||
snapshot!(json_string!(response, { ".enqueuedAt" => "[date]" }), @r###"
|
||||
{
|
||||
"message": "The `csv` payload provided is malformed: `Error parsing boolean \"doggo\" at line 1: provided string was not `true` or `false``.",
|
||||
"code": "malformed_payload",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#malformed_payload"
|
||||
}
|
||||
"###);
|
||||
|
||||
let document = "#id:number,a:boolean,b:number
|
||||
0,true,doggo";
|
||||
|
||||
let (response, code) = index.raw_update_documents(document, Some("text/csv"), "").await;
|
||||
snapshot!(code, @"400 Bad Request");
|
||||
snapshot!(json_string!(response, { ".enqueuedAt" => "[date]" }), @r###"
|
||||
{
|
||||
"message": "The `csv` payload provided is malformed: `Error parsing number \"doggo\" at line 1: invalid float literal`.",
|
||||
"code": "malformed_payload",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#malformed_payload"
|
||||
}
|
||||
"###);
|
||||
}
|
||||
|
||||
/// any other content-type is must be refused
|
||||
#[actix_rt::test]
|
||||
async fn error_add_documents_test_bad_content_types() {
|
||||
|
||||
@ -1121,6 +1121,12 @@ async fn import_dump_v5() {
|
||||
assert_eq!(indexes["results"][1]["uid"], json!("test2"));
|
||||
assert_eq!(indexes["results"][0]["primaryKey"], json!("id"));
|
||||
|
||||
// before doing anything we're going to wait until all the tasks in the dump have finished processing
|
||||
let result = server.tasks_filter("statuses=enqueued,processing").await.0;
|
||||
for task in result["results"].as_array().unwrap() {
|
||||
server.wait_task(task["uid"].as_u64().unwrap()).await;
|
||||
}
|
||||
|
||||
let expected_stats = json!({
|
||||
"numberOfDocuments": 10,
|
||||
"isIndexing": false,
|
||||
|
||||
@ -672,7 +672,7 @@ async fn filter_reserved_geo_attribute_array() {
|
||||
index.wait_task(1).await;
|
||||
|
||||
let expected_response = json!({
|
||||
"message": "`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` field coordinates.\n1:5 _geo = Glass",
|
||||
"message": "`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.\n1:13 _geo = Glass",
|
||||
"code": "invalid_search_filter",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#invalid_search_filter"
|
||||
@ -697,7 +697,7 @@ async fn filter_reserved_geo_attribute_string() {
|
||||
index.wait_task(1).await;
|
||||
|
||||
let expected_response = json!({
|
||||
"message": "`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` field coordinates.\n1:5 _geo = Glass",
|
||||
"message": "`_geo` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.\n1:13 _geo = Glass",
|
||||
"code": "invalid_search_filter",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#invalid_search_filter"
|
||||
@ -722,7 +722,7 @@ async fn filter_reserved_attribute_array() {
|
||||
index.wait_task(1).await;
|
||||
|
||||
let expected_response = json!({
|
||||
"message": "`_geoDistance` is a reserved keyword and thus can't be used as a filter expression.\n1:13 _geoDistance = Glass",
|
||||
"message": "`_geoDistance` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.\n1:21 _geoDistance = Glass",
|
||||
"code": "invalid_search_filter",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#invalid_search_filter"
|
||||
@ -747,7 +747,7 @@ async fn filter_reserved_attribute_string() {
|
||||
index.wait_task(1).await;
|
||||
|
||||
let expected_response = json!({
|
||||
"message": "`_geoDistance` is a reserved keyword and thus can't be used as a filter expression.\n1:13 _geoDistance = Glass",
|
||||
"message": "`_geoDistance` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.\n1:21 _geoDistance = Glass",
|
||||
"code": "invalid_search_filter",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#invalid_search_filter"
|
||||
@ -760,6 +760,56 @@ async fn filter_reserved_attribute_string() {
|
||||
.await;
|
||||
}
|
||||
|
||||
#[actix_rt::test]
|
||||
async fn filter_reserved_geo_point_array() {
|
||||
let server = Server::new().await;
|
||||
let index = server.index("test");
|
||||
|
||||
index.update_settings(json!({"filterableAttributes": ["title"]})).await;
|
||||
|
||||
let documents = DOCUMENTS.clone();
|
||||
index.add_documents(documents, None).await;
|
||||
index.wait_task(1).await;
|
||||
|
||||
let expected_response = json!({
|
||||
"message": "`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.\n1:18 _geoPoint = Glass",
|
||||
"code": "invalid_search_filter",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#invalid_search_filter"
|
||||
});
|
||||
index
|
||||
.search(json!({"filter": ["_geoPoint = Glass"]}), |response, code| {
|
||||
assert_eq!(response, expected_response);
|
||||
assert_eq!(code, 400);
|
||||
})
|
||||
.await;
|
||||
}
|
||||
|
||||
#[actix_rt::test]
|
||||
async fn filter_reserved_geo_point_string() {
|
||||
let server = Server::new().await;
|
||||
let index = server.index("test");
|
||||
|
||||
index.update_settings(json!({"filterableAttributes": ["title"]})).await;
|
||||
|
||||
let documents = DOCUMENTS.clone();
|
||||
index.add_documents(documents, None).await;
|
||||
index.wait_task(1).await;
|
||||
|
||||
let expected_response = json!({
|
||||
"message": "`_geoPoint` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` coordinates.\n1:18 _geoPoint = Glass",
|
||||
"code": "invalid_search_filter",
|
||||
"type": "invalid_request",
|
||||
"link": "https://docs.meilisearch.com/errors#invalid_search_filter"
|
||||
});
|
||||
index
|
||||
.search(json!({"filter": "_geoPoint = Glass"}), |response, code| {
|
||||
assert_eq!(response, expected_response);
|
||||
assert_eq!(code, 400);
|
||||
})
|
||||
.await;
|
||||
}
|
||||
|
||||
#[actix_rt::test]
|
||||
async fn sort_geo_reserved_attribute() {
|
||||
let server = Server::new().await;
|
||||
|
||||
@ -1,11 +1,14 @@
|
||||
mod errors;
|
||||
|
||||
use byte_unit::{Byte, ByteUnit};
|
||||
use meili_snap::insta::assert_json_snapshot;
|
||||
use meili_snap::{json_string, snapshot};
|
||||
use serde_json::json;
|
||||
use tempfile::TempDir;
|
||||
use time::format_description::well_known::Rfc3339;
|
||||
use time::OffsetDateTime;
|
||||
|
||||
use crate::common::Server;
|
||||
use crate::common::{default_settings, Server};
|
||||
|
||||
#[actix_rt::test]
|
||||
async fn error_get_unexisting_task_status() {
|
||||
@ -1000,3 +1003,89 @@ async fn test_summarized_dump_creation() {
|
||||
}
|
||||
"###);
|
||||
}
|
||||
|
||||
#[actix_web::test]
|
||||
async fn test_task_queue_is_full() {
|
||||
let dir = TempDir::new().unwrap();
|
||||
let mut options = default_settings(dir.path());
|
||||
options.max_task_db_size = Byte::from_unit(500.0, ByteUnit::B).unwrap();
|
||||
|
||||
let server = Server::new_with_options(options).await.unwrap();
|
||||
|
||||
// the first task should be enqueued without issue
|
||||
let (result, code) = server.create_index(json!({ "uid": "doggo" })).await;
|
||||
snapshot!(code, @"202 Accepted");
|
||||
snapshot!(json_string!(result, { ".enqueuedAt" => "[date]" }), @r###"
|
||||
{
|
||||
"taskUid": 0,
|
||||
"indexUid": "doggo",
|
||||
"status": "enqueued",
|
||||
"type": "indexCreation",
|
||||
"enqueuedAt": "[date]"
|
||||
}
|
||||
"###);
|
||||
|
||||
loop {
|
||||
let (res, _code) = server.create_index(json!({ "uid": "doggo" })).await;
|
||||
if res["taskUid"] == json!(null) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
let (result, code) = server.create_index(json!({ "uid": "doggo" })).await;
|
||||
snapshot!(code, @"422 Unprocessable Entity");
|
||||
snapshot!(json_string!(result), @r###"
|
||||
{
|
||||
"message": "No space left in database. Free some space by deleting tasks.",
|
||||
"code": "no_space_left_on_device",
|
||||
"type": "system",
|
||||
"link": "https://docs.meilisearch.com/errors#no_space_left_on_device"
|
||||
}
|
||||
"###);
|
||||
|
||||
// But we should still be able to register tasks deletion IF they delete something
|
||||
let (result, code) = server.delete_tasks("uids=0").await;
|
||||
snapshot!(code, @"200 OK");
|
||||
snapshot!(json_string!(result, { ".enqueuedAt" => "[date]", ".taskUid" => "uid" }), @r###"
|
||||
{
|
||||
"taskUid": "uid",
|
||||
"indexUid": null,
|
||||
"status": "enqueued",
|
||||
"type": "taskDeletion",
|
||||
"enqueuedAt": "[date]"
|
||||
}
|
||||
"###);
|
||||
|
||||
// we're going to fill up the queue once again
|
||||
loop {
|
||||
let (res, _code) = server.create_index(json!({ "uid": "doggo" })).await;
|
||||
if res["taskUid"] == json!(null) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// But we should NOT be able to register this task because it doesn't match any tasks
|
||||
let (result, code) = server.delete_tasks("uids=0").await;
|
||||
snapshot!(code, @"422 Unprocessable Entity");
|
||||
snapshot!(json_string!(result), @r###"
|
||||
{
|
||||
"message": "No space left in database. Free some space by deleting tasks.",
|
||||
"code": "no_space_left_on_device",
|
||||
"type": "system",
|
||||
"link": "https://docs.meilisearch.com/errors#no_space_left_on_device"
|
||||
}
|
||||
"###);
|
||||
|
||||
// The deletion still works
|
||||
let (result, code) = server.delete_tasks("uids=*").await;
|
||||
snapshot!(code, @"200 OK");
|
||||
snapshot!(json_string!(result, { ".enqueuedAt" => "[date]", ".taskUid" => "uid" }), @r###"
|
||||
{
|
||||
"taskUid": "uid",
|
||||
"indexUid": null,
|
||||
"status": "enqueued",
|
||||
"type": "taskDeletion",
|
||||
"enqueuedAt": "[date]"
|
||||
}
|
||||
"###);
|
||||
}
|
||||
|
||||
@ -81,6 +81,8 @@ impl FromStr for Member {
|
||||
if is_reserved_keyword(text)
|
||||
|| text.starts_with("_geoRadius(")
|
||||
|| text.starts_with("_geoBoundingBox(")
|
||||
|| text.starts_with("_geo(")
|
||||
|| text.starts_with("_geoDistance(")
|
||||
{
|
||||
return Err(AscDescError::ReservedKeyword { name: text.to_string() })?;
|
||||
}
|
||||
@ -265,6 +267,13 @@ mod tests {
|
||||
("_geoPoint(0, -180.000001):desc", GeoError(BadGeoError::Lng(-180.000001))),
|
||||
("_geoPoint(159.256, 130):asc", GeoError(BadGeoError::Lat(159.256))),
|
||||
("_geoPoint(12, -2021):desc", GeoError(BadGeoError::Lng(-2021.))),
|
||||
("_geo(12, -2021):asc", ReservedKeyword { name: S("_geo(12, -2021)") }),
|
||||
("_geo(12, -2021):desc", ReservedKeyword { name: S("_geo(12, -2021)") }),
|
||||
("_geoDistance(12, -2021):asc", ReservedKeyword { name: S("_geoDistance(12, -2021)") }),
|
||||
(
|
||||
"_geoDistance(12, -2021):desc",
|
||||
ReservedKeyword { name: S("_geoDistance(12, -2021)") },
|
||||
),
|
||||
];
|
||||
|
||||
for (req, expected_error) in invalid_req {
|
||||
|
||||
@ -114,14 +114,15 @@ impl<W: Write> DocumentsBatchBuilder<W> {
|
||||
self.value_buffer.clear();
|
||||
|
||||
let value = &record[*i];
|
||||
let trimmed_value = value.trim();
|
||||
match type_ {
|
||||
AllowedType::Number => {
|
||||
if value.trim().is_empty() {
|
||||
if trimmed_value.is_empty() {
|
||||
to_writer(&mut self.value_buffer, &Value::Null)?;
|
||||
} else if let Ok(integer) = value.trim().parse::<i64>() {
|
||||
} else if let Ok(integer) = trimmed_value.parse::<i64>() {
|
||||
to_writer(&mut self.value_buffer, &integer)?;
|
||||
} else {
|
||||
match value.trim().parse::<f64>() {
|
||||
match trimmed_value.parse::<f64>() {
|
||||
Ok(float) => {
|
||||
to_writer(&mut self.value_buffer, &float)?;
|
||||
}
|
||||
@ -135,6 +136,24 @@ impl<W: Write> DocumentsBatchBuilder<W> {
|
||||
}
|
||||
}
|
||||
}
|
||||
AllowedType::Boolean => {
|
||||
if trimmed_value.is_empty() {
|
||||
to_writer(&mut self.value_buffer, &Value::Null)?;
|
||||
} else {
|
||||
match trimmed_value.parse::<bool>() {
|
||||
Ok(bool) => {
|
||||
to_writer(&mut self.value_buffer, &bool)?;
|
||||
}
|
||||
Err(error) => {
|
||||
return Err(Error::ParseBool {
|
||||
error,
|
||||
line,
|
||||
value: value.to_string(),
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
AllowedType::String => {
|
||||
if value.is_empty() {
|
||||
to_writer(&mut self.value_buffer, &Value::Null)?;
|
||||
@ -173,6 +192,7 @@ impl<W: Write> DocumentsBatchBuilder<W> {
|
||||
#[derive(Debug)]
|
||||
enum AllowedType {
|
||||
String,
|
||||
Boolean,
|
||||
Number,
|
||||
}
|
||||
|
||||
@ -181,6 +201,7 @@ fn parse_csv_header(header: &str) -> (&str, AllowedType) {
|
||||
match header.rsplit_once(':') {
|
||||
Some((field_name, field_type)) => match field_type {
|
||||
"string" => (field_name, AllowedType::String),
|
||||
"boolean" => (field_name, AllowedType::Boolean),
|
||||
"number" => (field_name, AllowedType::Number),
|
||||
// if the pattern isn't reconized, we keep the whole field.
|
||||
_otherwise => (header, AllowedType::String),
|
||||
|
||||
@ -3,7 +3,7 @@ mod enriched;
|
||||
mod reader;
|
||||
mod serde_impl;
|
||||
|
||||
use std::fmt::{self, Debug};
|
||||
use std::fmt::Debug;
|
||||
use std::io;
|
||||
use std::str::Utf8Error;
|
||||
|
||||
@ -87,71 +87,30 @@ impl DocumentsBatchIndex {
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug)]
|
||||
#[derive(Debug, thiserror::Error)]
|
||||
pub enum Error {
|
||||
#[error("Error parsing number {value:?} at line {line}: {error}")]
|
||||
ParseFloat { error: std::num::ParseFloatError, line: usize, value: String },
|
||||
#[error("Error parsing boolean {value:?} at line {line}: {error}")]
|
||||
ParseBool { error: std::str::ParseBoolError, line: usize, value: String },
|
||||
#[error("Invalid document addition format, missing the documents batch index.")]
|
||||
InvalidDocumentFormat,
|
||||
#[error("Invalid enriched data.")]
|
||||
InvalidEnrichedData,
|
||||
InvalidUtf8(Utf8Error),
|
||||
Csv(csv::Error),
|
||||
Json(serde_json::Error),
|
||||
#[error(transparent)]
|
||||
InvalidUtf8(#[from] Utf8Error),
|
||||
#[error(transparent)]
|
||||
Csv(#[from] csv::Error),
|
||||
#[error(transparent)]
|
||||
Json(#[from] serde_json::Error),
|
||||
#[error(transparent)]
|
||||
Serialize(serde_json::Error),
|
||||
Grenad(grenad::Error),
|
||||
Io(io::Error),
|
||||
#[error(transparent)]
|
||||
Grenad(#[from] grenad::Error),
|
||||
#[error(transparent)]
|
||||
Io(#[from] io::Error),
|
||||
}
|
||||
|
||||
impl From<csv::Error> for Error {
|
||||
fn from(e: csv::Error) -> Self {
|
||||
Self::Csv(e)
|
||||
}
|
||||
}
|
||||
|
||||
impl From<io::Error> for Error {
|
||||
fn from(other: io::Error) -> Self {
|
||||
Self::Io(other)
|
||||
}
|
||||
}
|
||||
|
||||
impl From<serde_json::Error> for Error {
|
||||
fn from(other: serde_json::Error) -> Self {
|
||||
Self::Json(other)
|
||||
}
|
||||
}
|
||||
|
||||
impl From<grenad::Error> for Error {
|
||||
fn from(other: grenad::Error) -> Self {
|
||||
Self::Grenad(other)
|
||||
}
|
||||
}
|
||||
|
||||
impl From<Utf8Error> for Error {
|
||||
fn from(other: Utf8Error) -> Self {
|
||||
Self::InvalidUtf8(other)
|
||||
}
|
||||
}
|
||||
|
||||
impl fmt::Display for Error {
|
||||
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
|
||||
match self {
|
||||
Error::ParseFloat { error, line, value } => {
|
||||
write!(f, "Error parsing number {:?} at line {}: {}", value, line, error)
|
||||
}
|
||||
Error::InvalidDocumentFormat => {
|
||||
f.write_str("Invalid document addition format, missing the documents batch index.")
|
||||
}
|
||||
Error::InvalidEnrichedData => f.write_str("Invalid enriched data."),
|
||||
Error::InvalidUtf8(e) => write!(f, "{}", e),
|
||||
Error::Io(e) => write!(f, "{}", e),
|
||||
Error::Serialize(e) => write!(f, "{}", e),
|
||||
Error::Grenad(e) => write!(f, "{}", e),
|
||||
Error::Csv(e) => write!(f, "{}", e),
|
||||
Error::Json(e) => write!(f, "{}", e),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
impl std::error::Error for Error {}
|
||||
|
||||
#[cfg(test)]
|
||||
pub fn objects_from_json_value(json: serde_json::Value) -> Vec<crate::Object> {
|
||||
let documents = match json {
|
||||
@ -274,6 +233,19 @@ mod test {
|
||||
]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn csv_types_dont_panic() {
|
||||
let csv1_content =
|
||||
"id:number,b:boolean,c,d:number\n1,,,\n2,true,doggo,2\n3,false,the best doggo,-2\n4,,\"Hello, World!\",2.5";
|
||||
let csv1 = csv::Reader::from_reader(Cursor::new(csv1_content));
|
||||
|
||||
let mut builder = DocumentsBatchBuilder::new(Vec::new());
|
||||
builder.append_csv(csv1).unwrap();
|
||||
let vector = builder.into_inner().unwrap();
|
||||
|
||||
DocumentsBatchReader::from_reader(Cursor::new(vector)).unwrap();
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn out_of_order_csv_fields() {
|
||||
let csv1_content = "id:number,b\n1,0";
|
||||
|
||||
@ -54,8 +54,6 @@ impl Display for BadGeoError {
|
||||
enum FilterError<'a> {
|
||||
AttributeNotFilterable { attribute: &'a str, filterable_fields: HashSet<String> },
|
||||
ParseGeoError(BadGeoError),
|
||||
ReservedGeo(&'a str),
|
||||
Reserved(&'a str),
|
||||
TooDeep,
|
||||
}
|
||||
impl<'a> std::error::Error for FilterError<'a> {}
|
||||
@ -96,12 +94,6 @@ impl<'a> Display for FilterError<'a> {
|
||||
"Too many filter conditions, can't process more than {} filters.",
|
||||
MAX_FILTER_DEPTH
|
||||
),
|
||||
Self::ReservedGeo(keyword) => write!(f, "`{}` is a reserved keyword and thus can't be used as a filter expression. Use the `_geoRadius(latitude, longitude, distance)` or `_geoBoundingBox([latitude, longitude], [latitude, longitude])` built-in rules to filter on `_geo` field coordinates.", keyword),
|
||||
Self::Reserved(keyword) => write!(
|
||||
f,
|
||||
"`{}` is a reserved keyword and thus can't be used as a filter expression.",
|
||||
keyword
|
||||
),
|
||||
Self::ParseGeoError(error) => write!(f, "{}", error),
|
||||
}
|
||||
}
|
||||
@ -332,23 +324,10 @@ impl<'a> Filter<'a> {
|
||||
Ok(RoaringBitmap::new())
|
||||
}
|
||||
} else {
|
||||
match fid.value() {
|
||||
attribute @ "_geo" => {
|
||||
Err(fid.as_external_error(FilterError::ReservedGeo(attribute)))?
|
||||
}
|
||||
attribute if attribute.starts_with("_geoPoint(") => {
|
||||
Err(fid.as_external_error(FilterError::ReservedGeo("_geoPoint")))?
|
||||
}
|
||||
attribute @ "_geoDistance" => {
|
||||
Err(fid.as_external_error(FilterError::Reserved(attribute)))?
|
||||
}
|
||||
attribute => {
|
||||
Err(fid.as_external_error(FilterError::AttributeNotFilterable {
|
||||
attribute,
|
||||
filterable_fields: filterable_fields.clone(),
|
||||
}))?
|
||||
}
|
||||
}
|
||||
Err(fid.as_external_error(FilterError::AttributeNotFilterable {
|
||||
attribute: fid.value(),
|
||||
filterable_fields: filterable_fields.clone(),
|
||||
}))?
|
||||
}
|
||||
}
|
||||
FilterCondition::Or(subfilters) => {
|
||||
|
||||
@ -565,8 +565,12 @@ impl<'a, 't, 'u, 'i> Settings<'a, 't, 'u, 'i> {
|
||||
self.index.put_primary_key(self.wtxn, primary_key)?;
|
||||
Ok(())
|
||||
} else {
|
||||
let primary_key = self.index.primary_key(self.wtxn)?.unwrap();
|
||||
Err(UserError::PrimaryKeyCannotBeChanged(primary_key.to_string()).into())
|
||||
let curr_primary_key = self.index.primary_key(self.wtxn)?.unwrap().to_string();
|
||||
if primary_key == &curr_primary_key {
|
||||
Ok(())
|
||||
} else {
|
||||
Err(UserError::PrimaryKeyCannotBeChanged(curr_primary_key).into())
|
||||
}
|
||||
}
|
||||
}
|
||||
Setting::Reset => {
|
||||
@ -1332,6 +1336,17 @@ mod tests {
|
||||
.unwrap();
|
||||
wtxn.commit().unwrap();
|
||||
|
||||
// Updating settings with the same primary key should do nothing
|
||||
let mut wtxn = index.write_txn().unwrap();
|
||||
index
|
||||
.update_settings_using_wtxn(&mut wtxn, |settings| {
|
||||
settings.set_primary_key(S("mykey"));
|
||||
})
|
||||
.unwrap();
|
||||
assert_eq!(index.primary_key(&wtxn).unwrap(), Some("mykey"));
|
||||
wtxn.commit().unwrap();
|
||||
|
||||
// Updating the settings with a different (or no) primary key causes an error
|
||||
let mut wtxn = index.write_txn().unwrap();
|
||||
let error = index
|
||||
.update_settings_using_wtxn(&mut wtxn, |settings| {
|
||||
|
||||
Reference in New Issue
Block a user